mysql奇怪的not in和not exists
今天有个sql颠覆了我的三观,网上一直都说用exists的效率比in高,所以我第一时间是考虑用exists,可是因为数据量太大查不出来,领导改成in就查出来了,我觉得很神奇。

上图是两个sql,not in执行时间在4秒左右,not exists时间在60多秒。
下面是执行计划
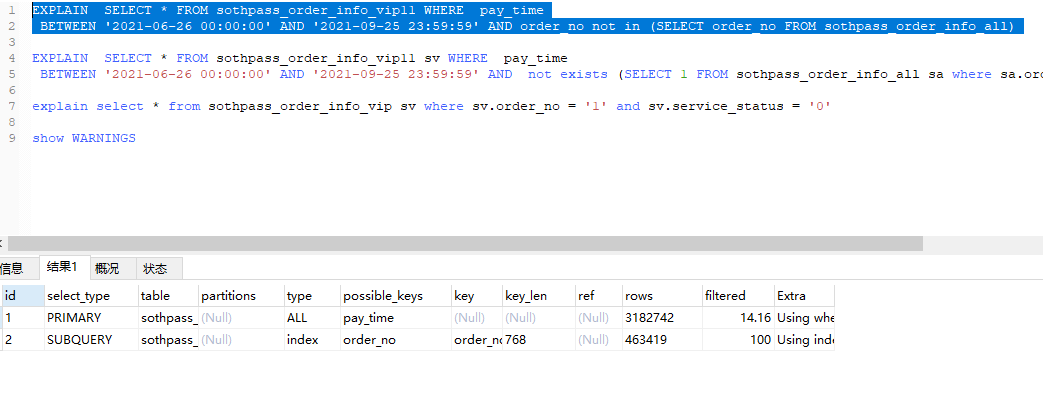
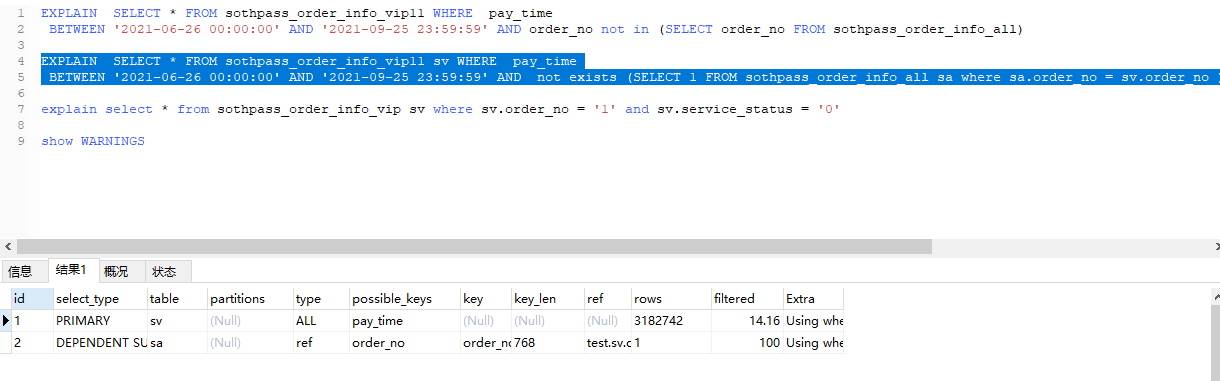
以上是我本地数据库的执行计划,更奇妙的是,我拉到测试环境之后,执行计划变了,可能是数据库版本原因。下面是测试环境的执行计划。
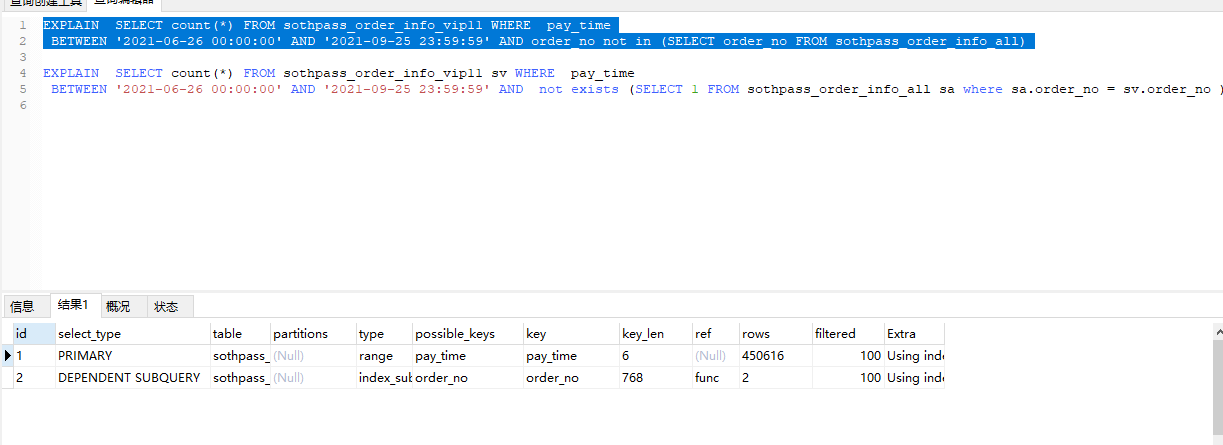
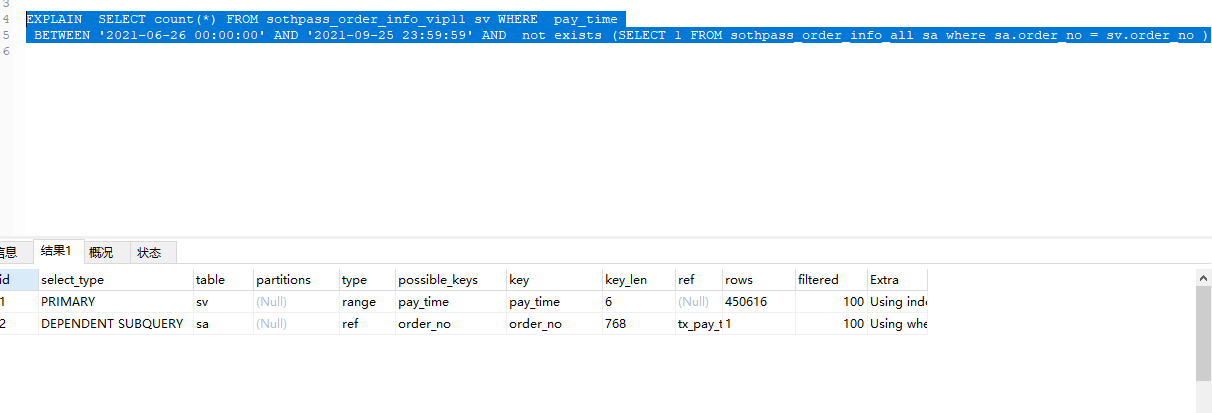
目前为止,还没找到为什么not in比not exists快,不过更快的方法是用left join关联。
猜想:
1、本地数据库和测试环境数据库的执行计划不同是因为数据库版本不同。
2、执行计划也不代表sql的具体实现,还要看sql优化器。
3、not in比not exists快可能是因为not in 先执行子查询一次,查出来50万数据再和主表关联对比,而not exists是要先查询主表,再一条一条数据遍历放到子查询中。
后面又出现这个not in比not exists快的情况。
直接通过explain extended关键字发现not in是通过sql优化器去优化了。
explain extended select * from kukai926
where order_no not in
(select order_no from boss926);
show WARNINGS;
优化后的SQL:
/* select#1 */ select `tx_pay_test`.`kukai926`.`order_no` AS `order_no`,`tx_pay_test`.`kukai926`.`pay_time` AS `pay_time`,`tx_pay_test`.`kukai926`.`pay_price` AS `pay_price` from `tx_pay_test`.`kukai926` where (not(<in_optimizer>(`tx_pay_test`.`kukai926`.`order_no`,<exists>(<index_lookup>(<cache>(`tx_pay_test`.`kukai926`.`order_no`) in boss926 on `order_no`)))))
标红的部分我们可以看到SQL优化器会用到索引缓存。
explain extended
select * from kukai926 k
where not exists
(select order_no from boss926 b where k.order_no = b.order_no);
show WARNINGS;
优化后的SQL:
/* select#1 */ select `tx_pay_test`.`k`.`order_no` AS `order_no`,`tx_pay_test`.`k`.`pay_time` AS `pay_time`,`tx_pay_test`.`k`.`pay_price` AS `pay_price` from `tx_pay_test`.`kukai926` `k` where (not(exists(/* select#2 */ select 1 from `tx_pay_test`.`boss926` `b` where (`tx_pay_test`.`k`.`order_no` = `tx_pay_test`.`b`.`order_no`))))
我们可以看到not in是用到索引的,但是not exists没用到,所以还是要看SQL优化器的具体实现,并不是网上说的NOT IN一定比NOT exists慢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号