机器学习基础之梯度计算:Pytorch代码与公式
转载:https://zhuanlan.zhihu.com/p/667618296
我们看教科书里面讲批量梯度下降的算法数学公式都是类似这样的:

压根没有提到工程实现上面要面临的实际问题。本文主要就是通过结合代码和公式的分析让理论和实践之间完成一次双向奔赴。
机器学习中用来优化损失函数的一般都是用梯度下降算法,梯度的计算现在基本都是用Pytorch的自动微分来自动计算梯度。
这就造成了初学者会有的一个学习困难:平时看书本里面都是数学公式,实际写代码的时候梯度计算都是框架自动完成的,这样对于算法编程是友好的,但对于理解原理是有阻碍的。
因此,这篇文章的主要目标就是为机器学习初学者解释Pytorch梯度计算代码跟数学公式之间的联系,便于更加深入理解机器学习的原理。
一个简单的梯度计算例子

首先,我们创建变量x并为其分配一个初始值。
import torch
x = torch.arange(4.0)
x
这段代码创建了一个一维的PyTorch张量 x,其中包含了从0到3的四个浮点数。在数学表达式中,这可以表示为一个向量:
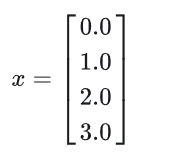
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True)
x.grad # 默认值是None


对损失向量如何计算梯度
问题引入
首先我们可以利用这个简单自动微分的能力来实现一个线性回归的代码:
import torch
import numpy as np
# 定义均方损失函数
def squared_loss(y_hat, y):
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
# 定义小批量随机梯度下降函数
def sgd(params, lr, batch_size):
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
# 定义线性回归模型
def linreg(X, w, b):
"""线性回归模型"""
return torch.matmul(X, w) + b
# 定义生成数据集的函数
def synthetic_data(w, b, num_examples):
"""生成 y = Xw + b + 噪声"""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
# 设置真实权重和偏差
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
# 定义小批量随机读取数据集的函数
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 这些样本是随机读取的,没有特定顺序
np.random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
# 初始化模型参数
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# 训练过程
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(10, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
l.sum().backward() #计算梯度
sgd([w, b], lr, 10) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
我们重点关注计算梯度的代码:l.sum().backward()。我打印了中间结果X和l的值如下:
X: tensor([[-0.0288, -0.6765], [-1.5220, -0.6657], [ 1.6177, -0.8816], [ 0.0680, 0.3873], [ 0.5701, -0.1812], [-0.2708, -1.8384], [ 0.6061, -1.8384], [-1.8956, -0.2839], [ 0.0729, 0.2994], [ 0.6761, 0.8173]]) l: tensor([[3.0895e-05], [2.0113e-05], [4.9850e-07], [1.9001e-05], [1.9959e-08], [2.2982e-05], [2.5084e-05], [2.5881e-05], [1.8395e-06], [5.2921e-05]], grad_fn=<DivBackward0>)

向量求梯度的例子

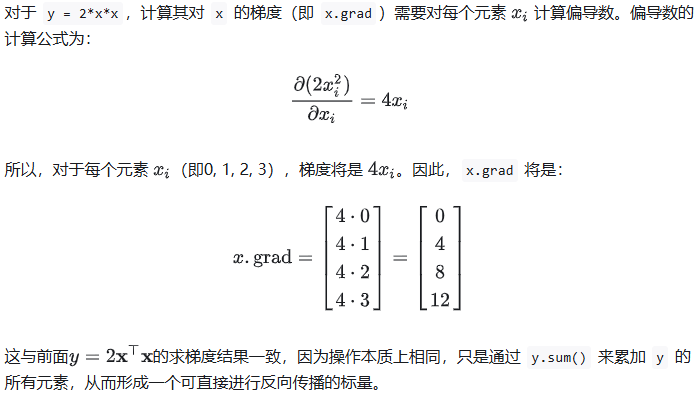
y = 2 * x * x # 等价于y.backward(torch.ones(len(x))) y.sum().backward() x.grad
首先计算 y = 2*x*x,这是对 x 的每个元素进行平方乘以2的操作。接着,调用 y.sum().backward() 来计算 y 中所有元素之和的梯度。
自动微分对向量的兼容
注意这里的y.sum().backward( )等价于 y.backward(torch.ones(len(x)))。
在 PyTorch 中,当对非标量(例如向量或矩阵)调用 backward() 时,需要提供一个与非标量同形状的 gradient 参数。这个参数指定了非标量每个元素的梯度权重。
y.sum().backward():这里首先计算y 中所有元素的和,得到一个标量,然后对这个标量调用backward()。由于结果是标量,不需要提供gradient 参数。-
y.backward(torch.ones(len(x))):这里直接对非标量y 调用backward(),但提供了一个与y 同形状的全1向量作为gradient 参数。这意味着每个元素的梯度权重都是1。
两种方法都等价于计算 y 中每个元素相对于 x 的偏导数,并将这些偏导数加总。数学上,这可以表示为:

我们可以代入具体的数值来进行验证结论。假设 x = [0, 1, 2, 3],则 y = 2 * x * x,可以计算出两种情况下的梯度。
1. 对于 y.sum().backward()

2. 对于 y.backward(torch.ones(len(x)))
当我们在 y.backward(torch.ones(len(x))) 中使用全1向量作为 gradient,我们实际上是对 y 中的每个元素赋予相同的权重。
在数学上,这意味着我们在计算 y 中每个元素对最终梯度的贡献时,每个元素都被等同对待。具体到公式,我们可以这样表示:

这与之前通过 y.sum().backward() 得到的结果相同。在这种情况下,由于 gradient 是全1向量,我们实际上是计算了 y 中每个元素相对于 x 的梯度之和,这与直接对 y.sum() 求梯度是等价的。
在 y.sum().backward() 和 y.backward(torch.ones(len(x))) 之间,计算过程存在细微区别,主要体现在梯度累积的方式上。
-
y.sum().backward(): 首先计算y 的所有元素之和,形成一个标量,然后对这个标量执行反向传播。在这个过程中,梯度是直接针对求和结果计算的,这意味着在内部,自动微分系统会将y 中每个元素的梯度累加起来,然后一起反向传播。 -
y.backward(torch.ones(len(x))): 对y 的每个元素执行反向传播,其中torch.ones(len(x)) 指定了每个元素梯度的权重(在这个例子中,都是1)。在这种情况下,自动微分系统会分别计算y 中每个元素对应的梯度,然后将这些梯度按照权重(这里是1)相加,最终得到总梯度。
区别在于:
-
y.sum().backward() 是一种更直接的方法,用于当我们只关心总和的梯度时。 -
y.backward(torch.ones(len(x))) 提供了更多的灵活性,因为我们可以通过改变传递给backward() 的张量来调整每个元素对总梯度的贡献。
在效果上,当使用全1的张量时,两者计算得到的梯度是相同的。
但在内部实现上,y.backward(torch.ones(len(x))) 会对每个元素分别计算梯度然后累加,而 y.sum().backward() 直接对总和计算梯度。
这里我们举一个非全1的gradient向量来进一步说明它的作用。
import torch
x = torch.arange(4.0)
x
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True)
x.grad # 默认值是None
y = 2 * x * x
y.backward(torch.tensor([1, 1, 0.1, 0.1]))
x.grad

反向传播的起点是标量
那么为什么反向传播需要从一个标量开始?原因在于它的核心算法——链式法则。
链式法则用于计算复合函数的导数,而在多维情况下,这需要有一个清晰定义的输出方向来应用。
在深度学习中,我们通常关注的是如何根据损失函数(一个标量)来调整网络参数。损失函数是一个标量,因为它提供了一个单一的度量,表示当前模型的表现好坏。
计算这个标量相对于模型参数的梯度,就是在问:“如果我改变这个参数一点点,损失函数会如何变化?”
当你有一个向量或矩阵输出时,这个输出的每个元素可能依赖于输入的不同部分,也可能相互依赖。
如果直接从这样的结构开始反向传播,就会缺乏一个统一的量度来衡量整体的变化。转换成标量后,就提供了一个明确的、单一的值,表示整个输出的“总效应”,从而可以应用链式法则来计算对每个输入的影响。
因此,通过将输出转换为标量,我们可以更清晰地使用链式法则来逐步回溯,计算每个参数的梯度。这就是为什么反向传播通常需要从一个标量开始的原因。
打个比方,想象一下,你是一个园艺师,负责一个大花园的照顾。
你的目标是让整个花园看起来尽可能美丽。这里,“花园的美丽程度”可以被看作是一个“标量”——它是一个单一的度量,表示整个花园的总体状况。
现在,假设你有一系列的工具和技术(相当于模型的参数),比如浇水、施肥、修剪等,来照顾花园的不同部分。
你需要弄清楚,应该如何调整这些工具和技术的使用,以最大化花园的美丽程度。
如果你直接尝试同时关注花园的每一朵花、每一棵植物(相当于一个向量或矩阵输出),那就太复杂了。
每个部分都有自己的需求,而且它们之间可能相互影响。这就像试图同时解决太多的问题,没有一个清晰的方向。
但如果你将注意力集中在“整个花园的美丽程度”上,那么你就有了一个明确的目标。
你可以问自己:“如果我增加这个区域的浇水次数,整个花园的美丽程度会如何变化?”这样,你就可以一步步地调整你的方法,直到找到最优的照顾方式。
在机器学习中,反向传播的情况类似。我们需要一个标量(如损失函数),来衡量整个模型的表现。然后,我们可以计算模型每个参数对这个标量的影响(梯度),逐步调整这些参数,以优化整个模型的表现。这就是为什么反向传播需要从一个标量开始的原因。
在我们的例子中,当执行 y.sum().backward() 时,我们实际上是在计算 y 所有元素之和的梯度。计算的结果是一个向量,这个向量提供了如何调整 x 以最大程度地影响 y 的总和的信息。在梯度下降算法中,l.sum().backward()计算出来的梯度会用于更新参数,让损失的和l.sum()最小化,也就是说哪些参数让损失和的影响最大,就反向调整这些参数,让它们影响变小。
因此,不管是直接代入一个x计算损失的标量结果,还是代入N个x批量计算出损失的向量结果后通过求和转为标量,最后的目的都是为了给优化算法确定一个可以量化的目标,这样梯度下降算法才能根据这个量化的目标去最小化。
总结
在简单例子中,y.sum().backward()用于计算函数y = 2 * x * x对x的梯度。当我们调用.backward()时,PyTorch 自动计算这些梯度并存储在x.grad属性中。
简单例子的核心是对一个单变量函数的梯度计算。
对于线性回归示例,l.sum().backward()的作用类似,但上下文更复杂。在这里,l是损失函数的输出,是一个批量数据的集合。
线性回归模型的目标是找到最小化损失函数的参数值,即权重w和偏差b。
1:损失函数(Loss Function) : 在线性回归中,我们使用均方误差作为损失函数。这个函数计算了预测值(y_hat)和真实值(y)之间的差异。
2:梯度计算(Gradient Computation) : l.sum().backward()计算损失函数相对于模型参数(在这个例子中是w和b)的梯度。这里的.sum()是因为l是一个批量数据的损失集合,我们需要一个单一的损失值来计算梯度。
3:批量数据(Batch Data) : 在线性回归的例子中,我们不是对单一数据点计算梯度,而是对一个数据批量。这是深度学习中常见的做法,可以加快训练速度,并且有助于提高模型的泛化能力。
4:参数更新(Parameter Update) : 计算得到的梯度用于更新模型的参数,这一步在sgd()函数中完成。
总结来说,y.sum().backward()和l.sum().backward()都是在计算梯度,
但是在简单例子中,我们是对单一函数的单个变量进行操作,
而在线性回归中,我们是在处理一个批量数据集合,并且涉及到模型参数的更新。

由于微积分中的求和与微分操作通常可以互换(即求和的微分等于微分的求和),所以这两个公式在大多数情况下是等价的。
不等价的可能情况之一就是在实际的计算中,由于数值稳定性和精度限制,对每个损失项单独计算梯度然后求和与对总和求梯度可能会导致略有不同的数值结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号