
Python自然语言处理笔记【一】文本分类之监督式分类
一、分类问题
分类是为了给那些已经给定的输入选择正确的标签。
在基本的分类任务中,每个输入都被认为与其他的输入是隔离的。每个类别的标签集是预先定义好的(只有把类别划分好了,才能给输入划分类别)。
分类任务举例:
- 判断电子是否是垃圾邮件
- 从一个固定的主题领域列表里,比如有‘体育’、‘技术’、‘政治’等,来判断新闻报道的主题
- 判断给定词‘bank’的意思是指河的坡岸、金融机构、还是金融机构里的存储行为
基本分类任务:
- 多样分类:每个实例可以分配多个标签
- 开放性分类:标签集没有事先定义
- 序列分类:输入链表作为整体分类
建立在训练语料(包含了每个输入的正确标签)基础之上的分类,叫做监督式分类。
二、监督式分类
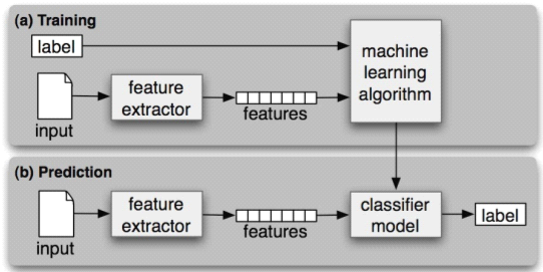
( a )在训练过程(Training)中,特征提取器(feature extractor)用来将每一个输入值(input)转换为特征集(features)。 这些特征集捕捉每个输入中应被用于对其分类的基本信息 。特征 集与标签(label)的配对被送入机器学习算法(machine learning algorithm) ,生成模型(classifier model) 。
( b )在预测过程(Prediction)中 ,相同的特征提取器被用来将未见过的输入转换为特征集。之后,这些特征集被送入模型产生预测标签。
三、分类实例(创建一个分类器)——性别鉴定
step1:决定哪些输入特征是相关的,并为这些特征编码。书中例子是通过判断名字最后一个字母,来推测性别,所以特征就在最后一个字母上。
>>> def gender_features(word):
... return {'last_letter': word[-1]}
>>> gender_features('Shrek')
{'last_letter': 'k'}
step2:利用特征提取器函数建立特征集(字典类型,关于特征名称和它们对应值的映射)
>>> from nltk.corpus import names
>>> import random
>>> names = ([(name, 'male') for name in names.words('male.txt')] +
... [(name, 'female') for name in names.words('female.txt')])
>>> random.shuffle(names)
step3:用特征提取器处理数据(文中用的是names数据),并把特征集的结果链表,划分为训练集和测试集。(训练集用于训练新的朴素贝叶斯分类器)
>>> featuresets = [(gender_features(n), g) for (n,g) in names] >>> train_set, test_set = featuresets[500:], featuresets[:500] >>> classifier = nltk.NaiveBayesClassifier.train(train_set)
step4:测试,检查
#利用大量未见过的数据来评估这个分类器 >>> print nltk.classify.accuracy(classifier, test_set)
#检查分类器,确定哪些特征对于区分名字的性别是最有效的。 >>> classifier.show_most_informative_features(5)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号