Scrapy爬虫错误日志汇总
1、数组越界问题(list index out of range)

原因:第1种可能情况:list[index]index超出范围,也就是常说的数组越界。
第2种可能情况:list是一个空的, 没有一个元素,进行list[0]就会出现该错误,这在爬虫问题中很常见,比如有个列表爬下来为空,统一处理就会报错。
解决办法:从你的网页内容解析提取的代码块中找找看啦(人家比较习惯xpath + 正则),加油 ~
---------------------------------------------------华丽的分隔符------------------------------------------------------------
2、http状态代码没有被处理或不允许(http status code is not handled or not allowed)

原因:第1种情况:就是你的http状态码没有被识别,需要在settings.py中添加这个状态码信息,相当于C语言中的#define预处理宏定义命令吧
第2种情况:403是网页状态码,表示访问拒绝或者禁止访问。应该是你触发到网站的反爬虫机制了。
解决办法:如果是第1种情况,在你的setting.py中,添这么一句短小精悍的话就OK了,紧接着就等着高潮吧您呐:HTTPERROR_ALLOWED_CODES = [403]
如果是第2种情况,a.伪造报文头部user-agent(网上有详细教程不用多说)
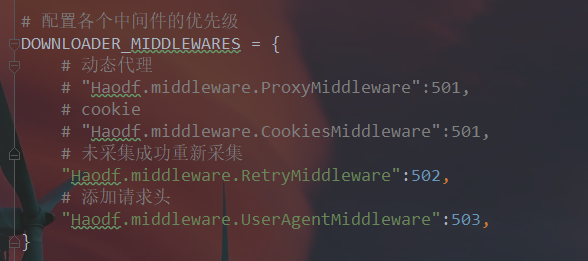
b.使用可用代理ip,如果你的代理不可用也会访问不了
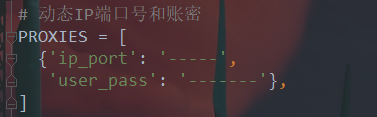
c.是否需要帐户登录,使用cookielib模块登录帐户操作
如果以上方法还是不行,那么你的ip已被拉入黑名单静止访问了。等一段时间再操作。如果等等了还是不行的话:
d.使用phatomjs或者selenium模块试试。
还不行使用别的scrapy爬虫框架看看。
以上都不行,说明这网站反爬机制做的很好,爬不了了,没法了,不过我觉得很少有这种做得很好的网站
---------------------------------------------------华丽的分隔符------------------------------------------------------------
3、item限制问题(keyError: xxx does not support field :某某某)
原因:第一种情况:item.py中所需字段没有预先定义完整
第二种情况:在scrapy中item存在的意义就是
#可以通过直接看items.py,可以看出来要爬取那些字段
#防止我们在item["键名"] 输入键名的时候输入错误
但是有些时候,我们可能会发现,有些需要爬取的不确定的地段,例如下图
4、丢包问题
现象:明明代码跟视频中的例子一样,一运行却出错了,在不修改代码的情况下重新运行一次却又变好了,这是为什么?
在网络信息的传输中会出现偶然的丢包现象,有可能是你发送的请求服务器没有收到,也有可能是服务器响应的信息不能完整送回来
尤其是在网络阻塞的时候,所以,在设计一个称职的爬虫时,需要考虑到这偶尔的丢包现象。

解决办法:

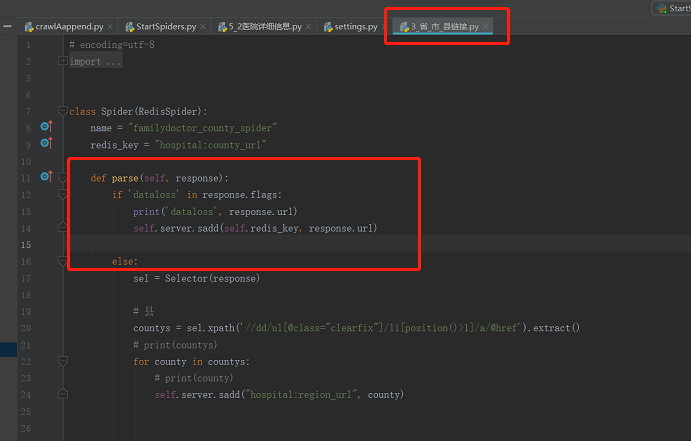
1 DOWNLOAD_FAIL_ON_DATALOSS = False
2
3 if 'dataloss' in response.flags:
4 print('dataloss', response.url)
5 self.server.sadd(self.redis_key, response.url)
此篇文章持续更新,未完待续....
欢迎大家留下自己的问题,互相讨论,互相学习,互相总结,,,,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号