102302155张怡旋数据采集第三次作业
作业一
要求:指定一个网站,爬取这个网站中的所有的所有图片。实现单线程和多线程的方式爬取。–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
1.核心代码和运行结果
点击查看代码
def parse_images(html, page):
"""解析页面中的图片URL"""
if not html:
return []
soup = BeautifulSoup(html, "html.parser")
# 匹配所有商品图片标签
img_tags = soup.select("ul.bigimg li a img") # 核心商品列表
valid_urls = []
for img in img_tags:
# 提取图片URL(优先data-original,其次src)
img_url = img.get("data-original") or img.get("src")
if not img_url:
continue
# 过滤目标格式图片
if re.match(r'^//img3m\d+\.ddimg\.cn/.+\.(jpg|jpeg)$', img_url):
# 补全HTTPS协议头
full_url = f"https:{img_url}"
# 全局去重
with url_lock:
if full_url not in processed_urls:
processed_urls.add(full_url)
valid_urls.append(full_url)
print(f"第{page}页解析到 {len(valid_urls)} 张有效图片")
return valid_urls
def download_image(img_url, page, crawl_type):
"""下载单张图片"""
global image_count
# 控制总下载数量
with count_lock:
if image_count >= MAX_IMAGES:
return False
current_num = image_count + 1
image_count = current_num
try:
# 从URL提取商品ID
id_match = re.search(r'/(\d+)-\d+_b', img_url)
product_id = id_match.group(1) if id_match else f"unknown_{random.randint(1000, 9999)}"
# 生成文件名
filename = f"{crawl_type}_page{page}_id{product_id}_{current_num}.jpg"
save_path = os.path.join(SAVE_DIR, filename)
# 下载图片
headers = get_headers()
headers["Referer"] = "https://search.dangdang.com/" # 关键Referer设置
response = requests.get(
img_url,
headers=headers,
timeout=20,
stream=True,
verify=False
)
response.raise_for_status()
# 保存图片
with open(save_path, "wb") as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
print(f"{crawl_type} - 第{page}页 [{current_num}/{MAX_IMAGES}]:{filename}")
return True
except Exception as e:
print(f"{crawl_type} - 第{page}页 [{current_num}/{MAX_IMAGES}] 失败:{str(e)[:50]}")
return False
# -------------------------- 单线程爬取 --------------------------
def single_thread_crawl():
global image_count, processed_urls
image_count = 0
processed_urls = set() # 重置计数器和去重集合
print("开始单线程爬取")
start_time = time.time()
for page in range(1, MAX_PAGES + 1):
if image_count >= MAX_IMAGES:
break
print(f"\n处理第 {page}/{MAX_PAGES} 页")
html = fetch_page(page)
if not html:
time.sleep(2)
continue
img_urls = parse_images(html, page)
if not img_urls:
time.sleep(1)
continue
# 下载当前页图片
for url in img_urls:
if image_count >= MAX_IMAGES:
break
download_image(url, page, "单线程")
time.sleep(random.uniform(0.8, 1.2)) # 控制速度
end_time = time.time()
print(f"\n单线程爬取完成,耗时 {end_time - start_time:.2f} 秒,共下载 {image_count} 张图片")
# -------------------------- 多线程爬取 --------------------------
def multi_thread_crawl(max_workers=5):
global image_count, processed_urls
image_count = 0
processed_urls = set() # 重置计数器和去重集合
all_img_urls = [] # 存储所有待下载图片URL及对应页码
print(f"开始多线程爬取(线程数:{max_workers})")
start_time = time.time()
# 第一步:收集所有图片URL
print("收集图片URL中...")
for page in range(1, MAX_PAGES + 1):
if len(all_img_urls) >= MAX_IMAGES:
break
html = fetch_page(page)
if not html:
time.sleep(1)
continue
img_urls = parse_images(html, page)
if img_urls:
# 控制总量不超过MAX_IMAGES
remaining = MAX_IMAGES - len(all_img_urls)
all_img_urls.extend([(url, page) for url in img_urls[:remaining]])
time.sleep(random.uniform(0.5, 1.0))
# 第二步:多线程下载
if not all_img_urls:
print("未收集到任何图片URL,终止下载")
return
print(f"\n开始下载 {len(all_img_urls)} 张图片...")
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = [
executor.submit(download_image, url, page, "多线程")
for url, page in all_img_urls
]
# 等待所有任务完成
for future in futures:
future.result()
end_time = time.time()
print(f"\n多线程爬取完成,耗时 {end_time - start_time:.2f} 秒,共下载 {image_count} 张图片")
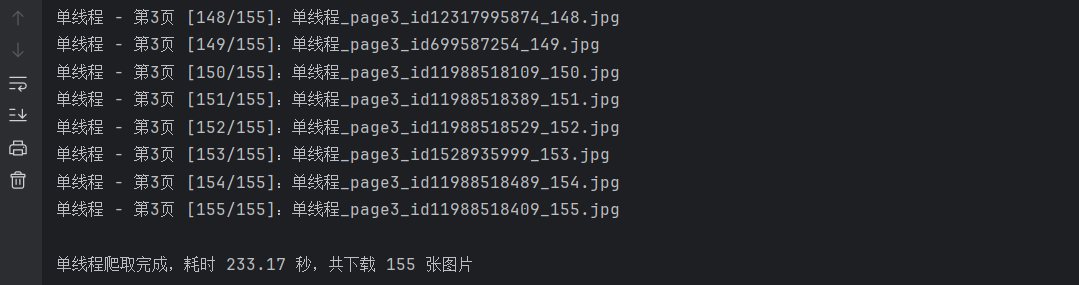
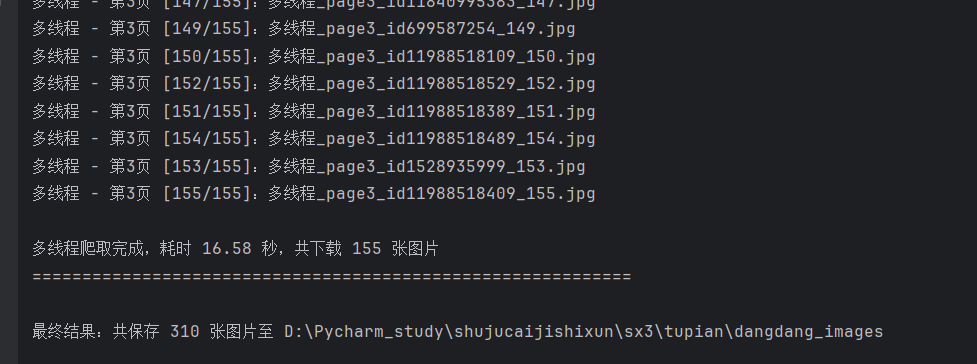
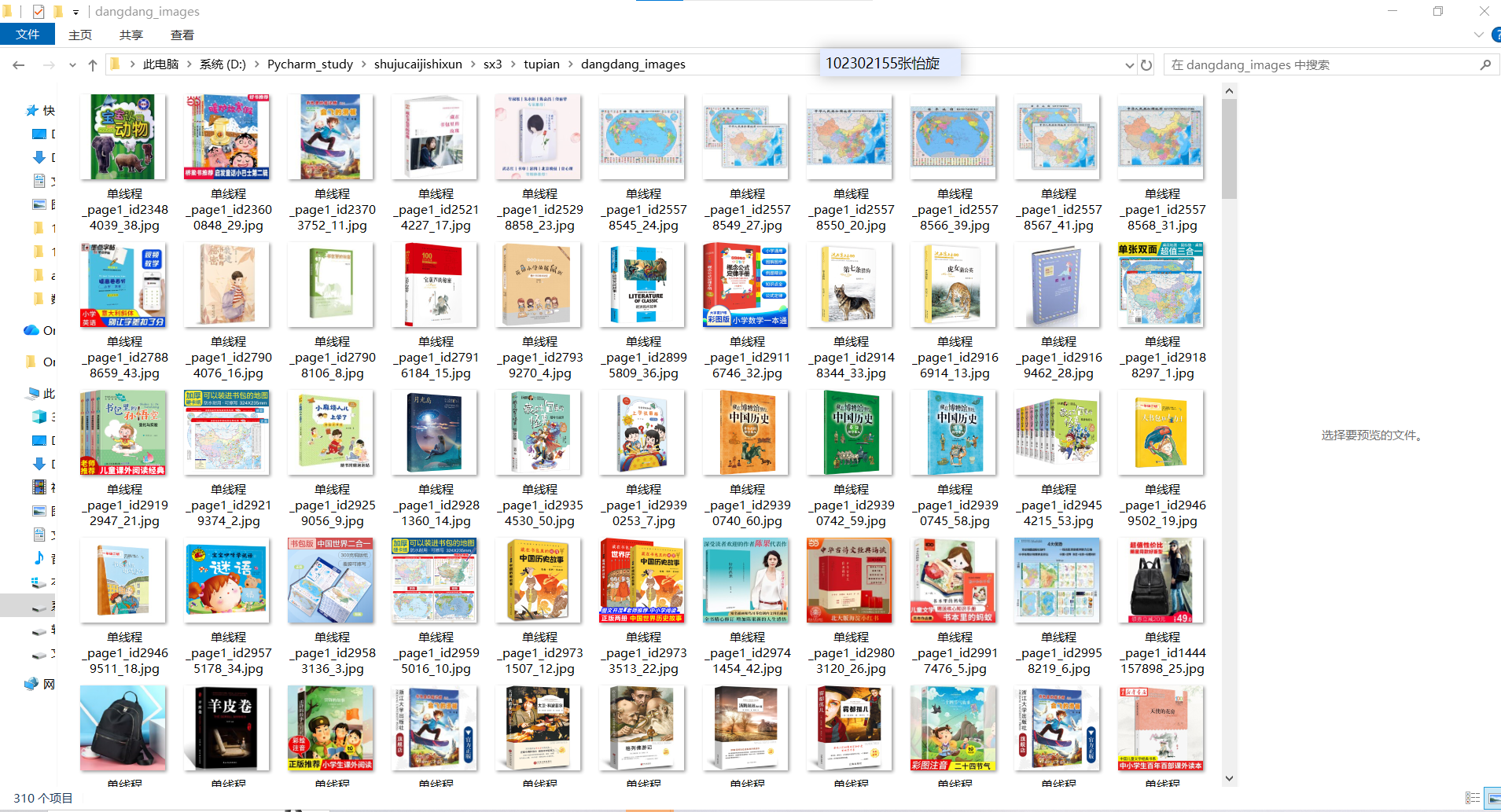
2.心得
在爬取之前我进入该网站查看图片的html的结构,如图:
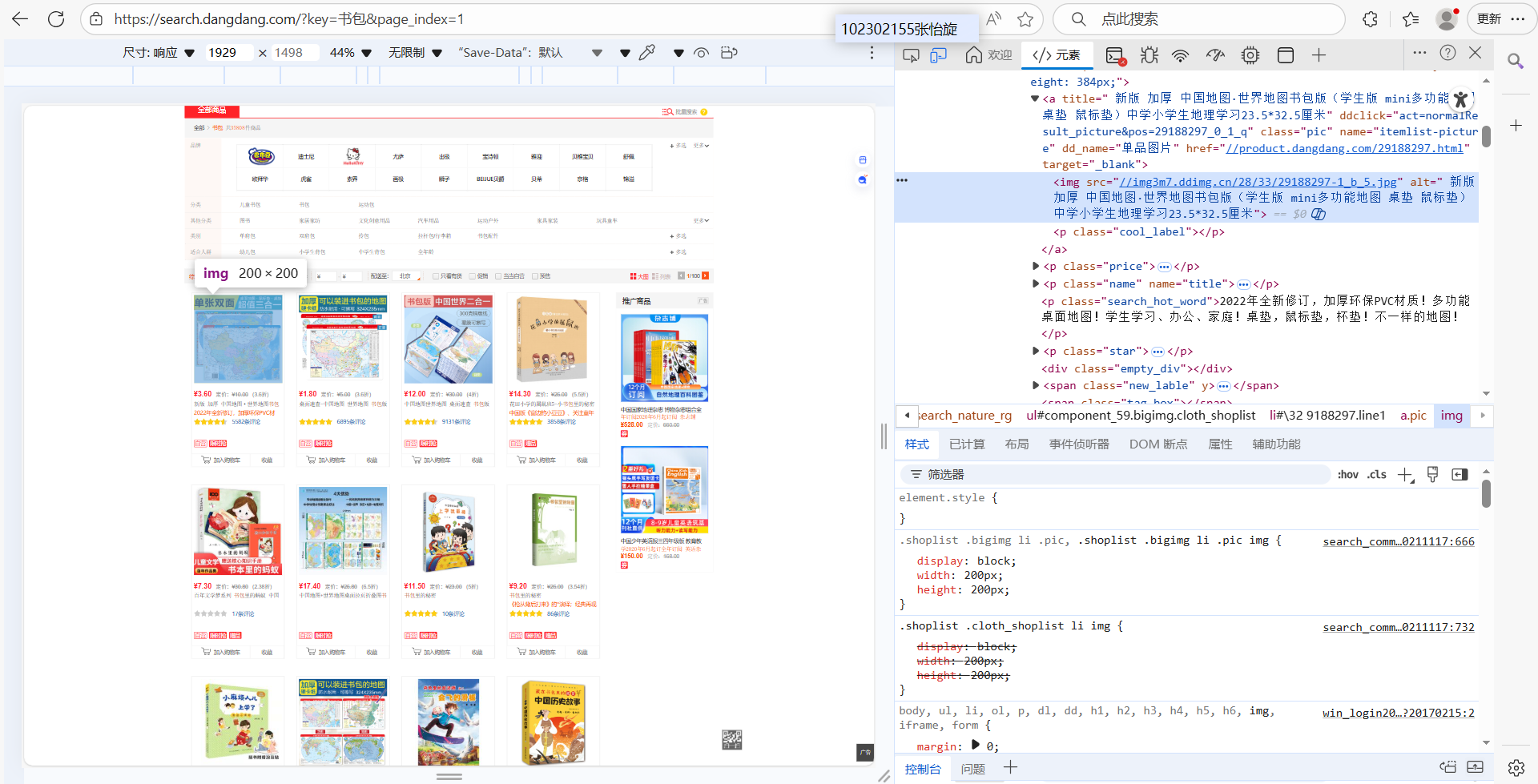
大致了解了,就开始弄代码。但是弄了好多次,明明有很多照片,但代码解析出的 URL 很少甚至好多页一个都解析不出来,后来发现页面结构变得复杂了,应该是双十一加强了一下,存在多个商品区域(普通商品区、推荐区、促销区),解析范围过窄会遗漏。图片出来后,又发现同一商品图片被多次下载,文件名不同但内容一致。我就从 URL 中提取商品唯一 ID,下载前检查本地是否已存在该 ID 的图片。爬取时为了防止反爬,设置了限制,多线程中使用线程锁(threading.Lock())保护计数器,确保计数准确。最终才得以完成。
Gitee文件夹链接:https://gitee.com/njs5/bgyuhnji/tree/homework3/tupian
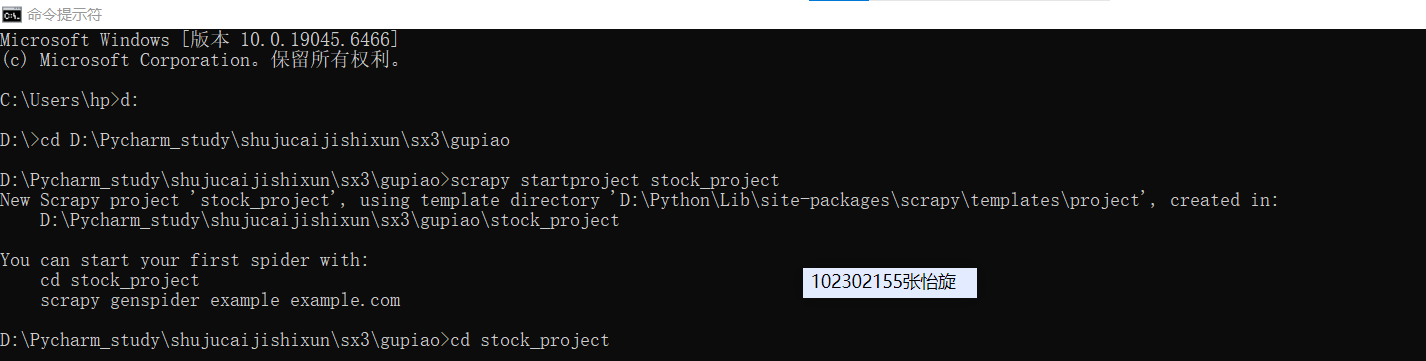
作业二
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:MySQL数据库存储
1.核心代码和运行结果
items.py的代码:
点击查看代码
import scrapy
class StockItem(scrapy.Item):
id = scrapy.Field() # 序号
bStockNo = scrapy.Field() # 股票代码
sStockName = scrapy.Field() # 股票名称
fLatestPrice = scrapy.Field() # 最新报价
fChangePercent = scrapy.Field() # 涨跌幅(%)
fChangeAmount = scrapy.Field() # 涨跌额
sVolume = scrapy.Field() # 成交量
sTurnover = scrapy.Field() # 成交额
fAmplitude = scrapy.Field() # 振幅(%)
fHighest = scrapy.Field() # 最高
fLowest = scrapy.Field() # 最低
fOpenToday = scrapy.Field() # 今开
fCloseYesterday = scrapy.Field() # 昨收
点击查看代码
import pymysql
import logging
from itemadapter import ItemAdapter
class StockMySQLPipeline:
def __init__(self, host, user, password, database, port):
self.host = host
self.user = user
self.password = password
self.database = database
self.port = port
self.db = None
self.cursor = None
self.logger = logging.getLogger(__name__) # 日志对象
@classmethod
def from_crawler(cls, crawler):
# 从配置文件读取数据库参数
return cls(
host=crawler.settings.get('MYSQL_HOST'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
database=crawler.settings.get('MYSQL_DATABASE'),
port=crawler.settings.get('MYSQL_PORT', 3306)
)
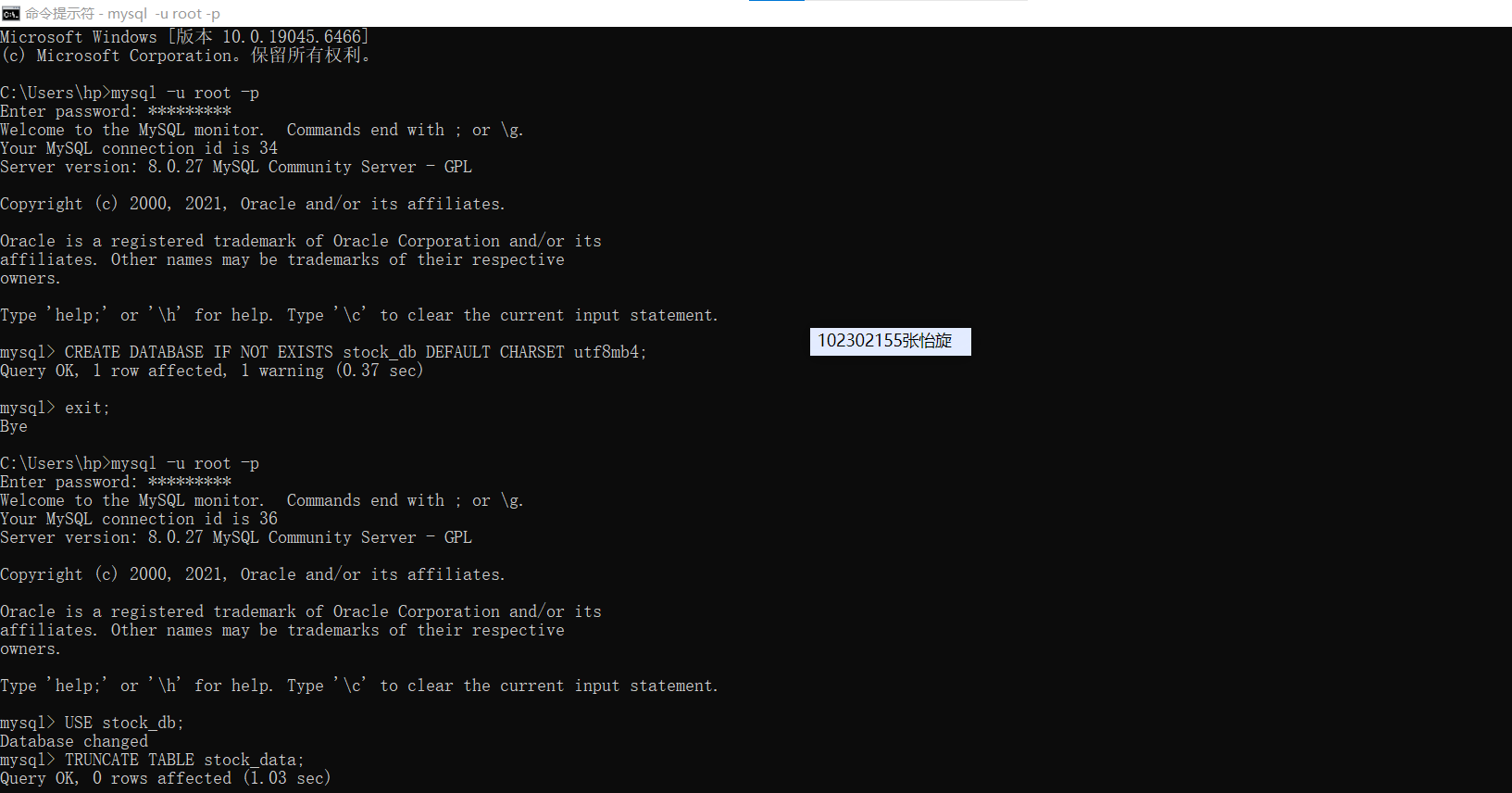
def open_spider(self, spider):
# 连接数据库并创建表
try:
self.db = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.database,
port=self.port,
charset='utf8mb4'
)
self.cursor = self.db.cursor()
# 创建表(若已存在则覆盖)
create_table_sql = """
CREATE TABLE IF NOT EXISTS stock_data (
id INT PRIMARY KEY,
bStockNo VARCHAR(20) NOT NULL,
sStockName VARCHAR(50) NOT NULL,
fLatestPrice DECIMAL(10,2) NULL,
fChangePercent DECIMAL(10,2) NULL,
fChangeAmount DECIMAL(10,2) NULL,
sVolume VARCHAR(20) NULL,
sTurnover VARCHAR(20) NULL,
fAmplitude DECIMAL(10,2) NULL,
fHighest DECIMAL(10,2) NULL,
fLowest DECIMAL(10,2) NULL,
fOpenToday DECIMAL(10,2) NULL,
fCloseYesterday DECIMAL(10,2) NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
"""
self.cursor.execute(create_table_sql)
self.db.commit()
self.logger.info("数据库连接成功,表创建完成")
except Exception as e:
self.logger.error(f"数据库连接失败:{str(e)}")
raise # 连接失败则终止爬虫
def process_item(self, item, spider):
adapter = ItemAdapter(item)
try:
# 处理数字类型转换(空值或非数字转为None)
def to_float(value):
if value and str(value).replace('.', '', 1).isdigit():
return float(value)
return None
# 插入数据SQL
insert_sql = """
INSERT INTO stock_data (
id, bStockNo, sStockName, fLatestPrice, fChangePercent,
fChangeAmount, sVolume, sTurnover, fAmplitude, fHighest,
fLowest, fOpenToday, fCloseYesterday
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
# 参数值
params = (
adapter['id'],
adapter['bStockNo'],
adapter['sStockName'],
to_float(adapter['fLatestPrice']),
to_float(adapter['fChangePercent']),
to_float(adapter['fChangeAmount']),
adapter['sVolume'],
adapter['sTurnover'],
to_float(adapter['fAmplitude']),
to_float(adapter['fHighest']),
to_float(adapter['fLowest']),
to_float(adapter['fOpenToday']),
to_float(adapter['fCloseYesterday'])
)
self.cursor.execute(insert_sql, params)
self.db.commit()
self.logger.debug(f"成功存储:{adapter['bStockNo']} {adapter['sStockName']}")
except Exception as e:
self.db.rollback()
self.logger.error(f"存储失败(数据:{item}):{str(e)}")
return item
def close_spider(self, spider):
if self.db:
self.cursor.close()
self.db.close()
self.logger.info("数据库连接已关闭")
点击查看代码
# 数据库配置
MYSQL_HOST = 'localhost'
MYSQL_USER = 'root' # MySQL用户名
MYSQL_PASSWORD = 'zyx051120' # MySQL密码
MYSQL_DATABASE = 'stock_db' # 数据库名
MYSQL_PORT = 3306
# 启用MySQL管道
ITEM_PIPELINES = {
'stock_project.pipelines.StockMySQLPipeline': 300,
}
# 反爬设置
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "stock_project (+http://www.yourdomain.com)"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Concurrency and throttling settings
#CONCURRENT_REQUESTS = 16
CONCURRENT_REQUESTS_PER_DOMAIN = 1
DOWNLOAD_DELAY = 1
点击查看代码
import scrapy
import json
from ..items import StockItem
class EastmoneyApiSpider(scrapy.Spider):
name = 'eastmoney_api'
allowed_domains = ['eastmoney.com']
# 东方财富网沪市A股列表API
start_urls = [
'http://79.push2.eastmoney.com/api/qt/clist/get?pn=1&pz=200&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80&fields=f12,f14,f2,f3,f4,f5,f6,f7,f15,f16,f17,f18&_=1718000000000'
]
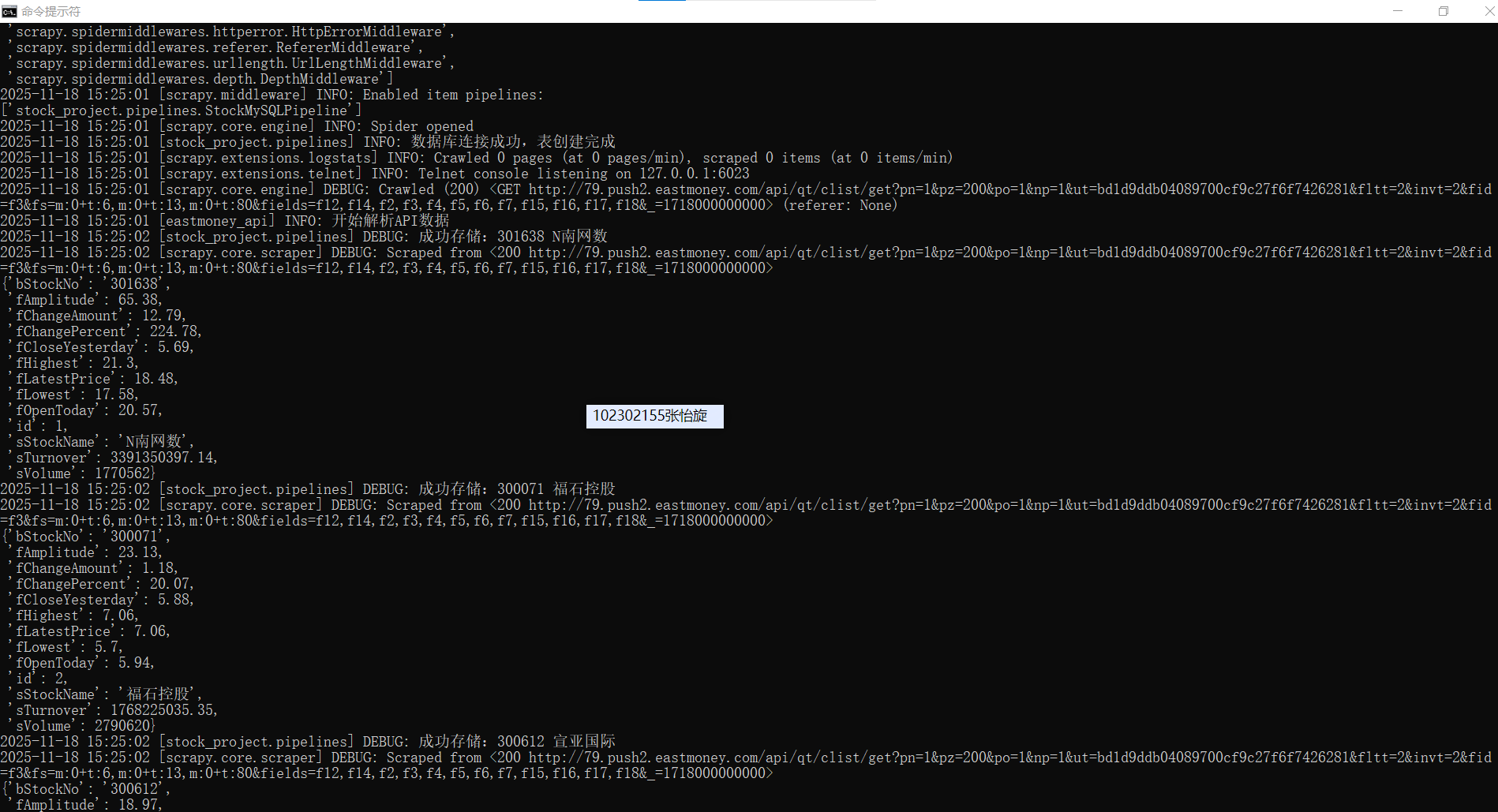
def parse(self, response):
self.logger.info("开始解析API数据")
# 解析JSON格式的响应数据
try:
data = json.loads(response.text)
# 提取股票列表
stock_list = data.get('data', {}).get('diff', [])
if not stock_list:
self.logger.error("API未返回股票数据,检查接口参数是否有效")
return
# 遍历股票数据,封装到Item
for idx, stock in enumerate(stock_list, 1):
item = StockItem()
# 字段映射
item['id'] = idx # 序号
item['bStockNo'] = str(stock.get('f12', '')).strip() # 股票代码
item['sStockName'] = str(stock.get('f14', '')).strip() # 股票名称
item['fLatestPrice'] = stock.get('f2', '') # 最新报价
item['fChangePercent'] = stock.get('f3', '') # 涨跌幅(%)
item['fChangeAmount'] = stock.get('f4', '') # 涨跌额
item['sVolume'] = stock.get('f5', '') # 成交量
item['sTurnover'] = stock.get('f6', '') # 成交额
item['fAmplitude'] = stock.get('f7', '') # 振幅(%)
item['fHighest'] = stock.get('f15', '') # 最高
item['fLowest'] = stock.get('f16', '') # 最低
item['fOpenToday'] = stock.get('f17', '') # 今开
item['fCloseYesterday'] = stock.get('f18', '') # 昨收
# 过滤无效数据(代码为空则跳过)
if item['bStockNo']:
yield item
else:
self.logger.warning(f"第{idx}条数据无股票代码,跳过")
self.logger.info(f"成功解析{len(stock_list)}条股票数据(第1页)")
except json.JSONDecodeError:
self.logger.error("API响应不是合法JSON格式,检查请求URL是否正确")
except Exception as e:
self.logger.error(f"解析API数据失败:{str(e)}")
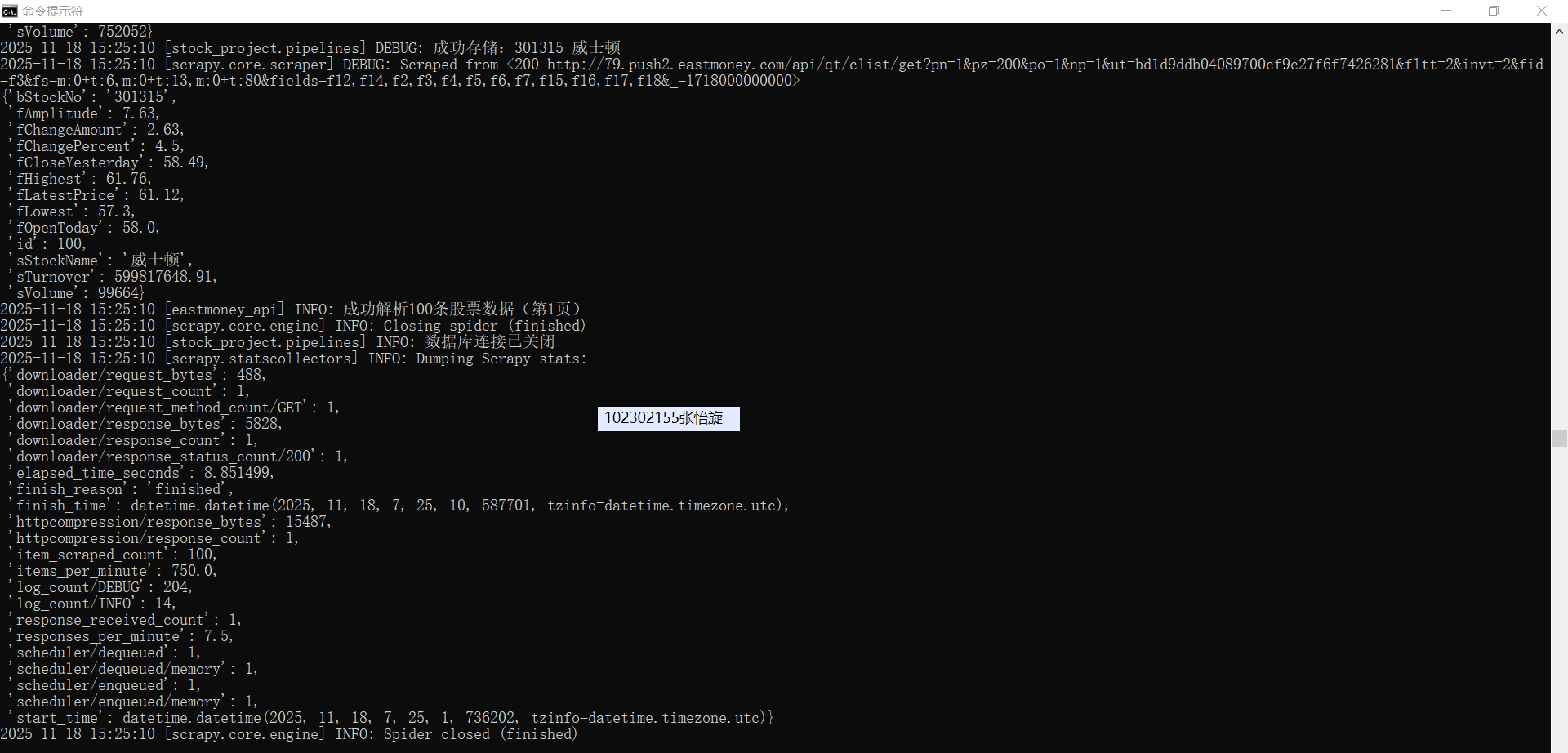
只展示了前20个数据
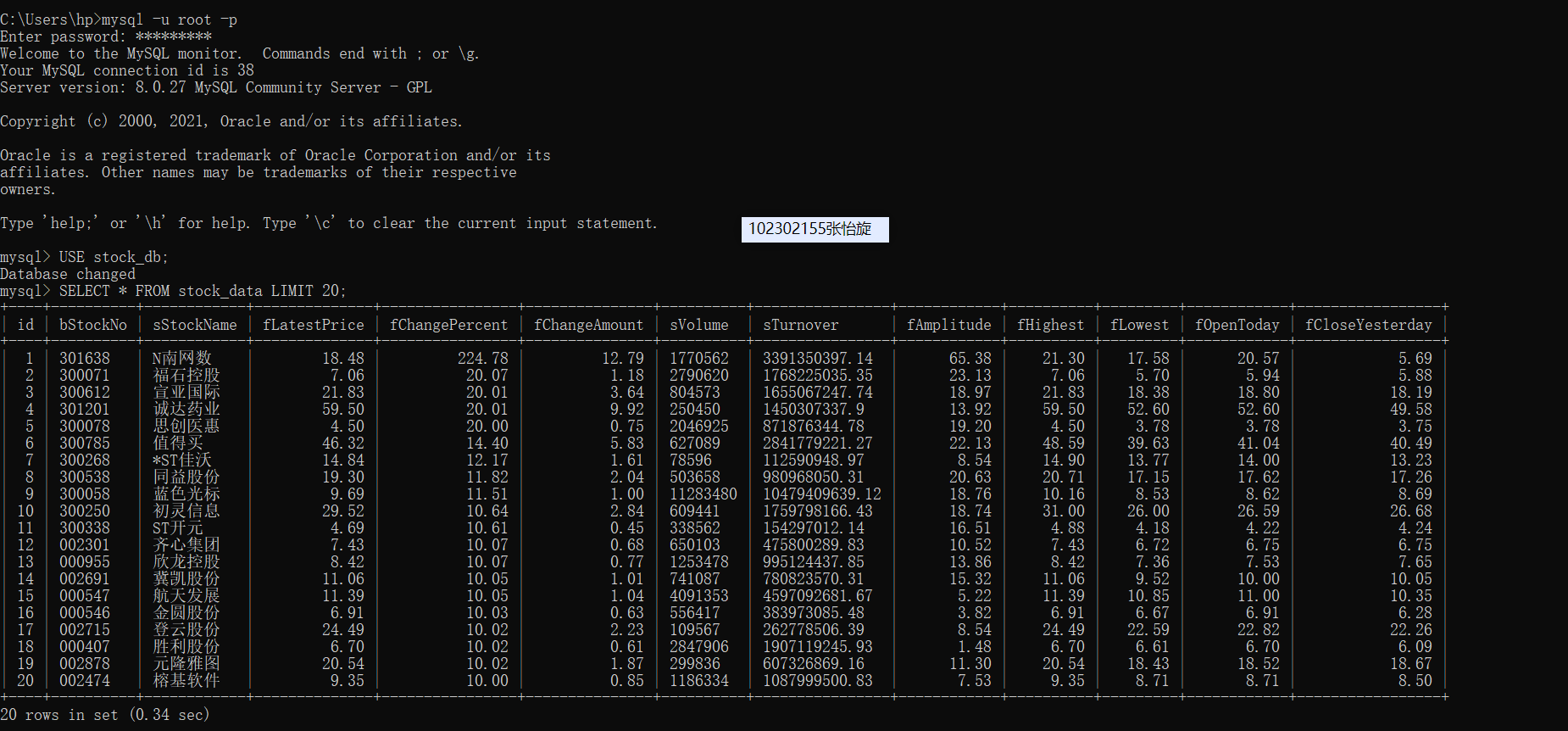
2.心得
在爬取前,我进入了该网站查看html的结构,发现是由tr和td构成的,然后找到相应的xpath进行爬取。
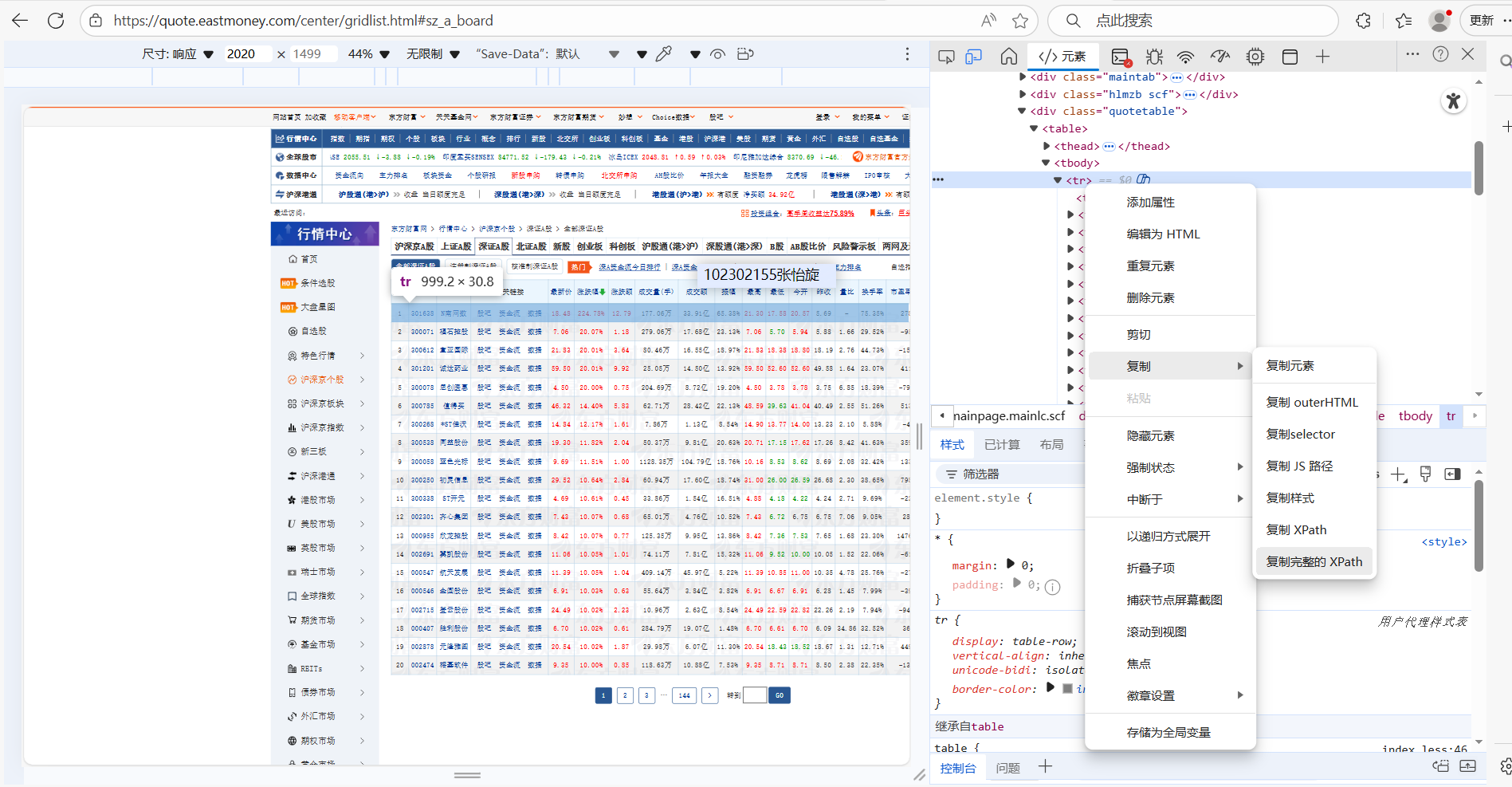
在爬取中发现XPath 匹配不到数据,一直找不到原因,然后借助大模型,发现目标页面是动态加载,初始 HTML 源码中没有tbody内的股票数据,导致静态 XPath 无效。后来改用动态加载的 API 接口,直接请求返回 JSON 数据的接口,才爬到了。但是检查发现部分数据存储成功,部分失败,又一次借助大模型,发现单条数据中存在异常值(如特殊符号、超长度字符串),导致 SQL 执行中断,然后在process_item中添加try-except捕获单条数据错误,不影响其他数据,最后才爬取出来。因为进行了许多次爬取,数据库里需要清空再运行才能成功储存。终于成功爬取出来。
Gitee文件夹链接:https://gitee.com/njs5/bgyuhnji/tree/homework3/gupiao/stock_project
作业三
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
输出信息:MySQL数据库存储
1.核心代码和运行结果
items.py的代码:
点击查看代码
import scrapy
class ForexItem(scrapy.Item):
"""外汇数据Item模型"""
currency = scrapy.Field() # 货币名称
tbp = scrapy.Field() # 现汇买入价
cbp = scrapy.Field() # 现钞买入价
tsp = scrapy.Field() # 现汇卖出价
csp = scrapy.Field() # 现钞卖出价
time = scrapy.Field() # 发布时间
点击查看代码
import pymysql
from itemadapter import ItemAdapter
class MySQLPipeline:
"""MySQL数据库存储管道"""
def __init__(self, host, port, user, password, database):
self.host = host
self.port = port
self.user = user
self.password = password
self.database = database
self.conn = None
self.cursor = None
@classmethod
def from_crawler(cls, crawler):
"""从配置文件获取数据库连接参数"""
return cls(
host=crawler.settings.get('MYSQL_HOST'),
port=crawler.settings.get('MYSQL_PORT'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
database=crawler.settings.get('MYSQL_DATABASE')
)
def open_spider(self, spider):
"""爬虫启动时建立数据库连接"""
self.conn = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
database=self.database,
charset='utf8mb4'
)
self.cursor = self.conn.cursor()
# 创建表(如果不存在)
create_table_sql = """
CREATE TABLE IF NOT EXISTS forex_data (
id INT AUTO_INCREMENT PRIMARY KEY,
currency VARCHAR(50) NOT NULL,
tbp DECIMAL(10,2),
cbp DECIMAL(10,2),
tsp DECIMAL(10,2),
csp DECIMAL(10,2),
time VARCHAR(20),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
"""
self.cursor.execute(create_table_sql)
self.conn.commit()
def process_item(self, item, spider):
adapter = ItemAdapter(item)
# 处理可能的空值,转换为数据库可接受的格式(如NULL)
insert_sql = """
INSERT INTO forex_data (currency, tbp, cbp, tsp, csp, time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
try:
self.cursor.execute(insert_sql, (
adapter['currency'] or None,
float(adapter['tbp']) if adapter['tbp'] else None,
float(adapter['cbp']) if adapter['cbp'] else None,
float(adapter['tsp']) if adapter['tsp'] else None,
float(adapter['csp']) if adapter['csp'] else None,
adapter['time'] or None
))
self.conn.commit()
except Exception as e:
self.conn.rollback()
spider.logger.error(f"插入数据失败: {e}")
return item
def close_spider(self, spider):
"""爬虫关闭时关闭数据库连接"""
if self.cursor:
self.cursor.close()
if self.conn:
self.conn.close()
点击查看代码
# 启用管道
ITEM_PIPELINES = {
'forex_scraper.pipelines.MySQLPipeline': 300,
}
# MySQL数据库配置
MYSQL_HOST = 'localhost'
MYSQL_PORT = 3306
MYSQL_USER = 'root'
MYSQL_PASSWORD = 'zyx051120' # MySQL密码
MYSQL_DATABASE = 'forex_db' # 数据库名称
# 请求头设置
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "forex_scraper (+http://www.yourdomain.com)"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Concurrency and throttling settings
#CONCURRENT_REQUESTS = 16
CONCURRENT_REQUESTS_PER_DOMAIN = 1
DOWNLOAD_DELAY = 2
点击查看代码
import scrapy
from ..items import ForexItem
class BocSpider(scrapy.Spider):
name = 'boc'
allowed_domains = ['www.boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
# 更精确的 XPath:定位到包含外汇数据的表格行
rows = response.xpath('//div[@class="publish"]//table[@cellspacing="0"]//tr')[1:]
for row in rows:
# 逐个字段提取并做空值判断
currency = row.xpath('./td[1]/text()').get()
tbp = row.xpath('./td[2]/text()').get()
cbp = row.xpath('./td[3]/text()').get()
tsp = row.xpath('./td[4]/text()').get()
csp = row.xpath('./td[5]/text()').get()
time = row.xpath('./td[8]/text()').get()
# 若关键字段(如货币名称)为空,跳过当前行
if not currency:
continue
item = ForexItem()
item['currency'] = currency.strip() if currency else ''
item['tbp'] = tbp.strip() if tbp else ''
item['cbp'] = cbp.strip() if cbp else ''
item['tsp'] = tsp.strip() if tsp else ''
item['csp'] = csp.strip() if csp else ''
item['time'] = time.strip() if time else ''
yield item
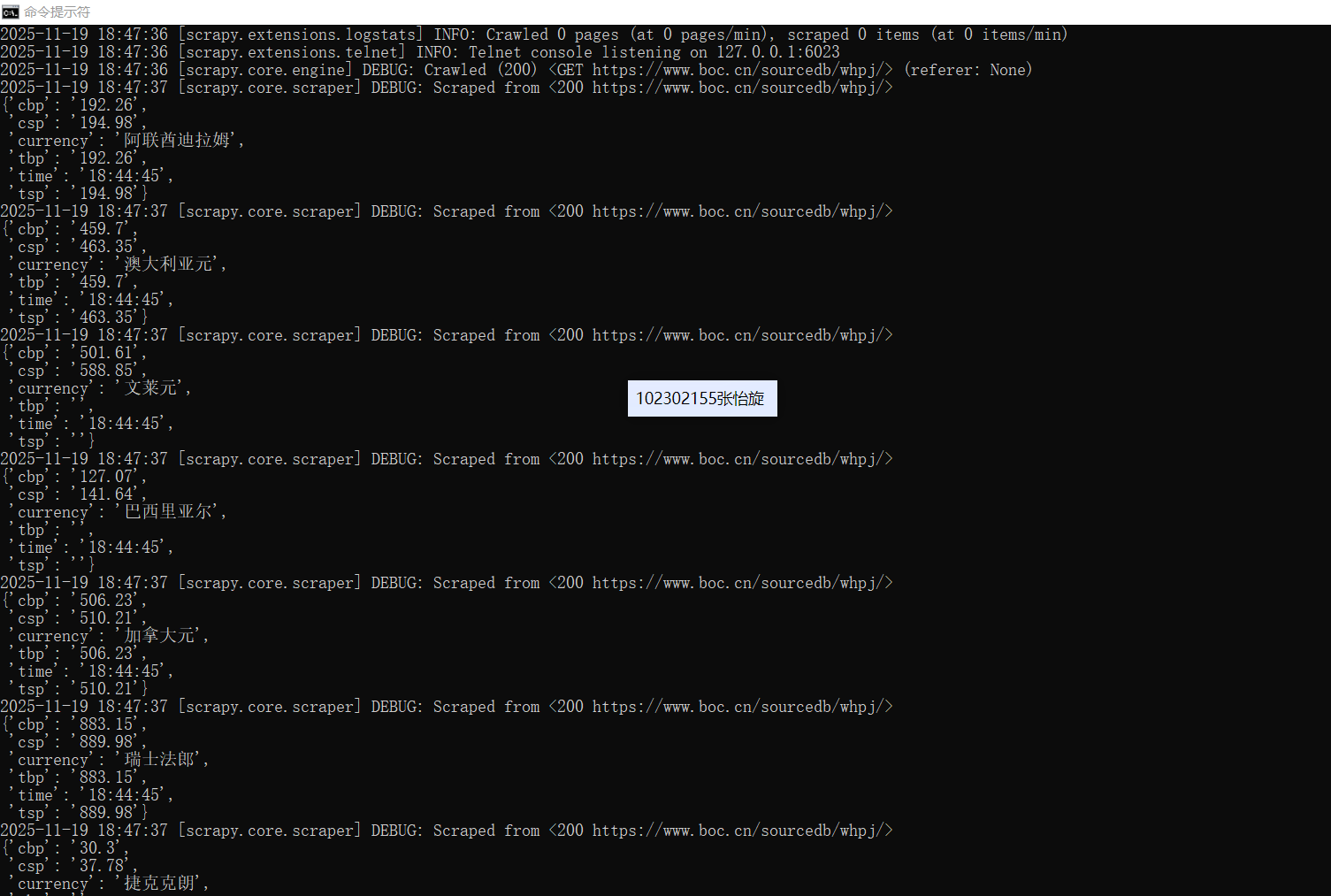
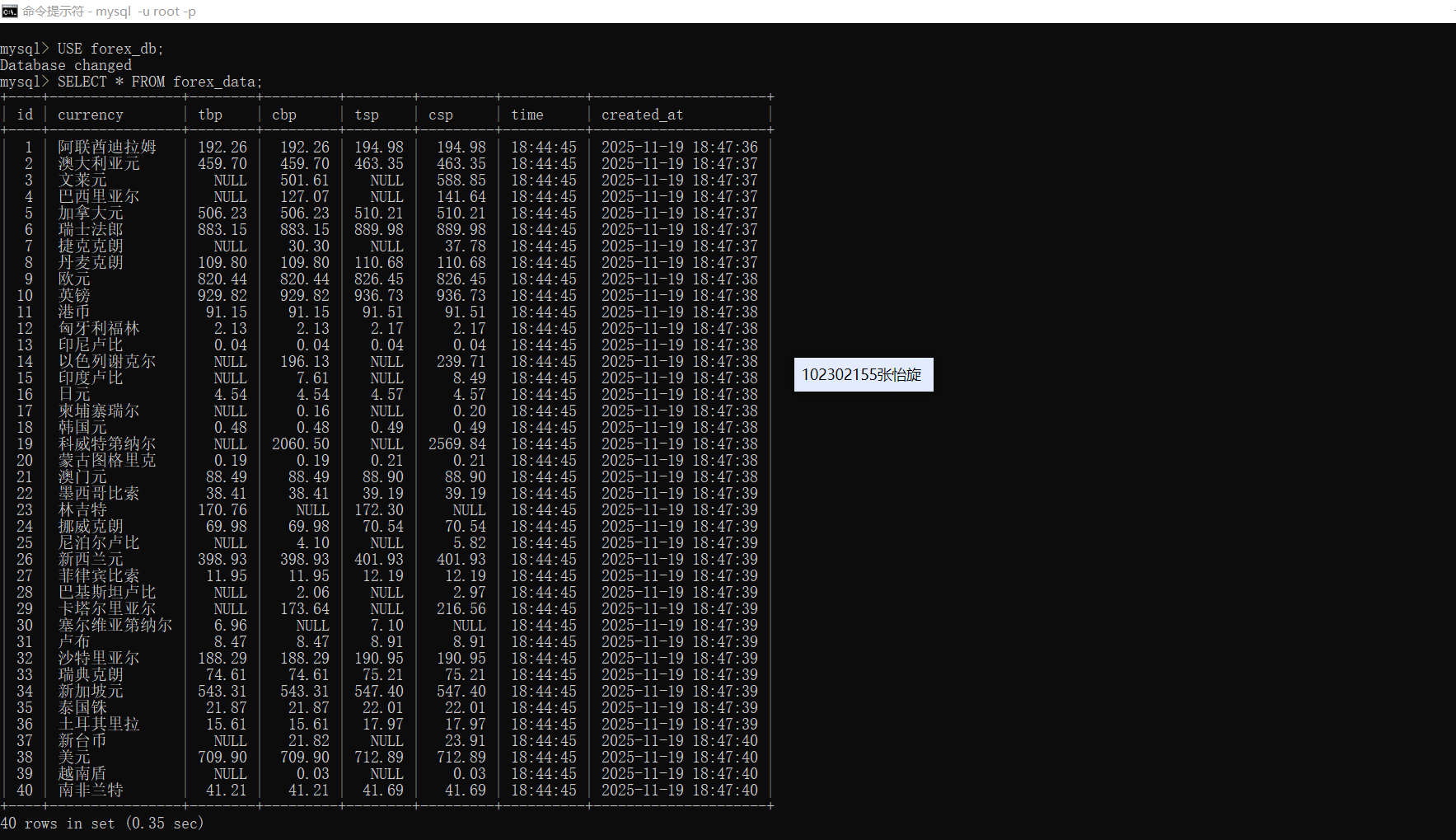
2.心得
首先,查看了网站结构,知道了表格的格式,然后提取相应的xpath来进行解析
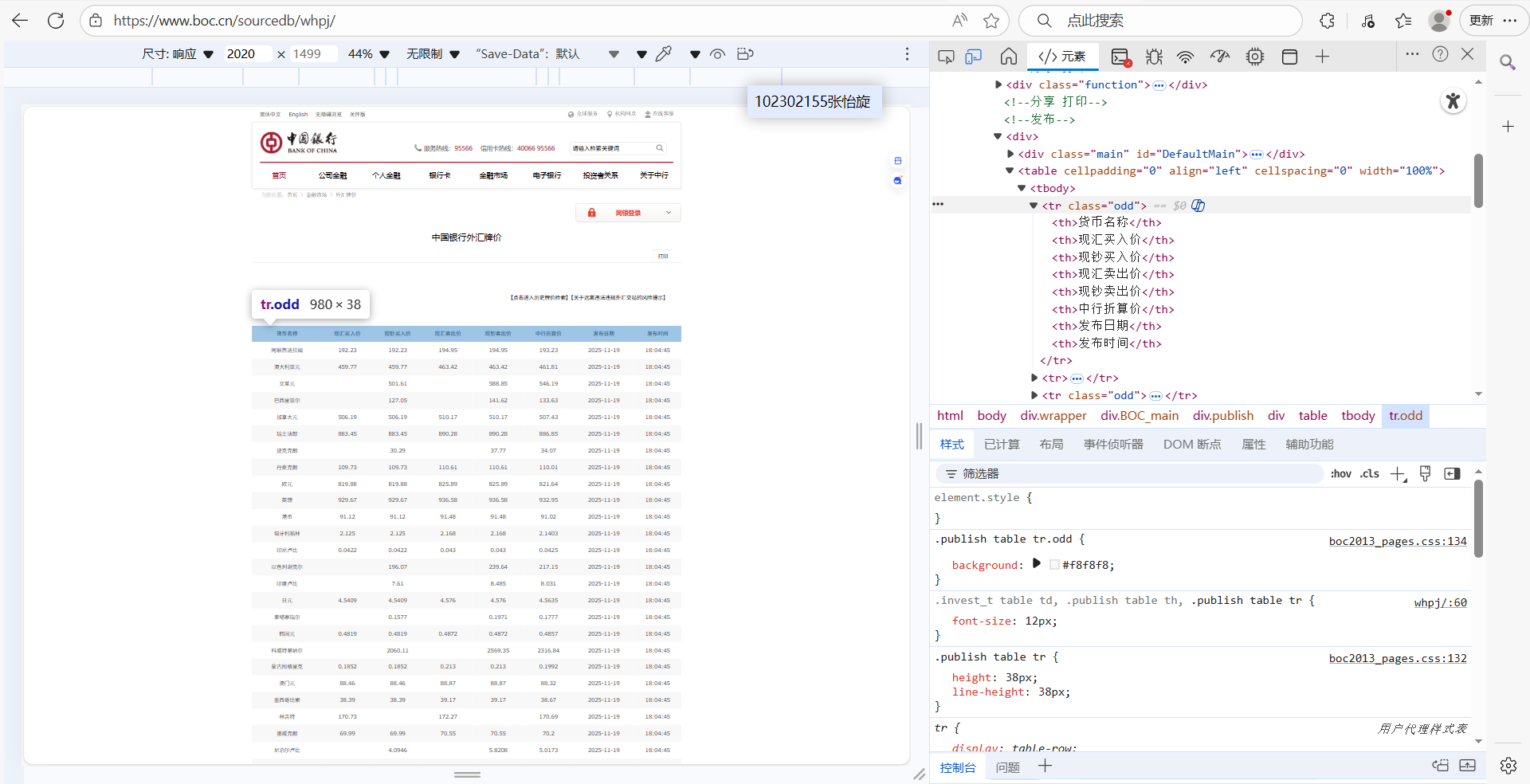
然后开始编写代码,总是在运行的时候爬不出任何数据,发现了同样的问题:目标数据被 JavaScript 动态加载,Scrapy 默认无法获取,然后进行修改,修改了好多遍,删了建,建了删,结果又出来mysql初始化失败,接着查看pipelines.py的代码,同样做了修改。但是仍然有错,后来发现有的表格中的值是空的,再次将代码进行了修改,最后成功爬取出来。
Gitee文件夹链接:https://gitee.com/njs5/bgyuhnji/tree/homework3/yinhang/forex_scraper

 浙公网安备 33010602011771号
浙公网安备 33010602011771号