


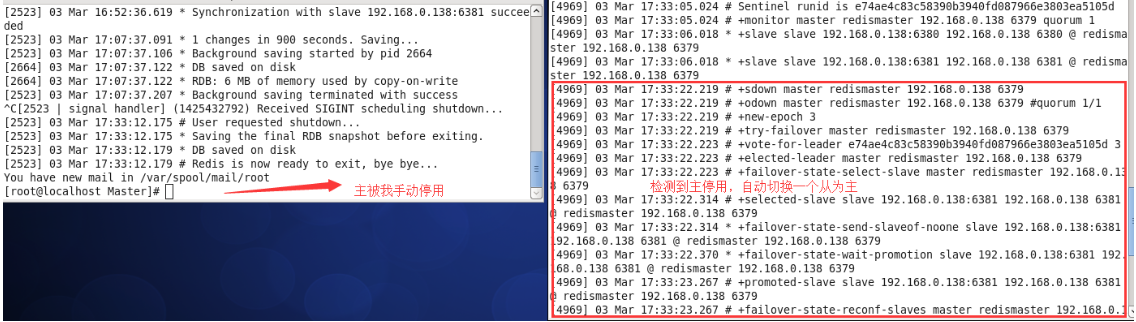
Redis主从监控,故障自动切换
1、首先下载编译安装redis
$ wget http://download.redis.io/releases/redis-2.8.19.tar.gz
$ tar xzf redis-2.8.19.tar.gz
$ cd redis-2.8.19
$ make PREFIX=/usr/local/redis install
PREFIX=/usr/local/redis make
PREFIX=/usr/local/redis make install
搭建的架构是 一主(Master)两从(Slave1,Slave2)
将编译好的redis-2.8.19里文件分别拷贝三份到目录Master、Slave1、Slave2、Sentinel1

$ bin/redis-server conf/master.conf
$ bin/redis-server conf/slave1.conf
$ bin/redis-server conf/slave2.conf


Redis集群

#redismaster是Master的名称,192.168.0.138是Master的Ip,1表示确认一个Master为O_DOWN最少需要多少个哨兵认可
sentinel monitor redismaster 192.168.0.138 6379 1
#多少秒(默认30秒)后Maste不可用被确认为S_DOWN状态
sentinel down-after-milliseconds redismaster 10000
sentinel config-epoch redismaster 3
sentinel leader-epoch redismaster 3
# cd /usr/local/redis/
# bin/redis-server mysentinel.conf --sentinel

#redismaster是Master的名称,192.168.0.138是Master的Ip,1表示确认一个Master为O_DOWN最少需要多少个哨兵认可
sentinel monitor redismaster 192.168.0.138 6381 1
#多少秒(默认30秒)后Maste不可用被确认为S_DOWN状态
sentinel down-after-milliseconds redismaster 10000
sentinel config-epoch redismaster 3
sentinel leader-epoch redismaster 3
# Generated by CONFIG REWRITE
port 26379
sentinel known-slave redismaster 192.168.0.138 6380
sentinel known-slave redismaster 192.168.0.138 6379
sentinel current-epoch 3

redis.default.db=5 #链接数据库,默认为0
redis.timeout=100000 #客户端超时时间单位是毫秒
redis.maxActive=10000 #最大连接数
redis.maxIdle=100 #最大空闲数
redis.maxWait=1000 #最大建立连接等待时间
redis.testOnBorrow=true #指明是否在从池中取出连接前进行检验,如果检验失败,则从池中去除连接并尝试取出另一个
<!-- jedis pool配置 --> <bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig"> <property name="maxTotal" value="${redis.maxActive}" /> <property name="maxIdle" value="${redis.maxIdle}" /> <property name="maxWaitMillis" value="${redis.maxWait}" /> <!-- 向调用者输出“链接”资源时,是否检测是有有效,如果无效则从连接池中移除,并尝试获取继续获取。设为true,一个挂都不能用 --> <property name="testOnBorrow" value="${redis.testOnBorrow}" /> <!-- 向连接池“归还”链接时,是否检测“链接”对象的有效性。 --> <property name="testOnReturn" value="true" /> </bean> <bean id="jedisPool" class="redis.clients.jedis.JedisSentinelPool"> <constructor-arg index="0" value="redismaster" /> <constructor-arg index="1"> <set> <value>192.168.0.138:26379</value><!--配置了一个哨兵 --> </set> </constructor-arg> <constructor-arg index="2" ref="jedisPoolConfig" /> <constructor-arg index="3" value="${redis.timeout}" /> <constructor-arg index="4"><null/></constructor-arg> <constructor-arg index="5" value="${redis.default.db}" /> </bean>
ApplicationContext ac = new ClassPathXmlApplicationContext("applicationContext-redis.xml"); JedisSentinelPool pool = (JedisSentinelPool) ac.getBean("jedisPool"); Jedis jedis = null; try { jedis = pool.getResource(); jedis.hset("max", "zheng", "hello"); } catch (JedisException je) { throw je; } finally { if (jedis != null) pool.returnResource(jedis); }
redis主从复制原理
Redis持久化保证了即使redis服务重启也不会丢失数据,因为redis服务重启后会将硬盘上持久化的数据恢复到内存中,但是当redis服务器的硬盘损坏了可能会导致数据丢失,如果通过redis的主从复制机制就可以避免这种单点故障。
Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构:Redis主从复制可以根据是否是全量分为全量同步和增量同步。下图为级联结构:
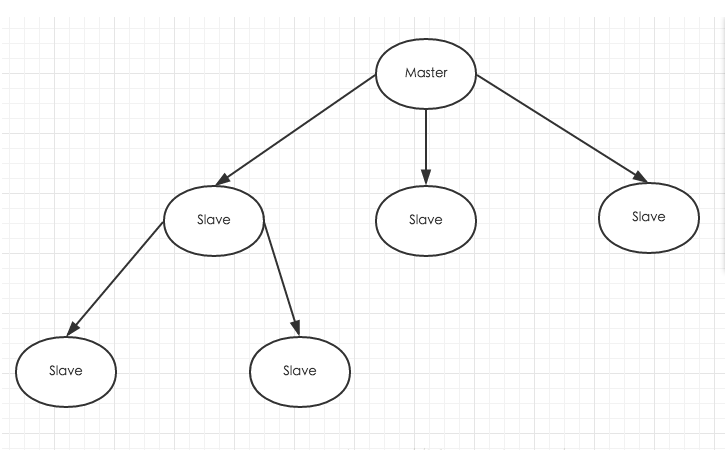
Redis主从复制的特点:
1、同一个master可以拥有多个slave。
2、master下的slave还可以接受同一架构中其它slave的连接与同步请求,实现数据的级联复制,即master->slave->slave模式;
3 、master以非阻塞的方式同步数据至slave,这将意味着master会继续处理client的读写请求;
4、slave端同步数据也可以修改为非阻塞的方式,当slave在执行新的同步时,它仍可以用旧的数据信息来提供查询
5、redis的主从复制具有可扩展性,即多个slave专门提供只读查询与数据的冗余,master端专门提供写操作,实现读写分离;
6、通过配置禁用master数据持久化机制,将其数据持久化操作交给slave完成,避免在master中要有独立的进程来完成此操作。
全量同步:
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
1)从服务器连接主服务器,发送SYNC命令;
2)主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
3)主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
4)从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
5)主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
6)从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;

完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。
备注:
如果master和slave之间的连接出现断开,slave可以自动重连到master。根据版本的不同,断连后同步的方式也不同:
2.8之前:重连成功之后,一次全量同步操作将被自动执行。
2.8之后:重连成功之后,进行部分同步操作。
增量同步:
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令
master持久化功能关闭时,将带来复制的安全性:
当我们部署redis主从复制的时候,一般都会强烈建议把master的持久化开关打开。即使为了避免持久化带来的延迟影响,不把持久化开关打开,那么也应该把master配置为不会自动启动。因为master异常刷新后再重启是非常危险的,会导致slave中的数据会被清空。
假设我们有一个redis节点A,设置为master,并且关闭持久化功能,另外两个节点B和C是它的slave,并从A复制数据。
如果A节点崩溃了导致所有的数据都丢失了,它会重启系统来重启进程。但是由于持久化功能被关闭了,所以即使它重启了,它的数据集也是空的。
而B和C依然会通过replication机制从A复制数据,所以B和C会从A那里复制到一份空的数据集,并用这份空的数据集将自己本身的非空的数据集替换掉。于是就相当于丢失了所有的数据。
即使使用一些工具,比如说sentinel来监控master-slaves集群,也会发生上述的情形,因为master可能崩溃后迅速恢复。速度太快而导致sentinel无法察觉到一个failure的发生。
redis2.8之后主从复制的过程:
在redis2.8之前从redis每次同步都会从主redis中复制全部的数据,如果从redis是新创建的,则从主redis中复制全部的数据这是没有问题的,但是,如果当从redis停止运行,再启动时可能只有少部分数据和主redis不同步,此时启动redis仍然会从主redis复制全部数据,这样的性能肯定没有只复制那一小部分不同步的数据高。
部分复制:
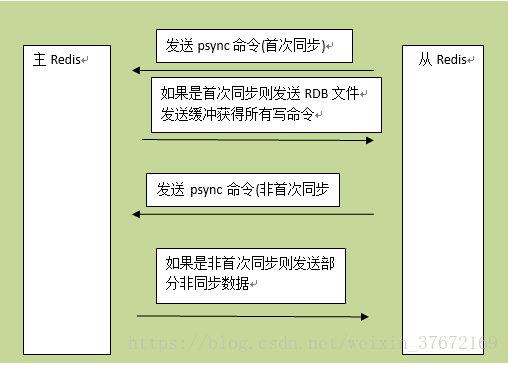
从机连接主机后,会主动发起 PSYNC(部分同步)命令,从机会提供 master的runid(机器标识,随机生成的一个串) 和 offset(数据偏移量,如果offset主从不一致则说明数据不同步),主机验证 runid 和 offset 是否有效, runid 相当于主机身份验证码,用来验证从机上一次连接的主机,如果runid验证未通过则,则进行全同步,如果验证通过则说明曾经同步过,根据offset同步部分数据。
部分复制的工作原理:
主服务器端为复制流维护一个内存缓冲区。主从服务器都维护一个复制偏移量(replication offset)和master run id ,当连接断开时,从服务器会重新连接上主服务器,然后请求继续复制,假如主从服务器的两个master run id相同,并且指定的偏移量在内存缓冲区中还有效,复制就会从上次中断的点开始继续。如果其中一个条件不满足,就会进行完全重新同步。因为主运行id不保存在磁盘中,如果从服务器重启了的话就只能进行完全同步了。
无磁盘的复制:
通常一个同步需要在磁盘上创建一个RDB文件,然后再重新加载这个文件来进行与slave数据同步。由于磁盘的读写是非常慢的,这对于redis master是一个非常有压力的操作,在2.8.18尝试使用无磁盘的复制,在这个设置里,进程直接把RDB 发送到slaves,而不需要使用磁盘来做中间的存储。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号