
一个完整的深度学习工程项目包含数据标注,数据训练,数据预测三部分,逻辑结构图和技术架构如下所示:
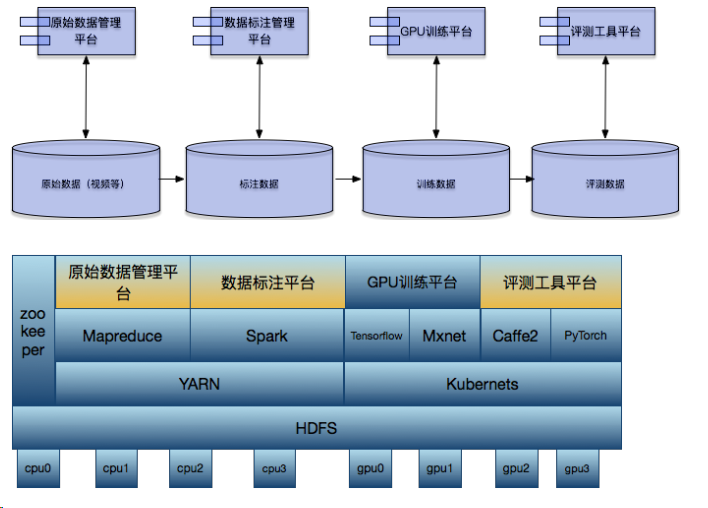
这里分别从这3个方面进行展开:
1.数据标注:包含原始数据的处理和标注,输出为训练预测可用的网络数据
2.训练任务,如图所示:

不同渠道和部门的数据最终集中在hdfs分布式存储上并通过数据标注平台产生MXNET训练需要特有的数据格式中(MR或Spark分布式计算平台 )
3.预测部分:
预测库可参考如下文章:https://www.cnblogs.com/damumu/p/7320605.html
nnvm的预测库可以自行编译获得,可以支持linux,android等平台
对于Linux平台,除了从amalgamation目录编译,也可以通过修改config.mk来编译预测库
模型的预测主要需要模型的json文件和参数文件,以及网络的输入数据。
快速测试可以用python调用预测库进行预测,没有python环境或者追求更好的性能可以编写c++程序进行预测

 浙公网安备 33010602011771号
浙公网安备 33010602011771号