
Kubernetes中各组件简介(一)
一、K8S的架构图
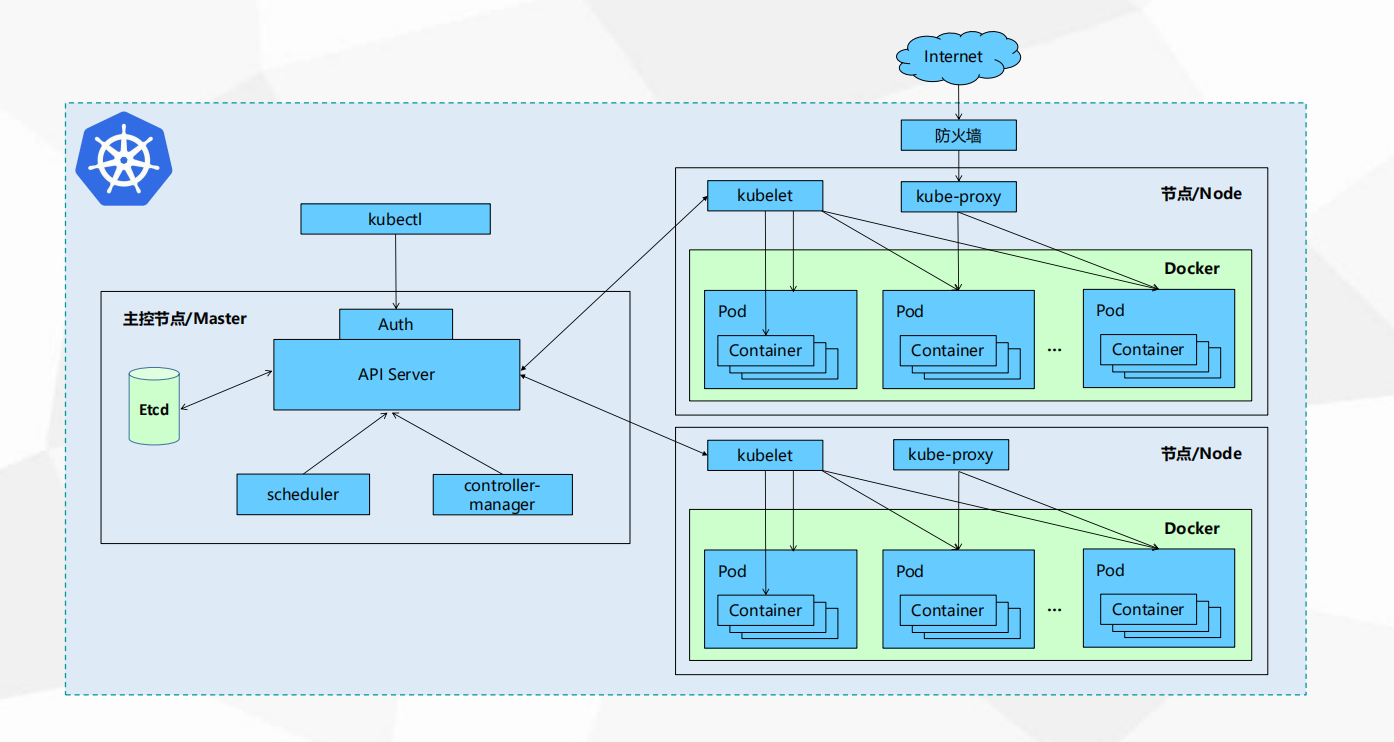
1,Master(管理节点)
kubectl:是客户端的管理工具。
API Server: 供Kubernetes API接口,主要处理Rest操作以及更新Etcd中的对象。所有资源增删改查的唯一入口。
Scheduler: 绑定Pod到Node上,资源调度。
Etcd:所有持久化的状态信息存储在Etcd中。
controller-manager:负责维护集群状态如故障检测,自动更新处理集群中常规后台任务,一个资源对应一个控制器,而ControllerManager就是负责管理这些控制器的。
2,Node(计算节点)
Kubelet:是Master在Node节点上的Agent,管理Pods以及容器、镜像、Volume等。
Kube-proxy:提供网络代理以及负载均衡,实现Service通讯。
二、Pod(资源池)
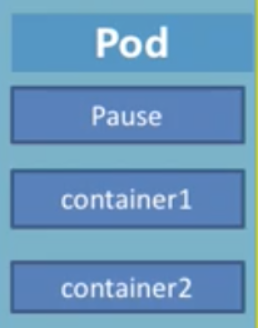 每个Pod都会存在一个Pause根容器,是每一个Pod都会去运行的,container即为应用程序,所以Pod就是根容器Pause和应用程序container所组成,在Pod当中可以运行多个小的容器的。
每个Pod都会存在一个Pause根容器,是每一个Pod都会去运行的,container即为应用程序,所以Pod就是根容器Pause和应用程序container所组成,在Pod当中可以运行多个小的容器的。
1,Pod组成的意义
- 使用Pause根容器可以防止由于将多个容器组成一个单元,当其中某个容器挂掉就会导致整个单元无法使用的情况发生。
- Pod可以运行过个container,这些container是共享Pause根容器的IP地址,也共享Pause的volume挂债卷,这样既简化了关联业务容器之间的通信问题,也很好的解决了容器之间共享的问题
- 在Kubernetes中的Pod之间是可以进行相互通信的,因为他们之间是一个二层交换的网络,所以不同主机之间Pod是可以进行相互访问的
2,Pod类型划分
静态Pod:不会将状态存放到Etcd存储数据库中,而是放到了某个Node上的具体文件当中,并且只有在这个Node上才能启动运行
普通Pod:普通Pod一旦被创建成功,那么Pod状态信息就会放到Etcd存储数据库当中,状态就会实时进行更新,就会被Master节点绑定到某个Node节点上进行调度和资源分配,随后Pod就放到了指定的Node上面,相当于把一个应用实例化成了一组相关Docker容器并启动去运行
3,Pod、容器与Node之间的关系
- 在Node当中运行着Pod,而在Pod当中是包含着容器。
- 在K8s当中都是以Docker镜像发布的,每个Pod可以理解为上面运行着多个镜像,在默认情况下,比如在Pod当中某个容器停止了,K8s会自动检查这个问题并重启这个Pod(即将Pod当中的所有容器全部重启)
- 如果Pod所在的Node宕机了,K8s会把Pod调度到其他的Node节点上
- Pod当中是可以运行多个应用的,即支持多容器运行,每一个Pod相当于一个资源池,Pod当中的容器可以共享IP和文件系统
三、其它资源对象
1,Replication Controller
通过定义RC来实现Pod的创建过程与自动控制,在RC当中包含着一个完整的Pod模板,通过Label标签机制对Pod实现自动控制:通过改变RC里面的Pod数量可以实现Pod的扩容和缩容;通过改变RC里面模板的镜像版本可以实现Pod的滚动升级功能。
2,Service
Kubernetes中一个应用服务会有一个或多个实例(Pod,Pod可以通过rs进行多复本的建立),每个实例(Pod)的IP地址由网络插件动态随机分配(Pod重启后IP地址会改变)。为屏蔽这些后端实例的动态变化和对多实例的负载均衡,引入了Service这个资源对象,如下所示:
apiVersion: v1 kind: Service metadata: name: nginx-svc labels: app: nginx spec: type: ClusterIP #clusterIP: None这种就是Headless Service ports: - port: 80 #svc端口 targetPort: 80 #目标后端端口 #nodePort: 30080 自定义nodePort端口 其中type要为NodePort类型 selector: #service通过selector和pod建立关联 app: nginx
根据创建Service的type类型不同,可分为4中模式:
-
ClusterIp:默认类型,自动分配一个仅 Cluster 内部可以访问的虚拟 IP。普通Service:通过为Kubernetes的Service分配一个集群内部可访问的
固定虚拟IP(Cluster IP);Headless Service:DNS会将headless service的后端直接解析为podIP列表。 -
NodePort:在 ClusterIP 基础上为 Service 在每台机器上绑定一个端口,这样就可以通过 : NodePort 来访问该服务。
-
LoadBalancer:在 NodePort 的基础上,借助 cloud provider 创建一个外部负载均衡器,并将请求转发到: NodePort 。
- ExternalName:把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建,这只有 kubernetes 1.7 或更高版本的 kube-dns 才支持
3,Deployment
Deployment是为了解决Pod编排的问题,在内部使用RS。部署表示用户对K8s集群的一次更新操作。可以是创建一个新的服务,更新一个新的服务,也可以是滚动升级一个服务。滚动升级一个服务,实际是创建一个新的RS,然后逐渐将新RS中副本数增加到理想状态,将旧RS中的副本数减小到0的复合操作;这样一个复合操作用一个RS是不太好描述的,所以用一个更通用的Deployment来描述。Deployment是RC最大的升级。
4,Replica Set
RS是新一代RC,提供同样的高可用能力,区别主要在于RS后来居上,能支持更多种类的匹配模式,副本集对象一般不单独使用,而是作为Deployment的理想状态参数使用。
5,DaemonSet
确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
使用 DaemonSet 的一些典型用法:运行集群存储 daemon,例如在每个 Node 上运行 glusterd、ceph;日志收集,比如fluentd,logstash等;系统监控,比如Prometheus Node Exporter,collectd,New Relic agent,Ganglia gmond等;系统程序,比如kube-proxy, kube-dns, glusterd, ceph等。
使用Fluentd收集日志的例子:
apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: fluentd spec: template: metadata: labels: app: logging id: fluentd name: fluentd spec: containers: - name: fluentd-es image: gcr.io/google_containers/fluentd-elasticsearch:1.3 env: - name: FLUENTD_ARGS value: -qq volumeMounts: - name: containers mountPath: /var/lib/docker/containers - name: varlog mountPath: /varlog volumes: - hostPath: path: /var/lib/docker/containers name: containers - hostPath: path: /var/log name: varlog

 浙公网安备 33010602011771号
浙公网安备 33010602011771号