
Python爬虫与一汽项目【二】爬取中国东方电气集中采购平台
网站地址:https://srm.dongfang.com/bid_detail.screen
东方电气采购的页面看似很友好,实际上并不好爬取
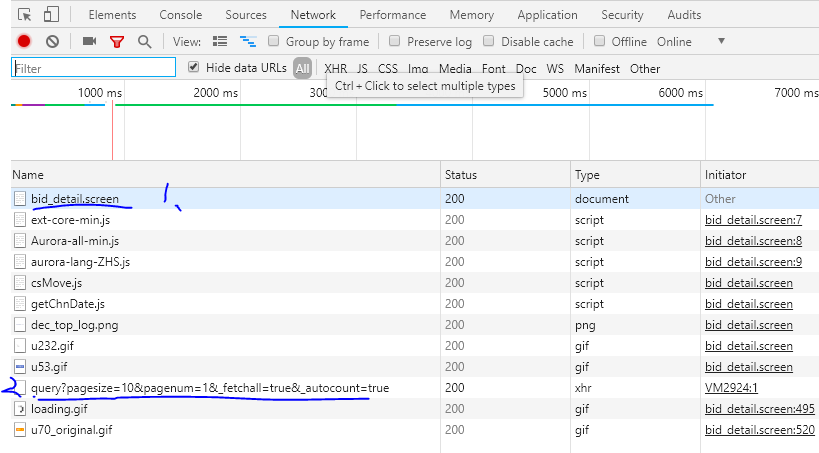
在观察网页的审查元素之后发现,1处的网页响应只是单纯的一些js代码,并没有我们想要的数据信息,因此很明显该网页是经过js修饰的
另外再翻页时,发现该网页的url始终不变,所以这是一个以post方式提交的页面。
果断转向2出的url,点开之后可以看到,
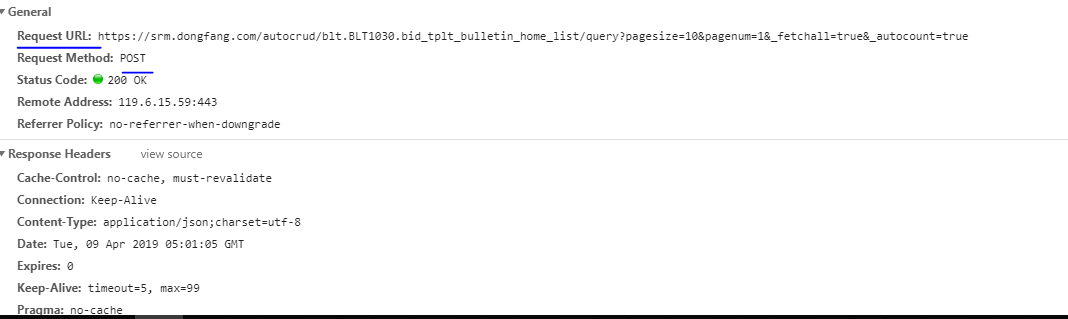
此处有一新的url,并且请求方式的确四post方式,因此不能直接用网站地址获取我们所需的数据。

查看新的url的响应发现,得到的是一串非常长的字典,而经过观察发现,我们所需要的时间,标题,二级页面的参数等内容均在字典中
因此,采取的方式的为
通过新的url获取网页响应的内容—>通过解析json数据,获取Python可读的数据—>从得到的字典中获取所求的数据
代码如下:
from urllib.request import urlopen
url = "https://srm.dongfang.com/autocrud/blt.BLT1030.bid_tplt_bulletin_home_list/query?pagesize=10&pagenum=2&_fetchall=true&_autocount=true"
urlObj = urlopen(url)
# 服务端返回的页面信息, 此处为字符串类型
pageContent = urlObj.read().decode('utf-8')
# print(pageContent)
# print(type(pageContent))
# 2. 处理Json数据
import json
# 解码: 将json数据格式解码为python可以识别的对象;
dict_data = json.loads(pageContent)
# print(type(dict_data))
# print(data['release_date'],data['bid_project_name'],data['tplt_blt_id'])
k = 0#查看信息条数
for i in dict_data['result']['record']:
print(i['creation_date'],i['bid_project_name'],i['tplt_blt_id'])
k = k+1
print(k)
这里获得了发布时间['creation_date'],招标项目名['bid_project_name'],二级页面参数['tplt_blt_id']
这里说明一下,响应的数据的格式
响应的数据是个字典嵌套了字典,大字典的第一个key值是"result",它的value值是一个小字典,
该小字典的key值是"record",而小字典的value值是一个列表,列表中保存了我们需要的信息,
而列表元素同样是个字典的形式,每个字典对应着一个招标信息的具体信息
因此采用for循环,将小字典中的值依次取出来
{"result":{"record":[{"created_by":1329210,...},{...},...],"totalCount":5265},"success":true}
输出:
2019-04-08 17:34:08 2019年年度防堵取样装置框架合同 72084 2019-04-09 09:17:15 【电机事业部】2D-HD199001-1~2-12东丰中众泰德110MW发电机配套励磁系统采购 72110 2019-04-04 09:42:03 ZB(ZK)2019069-文昌项目仪表阀(项目) 71870 2019-04-08 08:48:51 物资保障部国电九江改造凹凸法兰毛坯采购 71990 2019-04-09 08:35:02 进口铣刀及铣刀片采购(住友) 72092 2019-04-09 08:48:49 中广核河南永城项目自动润滑系统 72098 ...
本以为获取到这儿就可以直接拼接二级页面的url获取内容了,谁知道它连二级页面都是个这样的形式,可给我无语了......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号