【数据采集与融合技术】第五次大作业
【数据采集与融合技术】第五次大作业
【数据采集与融合技术】第五次大作业
「数据采集」实验五
一、作业①
1.1 题目
要求:
-
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
-
使用Selenium框架爬取京东商城某类商品信息及图片。
-
候选网站:http://www.jd.com/
-
关键词:学生自由选择
-
输出信息:MYSQL的输出信息如下
mNo mMark mPrice mNote mFile 000001 三星Galaxy 9199.00 三星Galaxy Note20 Ultra 5G... 000001.jpg 000002......
1.2 代码及思路
5/5-1.py · 灰色/2019级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
1.2.1 预先准备
首先登录一次www.jd.com,并用浏览器的F12功能抓包服务器发回的信息,保存其中的cookies为jd_cookies用于模拟登录使用

由于保存下来的cookies是一大段字符串,因此编写getCookies函数将其转为字典
def getCookies(ck):
manual_cookies = {}
cookies_txt = ck.read().strip(';') # 读取文本内容
# 手动分割添加cookie
for item in cookies_txt.split(';'):
name, value = item.strip().split('=', 1) # 用=号分割,分割1次
manual_cookies[name] = value # 为字典cookies添加内容
return manual_cookies
1.2.2 配置模拟chrome浏览器的相关设置
#设置启动时浏览器不可见
from selenium.webdriver.common.by import By
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
1.2.3 创建浏览器并模拟登录
用deiver.add_cookie方法可以使模拟浏览器的请求带上cookies,同时也可以配置头文件
#创建chrome浏览器
driver= webdriver.Chrome() #不带参数显式地展示爬取过程
#用cookies模拟登录
jd_cookies=open("jd_cookies.txt",'r',encoding='utf-8')
cookies=getCookies(jd_cookies)
jd_cookies.close()
for key in cookies.keys():
driver.add_cookie
(
{
'domain': '.jd.com', # 此处xxx.com前,需要带点
'name': key,
'value': cookies[key],
'path': '/',
'expires': None
}
)
1.2.4 访问要搜索的页面
首先用Xpath-helper找到输入框,用send_keys()方法模拟键盘键入关键词。再用click()方法模拟对【搜索】按钮的点击,其中time.sleep(2)
是为了让跳转后的页面加载完成在进行爬取。
#使用driver.get(url)方法访问网页
url="https://www.jd.com/"
driver.get(url)
time.sleep(2)
#跳转到要搜索的页面
search=driver.find_element(By.XPATH, "//input[@id='key']")
search.send_keys("显卡")
driver.find_element(By.XPATH, '//*[@id="search"]/div/div[2]/button').click()
time.sleep(2)
1.2.5 编写数据库类
class SPDB:
def openDB(self):
self.con=sqlite3.connect("sp.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table sp (id varchar(8),sMark varchar(16),sPrice varchar(16),"
"sNote varchar(32),sFile varchar(128))")
except:
self.cursor.execute("delete from sp")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, var1,var2,var3,var4,var5):
try:
self.cursor.execute("insert into sp (id, sMark, sPrice, sNOte, sFile) values (?,?,?,?,?)",
(var1,var2,var3,var4,var5))
except Exception as err:
print(err)
1.2.6 爬取三页商品信息
#开始爬取:共爬取三页
db=SPDB()
db.openDB()
cnt=1
for i in range(2):
goodsList=driver.find_elements(By.XPATH, "//div[@class='gl-i-wrap']")
for j in goodsList:
name=j.find_element(By.XPATH, "./div[@class='p-name p-name-type-2']/a/em")
sMark=name.text.split()[0]
sNote=name.text
sPrice=j.find_element(By.XPATH, "./div[@class='p-price']/strong/i").text
sFile=j.find_element(By.XPATH,"./div[@class='p-img']/a/img").get_attribute('src')
#print(cnt,sMark,sPrice,sNote,sFile)
db.insert(cnt,sMark,sPrice,sNote,sFile)
cnt+=1
if i!=0:
#点击下一页
driver.find_element(By.XPATH, "//div[@id='J_bottomPage']/span[@class='p-num']/a[@class='pn-next']/em").click()
db.closeDB()
1.3 运行结果
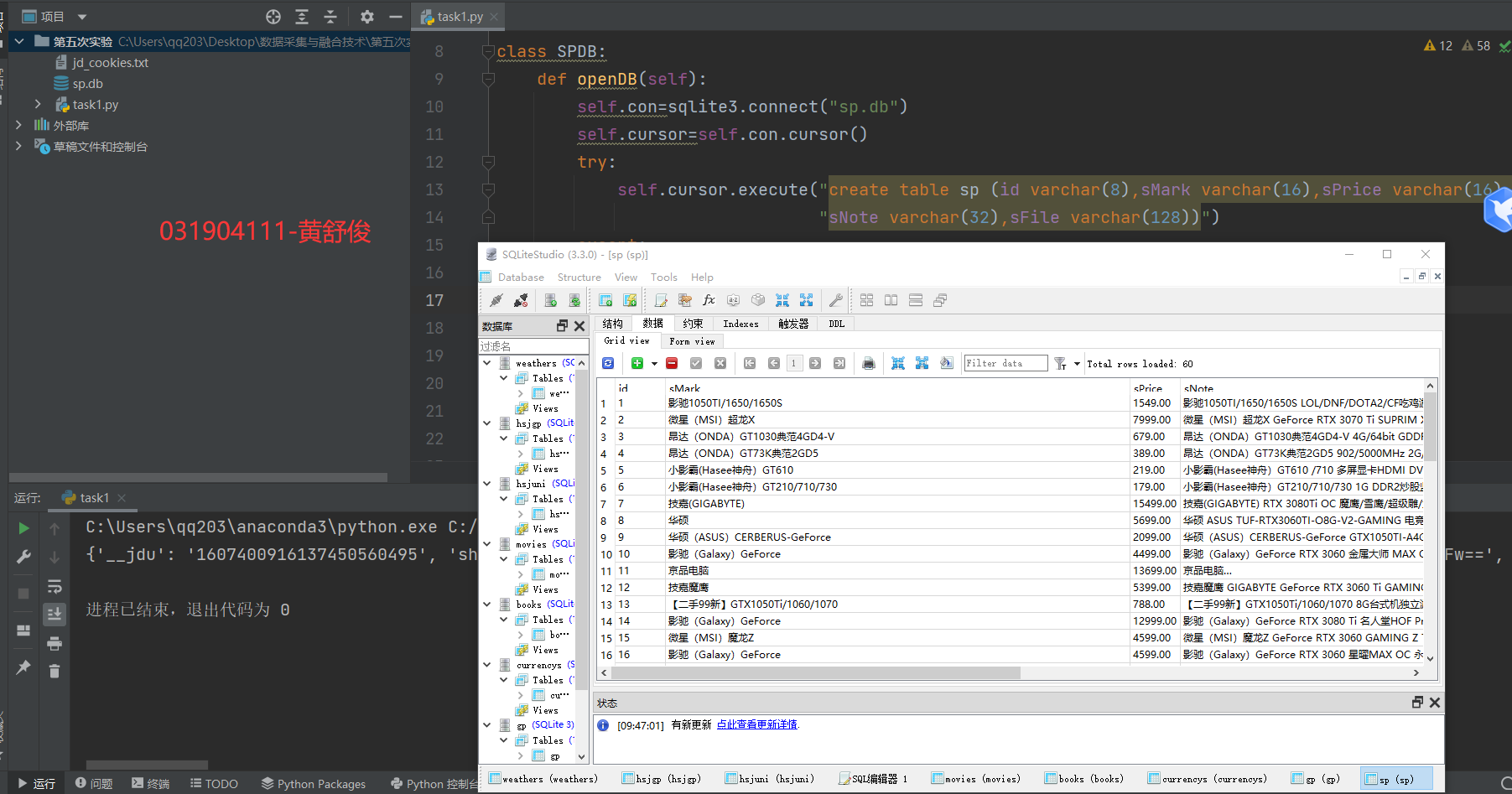
1.4 心得体会
●善用time.sleep(),有时候爬取的 太快页面还没加载完成会爬取出错误的结果
●模拟登录用模拟输入账号密码会过不了人机验证,用cookies即可
●京东商城一页的商品要用模拟滑动条下拉才能显示完全,但因为技术问题暂未实现
二、作业②
2.1 题目
要求:
-
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
-
使用Selenium框架+MySQL模拟登录慕课网,并获取学生自己账户中已学课程的信息保存到MySQL中(课程号、课程名称、授课单位、教学进度、课程状态,课程图片地址),同时存储图片到本地项目根目录下的imgs文件夹中,图片的名称用课程名来存储。
-
候选网站:中国mooc网:https://www.icourse163.org
-
输出信息:MYSQL数据库存储和输出格式
表头应是英文命名例如:课程号ID,课程名称:cCourse……,由同学们自行定义设计表头:
Id cCourse cCollege cSchedule cCourseStatus cImgUrl 1 Python网络爬虫与信息提取 北京理工大学 已学3/18课时 2021年5月18日已结束 http://edu-image.nosdn.127.net/C0AB6FA791150F0DFC0946B9A01C8CB2.jpg 2......
2.2 思路及代码
5/5-2.py · 灰色/2019级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
2.2.1 预先准备
进入中国慕课网,点击【登录|注册】扫码登陆后点击【个人中心】,即可看到自己所选的全部课程。每个课程有【课程名字】、【开课院校】、【目前学时】、【课程状态】四个信息,再加上课程图标url链接,作为爬取的目标属性,即表头。
2.2.2 配置模拟chrome浏览器的相关设置
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
2.2.3 创建浏览器并模拟登录
这里采用点击登录按钮后,使用time.sleep(10)等待一段时间用手机扫码人工登录实现登录功能,自动化程度不足
#创建chrome浏览器
driver= webdriver.Chrome()
#使用driver.get(url)方法访问网页
url="https://www.icourse163.org/"
driver.get(url)
time.sleep(2)
driver.find_element(By.XPATH,"//div[@class='unlogin']/a").click()
time.sleep(5)
driver.find_element(By.XPATH,"//div[@class='ga-click u-navLogin-myCourse u-navLogin-center-container']/a").click()
time.sleep(5)
2.2.4 数据库类
class SPDB:
def openDB(self):
self.con=sqlite3.connect("sp.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table sp (id varchar(8),sMark varchar(16),sPrice varchar(16),"
"sNote varchar(32),sFile varchar(128))")
except:
self.cursor.execute("delete from sp")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, var1,var2,var3,var4,var5):
try:
self.cursor.execute("insert into sp (id, sMark, sPrice, sNOte, sFile) values (?,?,?,?,?)",
(var1,var2,var3,var4,var5))
except Exception as err:
print(err)
2.2.5 开始爬取
sp=SPDB()
sp.openDB()
#开始爬取
courses=driver.find_elements(By.XPATH,'//div[@class="course-card-wrapper"]')
for course in courses:
name=course.find_element(By.XPATH,".//span[@class='text']").text
college=course.find_element(By.XPATH,".//div[@class='school']/a").text
schedule=course.find_element(By.XPATH, ".//a/span[@class='course-progress-text-span']").text
status=course.find_element(By.XPATH, ".//div[@class='course-status']").text
src=course.find_element(By.XPATH, ".//div[@class='img']/img").get_attribute("src")
sp.insert(name,college,schedule,status,src)
sp.closeDB()
2.3 运行结果
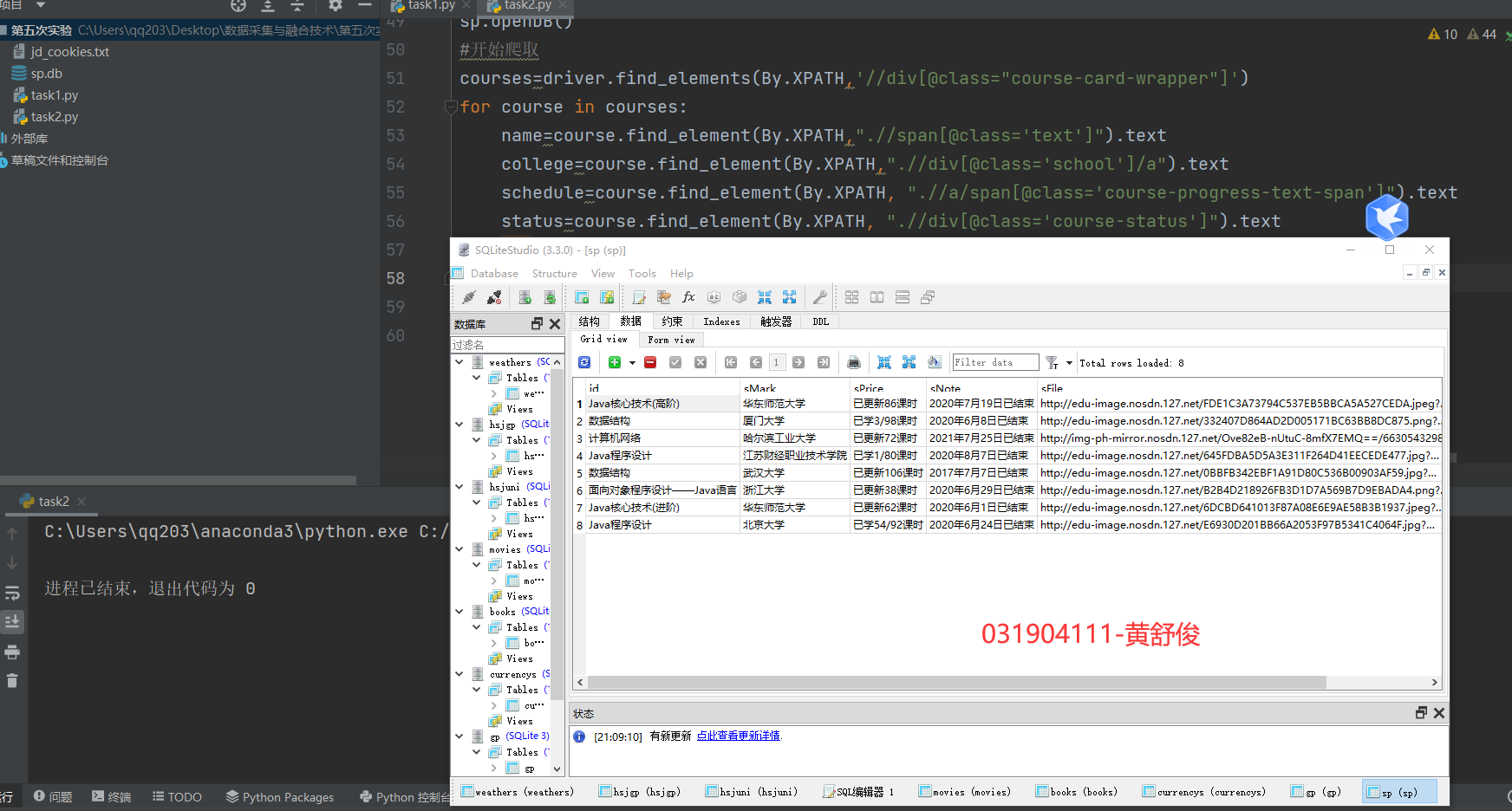
2.4 心得体会
●有的网站难以绕过人机验证,实验人工的方式辅助爬取也是可行的
●爬取前先观察页面元素的Xpath结构可以让爬取事半功倍
三、作业②
3.1 题目
-
要求:
掌握大数据相关服务,熟悉Xshell的使用
- 完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
- 环境搭建
- 任务一:开通MapReduce服务
- 实时分析开发实战
- 任务一:Python脚本生成测试数据
- 任务二:配置Kafka
- 任务三:安装Flume客户端
- 任务四:配置Flume采集数据
3.2 代码及思路
无
3.3 运行结果
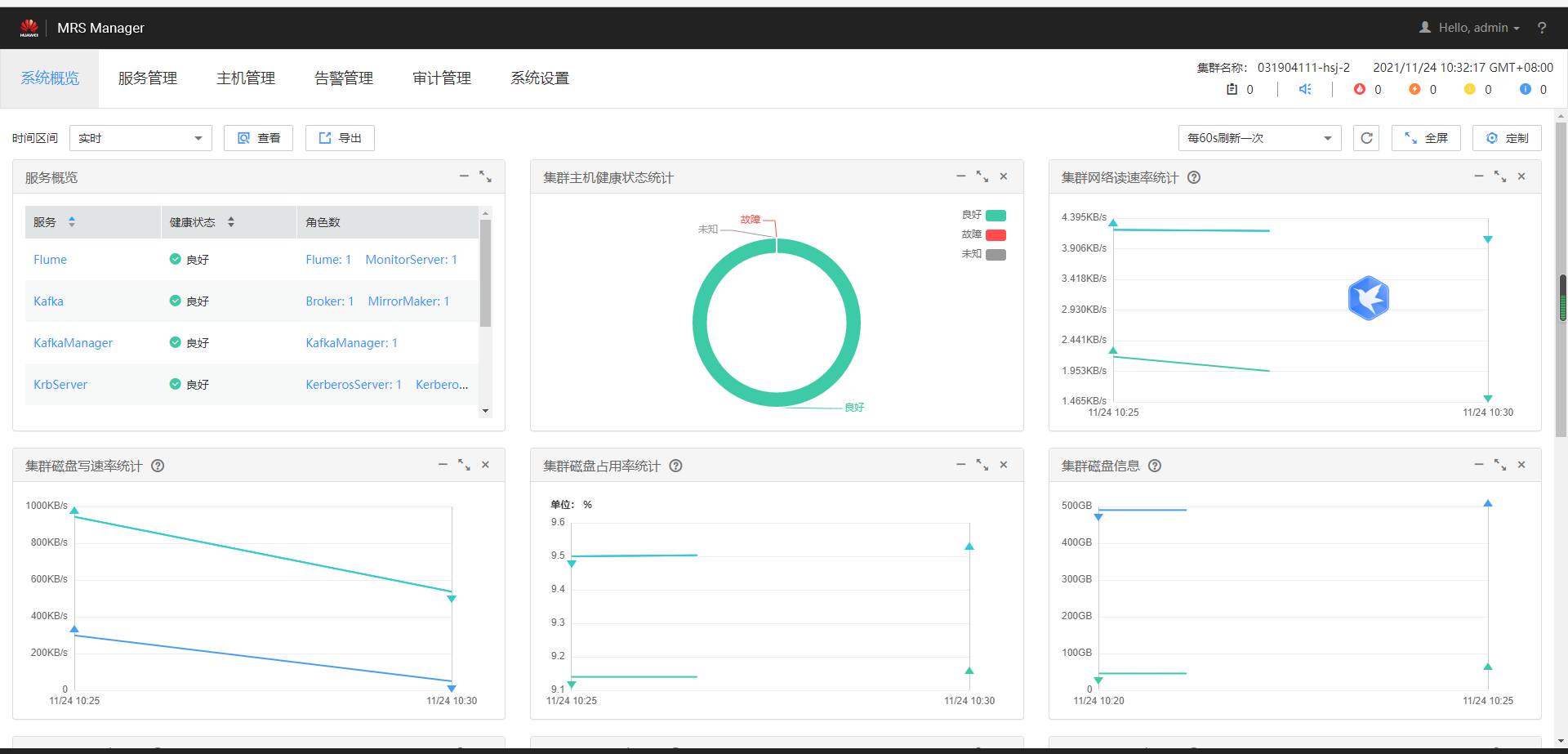
环境搭建:
任务一:开通MapReduce服务
实时分析开发实战
任务一:Python脚本生成测试数据
1、使用Xshell 7连接服务器,进入/opt/client/目录,用xftp7将本地的autodatapython.py文件上传至服务器/opt/client/目录下。
2、创建目录,使用mkdir命令在/tmp下创建目录flume_spooldir,我们把Python脚本模拟生成的数据放到此目录下,后面Flume就监控这个文件下的目录,以读取数据。
3、测试执行,执行Python命令,测试生成100条数据,查看数据。
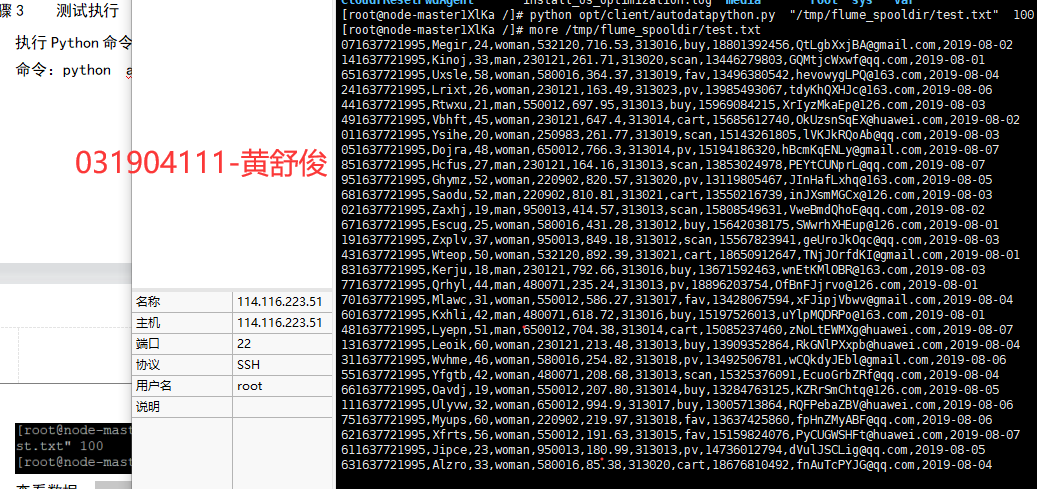
任务二:配置Kafka
1、设置环境变量,执行source命令,使变量生效
2、在kafka中创建topic
3、查看topic信息

任务四:安装Flume客户端
1、进入MRS Manager集群管理界面,打开服务管理,点击flume,进入Flume服务,点击下载客户端
2、解压下载的flume客户端文件。使用Xshell7登录到上步中的弹性服务器上,进入/tmp/MRS-client目录,解压压缩包获取校验文件与客户端配置包,校验文件包,解压“MRS_Flume_ClientConfig.tar”文件。
3、安装客户端运行环境到新的目录“/opt/Flumeenv”,安装时自动生成目录。查看安装输出信息,如有以下结果表示客户端运行环境安装成功
4、配置环境变量,解压Flume客户端
5、安装Flume到新目录”/opt/FlumeClient”,安装时自动生成目录

任务五:配置Flume采集数据
1、修改配置文件,创建消费者消费kafka中的数据。执行完毕后,在新开一个Xshell 7窗口(右键相应会话-->在右选项卡组中打开),执行2.2.1步骤三的Python脚本命令,再生成一份数据,查看Kafka中是否有数据产生,可以看到,已经消费出数据了:
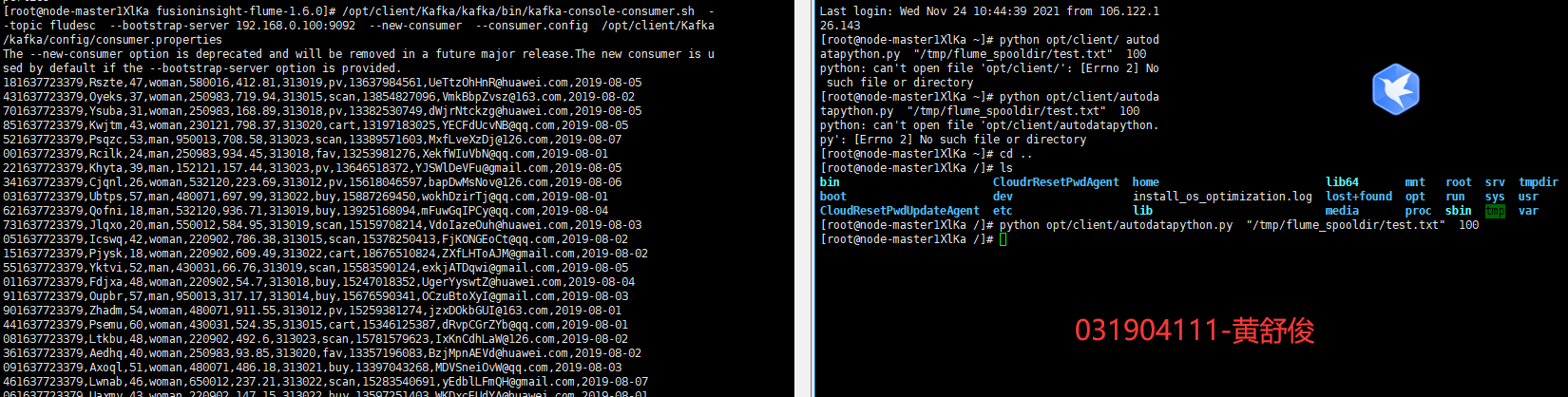
3.4 心得体会
本次实验作业完成了Flume环境的配置,方便数据处理以及相关可视化。实现了Mapreduce流式计算环境的搭建,在大数据时代增强了处理数据,获取数据的能力。

