
通过前面的学习,我们已经知道,在NR中,每个PDCP SDU形成PDCP PDU,然后形成RLC SDU, 然后组成RLC PDU。 由于NR里面去掉了RLC 级联功能。 一个RLC PDU可能包含一个RLC SDU或一个RLC SDU的分段。 那么很多个RLC PDU组成一个mac PDU.
那么RLC PDU的组成这部分是放在RLC做,还是放在MAC做? 不同的产品有不同的实现方式。无论放在哪儿做,都需要先知道mac调度的tb size大小,然后才知道去获取多少个rlc sdu来组包。
在本次项目中组合RLC PDU 在mac层处理,如果调度TB size比较大,可能会处理100多个RLC Sdu,耗时比较大。 所以考虑是否将组rlc pdu这个操作转移到rlc去做?????比较理想的是rlc收到sdu,就组成pdu, 后面调度完后就去取rlc pdu. 想法很好。
在讨论NR RLC相对于LTE做出的重大变化的How和Why之前,我们先来看下What. 通过对比LTE和NR协议,我们注意到UM和AM的处理流程图有三个重大改动,协议其余部分的区别都是围绕这几个改动来展开。下图是AM的对比情况(UM类似),左侧是LTE,右侧是NR:

我用三种颜色的虚线椭圆标出这三大改动(同时说明改动是在发送端还是接收端):
1.粉色(发送端):NR去掉了LTE的Concatenation(级联)功能,即Removing Concatenation
2.蓝色(发送端):
LTE - RLC header在Segmentation(分段)&Concatenation(级联)之后添加
NR - 收到RLC SDU(PDCP PDU)之后,会先添加RLC header, 经过segmentation(如果有必要的话)之后修改RLC header,最后针对本次未发送的segment添加RLC header.
RLC header处理流程的变化实际是去掉conatenation的结果,并由此引入了NR相对于LTE的另一个重大变化:基于SO字段的分段和重分段,即So-Based Segmentation and Re-Segmentation
3.绿色(接收端): NR去掉了Reordering功能,即Removing Reordering
这三个改动并非孤立,而是互有关联,下面将针对这三个改动的How和Why展开详细讨论,其中RLC header的处理和So-Based Segmentation/Re-Segmentation将放在Removing Concatenation部分,而Removing Reordering将专门讲解
3GPP Technical Report 38.913提到NR的目标峰值速率和用户面时延设定如下:
- The target for peak data rate should be 20Gbps for downlink and 10Gbps fo ruplink.
- For URLLC, thetarget for user plane latency should be 0.5ms for UL, and 0.5ms for DL.
- For eMBB, the target for user plane latency should be 4ms for UL, and 4ms for DL.
这里主要讨论eMBB(URLLC会采用shorter TTI,暂且按下不表)。
- 对于下行,假定峰值速率20Gbps,TTI是1ms, PDCP SDU大小是1500 Bytes(即IP包大小,注意Byte和bit大小写b的区别),如果忽略PDCP PDU头部信息不计,那么若NR RLC沿用LTE的concatenation策略,一个TTI里需要级联的RLC SDU(PDCP PDU)的个数是多少呢?我们算一下:(20Gbps/1000ms) ÷ (1500 * 8bit) = 1666.6, 这对实现而言是极大挑战。 这个比上面项目中遇到的瓶颈更大,处理1000多个。(目前项目中NR就是沿用了LTE策略)
- 对于上行,则挑战性更大,因为当UE有上行数据发送时,需要UE先发送BSR(Buffer Status Reports)给基站,等UE MAC层收到基站下发的UL Grant并且进行LCP(Logical Channel Prioritication)后,才会通知对应于某个逻辑信道的RLC实体能传输数据量的大小,这样还没到RLC处理就已经耗费了部分时间,而RLC还要把大量的RLC SDU级联起来,然后再发给MAC层,MAC再把各逻辑信道的RLC PDU复用(Multiplexing)起来,这对4ms 用户面时延的实现难度更大。
注意上面说的是假设NR RLC沿用LTE的级联策略。
LTE用户面处理的复杂性,无法适应NR高速率和低时延的要求,因此NR用户面设计需要尽可能简化和高效,而去掉RLC Concatenation,将其下移到MAC层,同时修改MAC PDU结构,可以大大简化处理流程,提高处理效率,处理流程优化成如下:
1. 在MAC收到UL Grant之前,RLC预先针对每个RLC SDU生成RLC header构建RLC PDU(非实时处理,也就是不依赖于MAC层的输入),基于这样的设计,NR RLC SN只针对RLC SDU生成,即便在后续步骤需要对RLC SDU进行分段处理,各分段仍然使用SDU原始SN, 同时RLC header结构进行了优化,细节稍后详细说明。
2. 当MAC层完成LCP通知RLC可以传输的数据量之后,如果已组装好的所有RLC PDU大于能够传输的数据量,RLC只需要对最后一个可传输的RLC SDU进行分段(实时处理,依赖于MAC输入)。对于前面所有未分段的RLC SDU, RLC header保持不变,对于最后一个RLC SDU的第一个RLC SDU Segementation,只需要修改SI字段(实时处理)。
3. 对于最后一个RLC SDU的第一个RLC SDU Segmentation第二个分段,可以在收到下一次的MAC可传输数据量大小指示前,预先生成RLC header(非实时处理)。
4. 基于上面的优化,RLC PDU header可以大大简化:
由于RLC去掉了concatenation, 该功能需要在MAC层完成,因此MAC头域也发生了变化,对比如下:
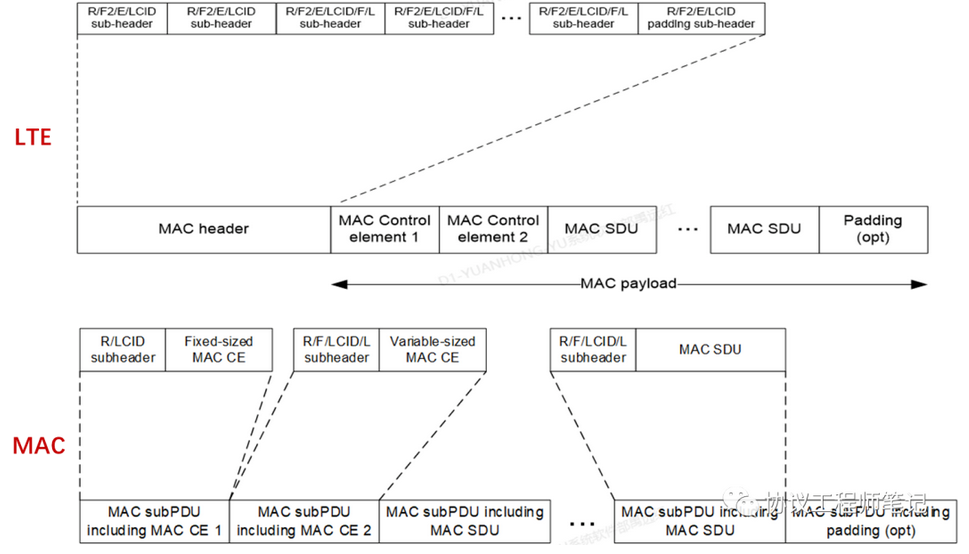
这样的好处是:MAC层每生成一个MAC Sub-Header,就可以把MAC sub-PDU发给物理层,而无需像LTE那样等待整个MAC PDU header完成才发。
上面介绍的思路其实比较清晰,就是从实现层面上怎么去修改现在的逻辑和接口。
Removing Reordering
在对比LTE和NR的reordering功能之前,我们先弄清什么是reordering以及其作用。‘order’作为动词时除了有“命令”和“下订单/订购”的意思外,还有‘排列’的意思,那re-order自然就是重新排列,RLC里一般叫重排序。那什么情况下需要重排序呢?肯定是乱序了,也就是收到的包out-of-order了,才需要重排,乱序的包重排好了,才能按顺序发往(in-sequence deliver)更上层。那么哪些因素会导致乱序呢?
1. 由于MAC HARQ进程是并行运行的,多个HARQ进程可以同时发送多个MAC PDU. 由于每个进程独立运行,并且因多变的无线信道环境使得各HARQ重传次数不一,这样MAC层就无法保证按序将RLC PDU发送给RLC层。
2. RLC这一层如果发现丢包,也会启动ARQ来重传未收到的PDU, 这就可能导致SN更大的PDU反而比SN更小的PDU先收到, 从而出现乱序。

基于以上,LTE采取了两级reordering机制:RLC层主要针对由于HARQ/ARQ引起的乱序进行reordering;PDCP主要针对多连接下的分离式承载产生的乱序进行reordering.
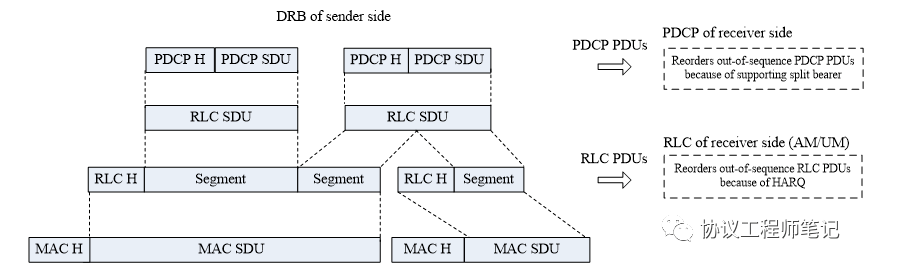
LTE是这么处理的:
对于RLC层的reordering功能,由于RLC需要按序将RLC SDU(也就是PDCP PDU)传给PDCP层,即便RLC里已经完整组装出某个RLC SDU, 但是若其之前RLC SDU还没有收到或没有完整收到,那么该RLC SDU仍不会发给PDCP层,这样某个SDU如果丢失需要重传,就可能导致后面已经收到很多RLC SDU干等待很长时间而无法发送给PDCP以进行decipher,这对低延时系统来说显然非常不合适。
NR在RLC 中移除了重排序功能:
因此NR里,将RLC reordering功能去掉,只在PDCP层进行reordering. 这样,一是RLC无需等待前面可能丢失的RLC PDU重传,而是每收到一个完整的RLC SDU就会传给PDCP,PDCP就能马上进行deciphering处理;二是RLC Buffer所需内存可以大大减少。
原文链接:https://blog.csdn.net/travel_life/article/details/123867468

 浙公网安备 33010602011771号
浙公网安备 33010602011771号