【数据采集与融合技术】 第一次大作业
「数据采集」实验一
一、作业①
1.1 题目
- 要求:用
urllib和re库方法定向爬取给定网址中国最好学科排名(计算机科学与技术)的数据。 - 输出形式:
| 2020排名 | 全部层次 | 学校类型 | 总分 |
|---|---|---|---|
| 1 | 前2% | 中国人民大学 | 1069.0 |
| 2 | .... | ........... | ...... |
1.2 代码及思路
●码云链接:1/1.py · 灰色/2019级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
1.2.1 获取网页源码
def getUrllibRequest(url, header):
try:
req = request.Request(url, headers=header) # 构建一个Request请求类
resp = request.urlopen(req) # urlopen():实现最基本请求的发起,默认使用GET方式对网站发起请求。
#print(resp.status) # resp.status()返回状态码
if resp.status == 200:
data = resp.read() # 将二进制转为字节流
dammit = UnicodeDammit(data,["utf-8","gbk"]) # 将字节流解码为utf-8
data=dammit.unicode_markup
#soup=BeautifulSoup(data,'lxml')
#return soup
return data
else:
return "1"
except:
return "2"
url = "https://www.shanghairanking.cn/rankings/bcsr/2020/0812"
header = {"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'} #封装请求头
html=getUrllibRequest(url, header)
#print(html)
1.2.2 爬取目标属性
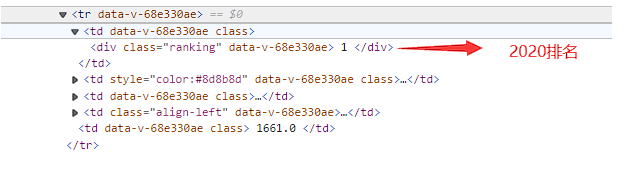
可以看到一个tr对应一个大学,由于re.search在一个字符串中搜索匹配正则表达式的第一个位置,于是应该先去除表头,并且每次爬取完更新html
去除表头
h=html
output=[] #输出列表
#去除表头
a=re.search(r'<tr data-v-68e330ae>',html)
b=re.search(r'</tr>',html)
if a!=None and b!=None:
h=h[b.end():]
基于re库提取目标tag内容
def getContent(ht,tag1,tag2): #ht:待匹配的文本,tag1:起始tag,tag2:结尾tag
a=re.search(tag1,ht)
b=re.search(tag2,ht)
start = a.end()
end = b.start()
return ht[start:end],ht[b.end():] #返回目标tag对之间的字符串以及去掉目标tag之后新的文本
爬取目标属性
各个属性爬取思路如下
按顺序各个属性排列如下,每个属性都是一个'td'tag,注意每爬取一个属性后要更新html
●2020排名:先定位起始tag:re.search(r'<td data-v-68e330ae.*?>',html), 结束 tag:re.search(r'',html),这个tag下的
tag 的text即为排名
●层次:起始tag:re.search(r'<td data-v-68e330ae.*?>',html), 结束 tag:re.search(r'',html)
●学校名称:先定位起始tag:re.search(r'<td class="align-left" data-v-68e330ae.*?>',html), 结束 tag:re.search(r'',html),这 个tag下的tag的text即为排名
●总分:起始tag:re.search(r'<td data-v-68e330ae.*?>',html), 结束 tag:re.search(r'',html)
#a,b之间为一个大学的信息
a=re.search(r'<tr data-v-68e330ae>',h)
b=re.search(r'</tr>',h)
while(a!=None and b!=None):
tem = []
garbage=""#无用字符串
start = a.end()
end = b.start()
t=h[start:end]
#爬取2020排名
rr,t=getContent(t,r'<td data-v-68e330ae.*?>',r'</td>')
rank,garbage=getContent(rr,r'<div class=.*?>',r'</div>')
rank_2020=rank.strip()
tem.append(rank_2020)
#爬取2019排名
rank,t=getContent(t,r'<td data-v-68e330ae.*?>',r'</td>')
#爬取全部层次
cc,t=getContent(t,r'<td data-v-68e330ae.*?>',r'</td>')
cc=cc.strip()[0:3]
tem.append(cc)
#爬取学校名称
nn,t=getContent(t,r'<td class="align-left" data-v-68e330ae.*?>',r'</td>')
name,garbage=getContent(nn,r'<a.*?>',r'</a>')
tem.append(name)
#爬取总分
score,t=getContent(t,r'<td data-v-68e330ae.*?>',r'</td>')
tem.append(score.strip())
output.append(tem)
#更新html
h=h[b.end():]
a=re.search(r'<tr data-v-68e330ae>',h)
b=re.search(r'</tr>',h)
1.2.3 输出对齐
def printUnivList(ulist, num):
#中西文混排时,要使用中文字符空格填充chr(12288)
tplt = "{0:^8}\t{1:{4}^10}\t{2:{4}^10}\t{3:{4}^10}\t"
#对中文输出的列,进行用第5个参数即中文空格chr(12288)填充
print("2020排名 全部层次 学校类型 总分")
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], u[3],chr(12288)))
输出如下

1.3 心得体会
●使用正则表达式匹配时‘?’实现非贪婪匹配更有助于精确的匹配目标,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。
●使用正则表达式匹配时要在目标字符串前加'r'代表原生字符串。
二、作业②
2.1 题目
- 要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
- 输出信息:
| 序号 | 城市 | AQI | PM2.5 | SO2 | No2 | Co | 首要污染物 |
|---|---|---|---|---|---|---|---|
| 1 | 北京 | 55 | 6 | 5 | 1.0 | 225 | — |
| 2...... |
2.2 代码及思路
●码云链接:1/2.py · 灰色/2019级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
2.2.1 准备工作
打开网页,用浏览器的F12工具查看各个元素对应的html代码

可以发现一个'tr'tag对应一座城市的信息,进一步发现
s=soup.select("tr")
s[0].text.split()

发现tr.text.split()即为一个城市各个空气指标的列表
2.2.1 输出结果

2.3 心得体会
●先分析html标签树的结构再进行爬取会让爬取工作事半功倍
●对齐时要注意全角空格和半角空格占位不同,gbk编码和utf-8编码的中文占位不同
三、作业③
3.1 题目
- 要求:使用urllib和requests爬取(https://news.fzu.edu.cn/),并爬取该网站下的所有图片
- 输出信息:将网页内的所有图片文件保存在一个文件夹中
3.2 代码及思路
●码云链接:[1/3.py · 灰色/2019级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
3.2.1 准备工作
注意到这个网页采用的是http协议而非https协议
获取网页html代码并用bs4库转换为soup对象
r = requests.get("http://news.fzu.edu.cn") #获取二进制流
r.encoding= r.apparent_encoding #使用r.encoding="utf-8"会出现编码错误
demo = r.text
soup = BeautifulSoup(demo,"lxml")
单纯使用r.encoding="utf-8"时会出现部分中文无法解码的情况,因此采用r.apparent_encoding有bs4库自动判定采用的编码
从标签树获取图片的url
urls=[]
s=soup.select("img[src$='jpg']") #定位含有src属性且以jpg为结尾的<img>tag
for pic in s:
url="http://news.fzu.edu.cn"+pic["src"] #拼接得到完整图片路径
urls.append(url)
保存图片到指定路径
# 保存图片到指定路径
path = r"C:\Users\qq203\Desktop\数据采集与融合技术\第一次实验\图片"
cnt = 1
for url in urls:
resp = requests.get(url) # 获取指定图片的二进制文本
img = resp.content
with open(path + '\\image%d_' % cnt + '.jpg', 'wb') as f: #写入本地路径
f.write(img)
print("第%d张图片下载成功" % cnt)
cnt += 1
用requests.get或urllib.request.urlretrieve(url,path)都可以将指定路径的图片下载到指定路径
3.2.2 输出结果

