TCP/IP 协议栈在 Linux 内核中的 运行时序分析
1.linux内核简介
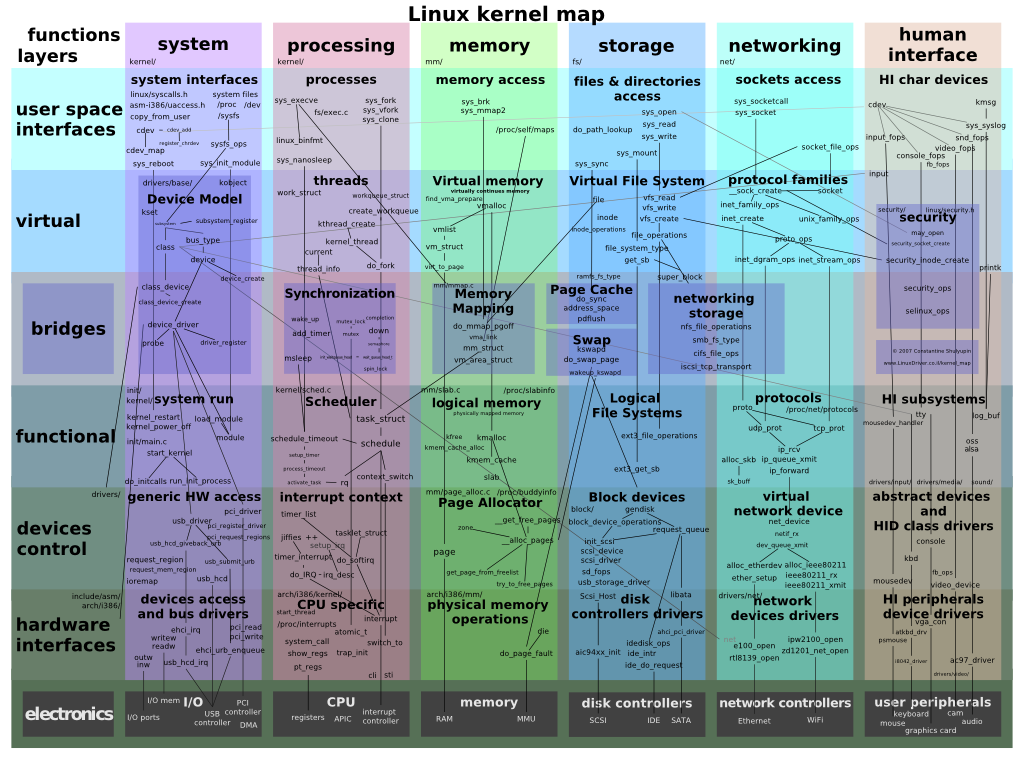
Linux内核是Linux操作系统一部分。对下,它管理系统的所有硬件设备;对上,它通过系统调用,向Library Routine(例如C库)或者其它应用程序提供接口。因此,其核心功能就是:管理硬件设备,供应用程序使用。而现代计算机(无论是PC还是嵌入式系统)的标准组成,就是CPU、Memory(内存和外存)、输入输出设备、网络设备和其它的外围设备。所以为了管理这些设备,Linux内核提出了如下的架构:

上图说明了Linux内核的整体架构。根据内核的核心功能,Linux内核提出了5个子系统,分别负责如下的功能:
1. Process Scheduler,也称作进程管理、进程调度。负责管理CPU资源,以便让各个进程可以以尽量公平的方式访问CPU。
2. Memory Manager,内存管理。负责管理Memory(内存)资源,以便让各个进程可以安全地共享机器的内存资源。另外,内存管理会提供虚拟内存的机制,该机制可以让进程使用多于系统可用Memory的内存,不用的内存会通过文件系统保存在外部非易失存储器中,需要使用的时候,再取回到内存中。
3. VFS(Virtual File System),虚拟文件系统。Linux内核将不同功能的外部设备,例如Disk设备(硬盘、磁盘、NAND Flash、Nor Flash等)、输入输出设备、显示设备等等,抽象为可以通过统一的文件操作接口(open、close、read、write等)来访问。(这就是Linux系统“一切皆是文件”的体现)
4. Network,网络子系统。负责管理系统的网络设备,并实现多种多样的网络标准。
5. IPC(Inter-Process Communication),进程间通信。IPC不管理任何的硬件,它主要负责Linux系统中进程之间的通信。
linux内核中,各模块之间的联系如下:
其中,我们要关注的就是网络子系统。它在Linux内核中主要负责管理各种网络设备,并实现各种网络协议栈,最终实现通过网络连接其它系统的功能。在Linux内核中,网络子系统包括5个子模块(见下图),它们的功能如下:
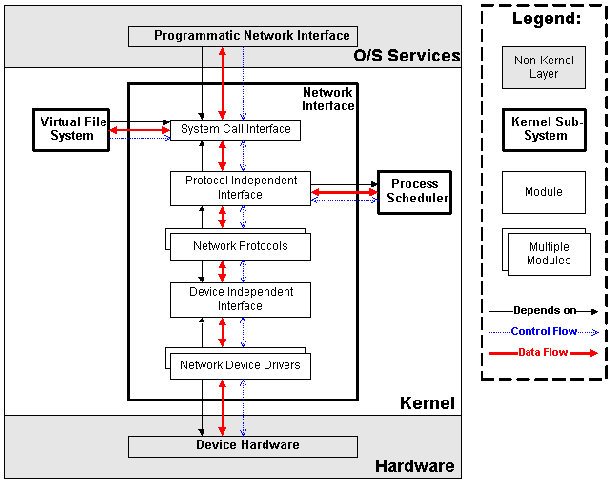
1. Network Device Drivers,网络设备的驱动,和VFS子系统中的设备驱动是一样的。
2. Device Independent Interface,和VFS子系统中的是一样的。
3. Network Protocols,实现各种网络传输协议,例如IP, TCP, UDP等等。
4. Protocol Independent Interface,屏蔽不同的硬件设备和网络协议,以相同的格式提供接口(socket)。
5. System Call interface,系统调用接口,向用户空间提供访问网络设备的统一的接口。
2.网络协议栈简述
参考osi七层模型,各层职责如下:
物理层
在OSI参考模型中,物理层(Physical Layer)是参考模型的最低层,也是OSI模型的第一层。
物理层的主要功能是:利用传输介质为数据链路层提供物理连接,实现比特流的透明传输。
物理层的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异。使其上面的数据链路层不必考虑网络的具体传输介质是什么。“透明传送比特流”表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说,这个电路好像是看不见的。
数据链路层
数据链路层(Data Link Layer)是OSI模型的第二层,负责建立和管理节点间的链路。该层的主要功能是:通过各种控制协议,将有差错的物理信道变为无差错的、能可靠传输数据帧的数据链路。
在计算机网络中由于各种干扰的存在,物理链路是不可靠的。因此,这一层的主要功能是在物理层提供的比特流的基础上,通过差错控制、流量控制方法,使有差错的物理线路变为无差错的数据链路,即提供可靠的通过物理介质传输数据的方法。
该层通常又被分为介质访问控制(MAC)和逻辑链路控制(LLC)两个子层。
MAC子层的主要任务是解决共享型网络中多用户对信道竞争的问题,完成网络介质的访问控制;
LLC子层的主要任务是建立和维护网络连接,执行差错校验、流量控制和链路控制。
数据链路层的具体工作是接收来自物理层的位流形式的数据,并封装成帧,传送到上一层;同样,也将来自上层的数据帧,拆装为位流形式的数据转发到物理层;并且,还负责处理接收端发回的确认帧的信息,以便提供可靠的数据传输。
网络层
网络层(Network Layer)是OSI模型的第三层,它是OSI参考模型中最复杂的一层,也是通信子网的最高一层。它在下两层的基础上向资源子网提供服务。其主要任务是:通过路由选择算法,为报文或分组通过通信子网选择最适当的路径。该层控制数据链路层与传输层之间的信息转发,建立、维持和终止网络的连接。具体地说,数据链路层的数据在这一层被转换为数据包,然后通过路径选择、分段组合、顺序、进/出路由等控制,将信息从一个网络设备传送到另一个网络设备。
一般地,数据链路层是解决同一网络内节点之间的通信,而网络层主要解决不同子网间的通信。例如在广域网之间通信时,必然会遇到路由(即两节点间可能有多条路径)选择问题。
在实现网络层功能时,需要解决的主要问题如下:
寻址:数据链路层中使用的物理地址(如MAC地址)仅解决网络内部的寻址问题。在不同子网之间通信时,为了识别和找到网络中的设备,每一子网中的设备都会被分配一个唯一的地址。由于各子网使用的物理技术可能不同,因此这个地址应当是逻辑地址(如IP地址)。
交换:规定不同的信息交换方式。常见的交换技术有:线路交换技术和存储转发技术,后者又包括报文交换技术和分组交换技术。
路由算法:当源节点和目的节点之间存在多条路径时,本层可以根据路由算法,通过网络为数据分组选择最佳路径,并将信息从最合适的路径由发送端传送到接收端。
连接服务:与数据链路层流量控制不同的是,前者控制的是网络相邻节点间的流量,后者控制的是从源节点到目的节点间的流量。其目的在于防止阻塞,并进行差错检测。
传输层
OSI下3层的主要任务是数据通信,上3层的任务是数据处理。而传输层(Transport Layer)是OSI模型的第4层。因此该层是通信子网和资源子网的接口和桥梁,起到承上启下的作用。
该层的主要任务是:向用户提供可靠的端到端的差错和流量控制,保证报文的正确传输。传输层的作用是向高层屏蔽下层数据通信的细节,即向用户透明地传送报文。该层常见的协议:TCP/IP中的TCP协议、Novell网络中的SPX协议和微软的NetBIOS/NetBEUI协议。
传输层提供会话层和网络层之间的传输服务,这种服务从会话层获得数据,并在必要时,对数据进行分割。然后,传输层将数据传递到网络层,并确保数据能正确无误地传送到网络层。因此,传输层负责提供两节点之间数据的可靠传送,当两节点的联系确定之后,传输层则负责监督工作。综上,传输层的主要功能如下:
传输连接管理:提供建立、维护和拆除传输连接的功能。传输层在网络层的基础上为高层提供“面向连接”和“面向无接连”的两种服务。
处理传输差错:提供可靠的“面向连接”和不太可靠的“面向无连接”的数据传输服务、差错控制和流量控制。在提供“面向连接”服务时,通过这一层传输的数据将由目标设备确认,如果在指定的时间内未收到确认信息,数据将被重发。
监控服务质量。
会话层
会话层(Session Layer)是OSI模型的第5层,是用户应用程序和网络之间的接口,主要任务是:向两个实体的表示层提供建立和使用连接的方法。将不同实体之间的表示层的连接称为会话。因此会话层的任务就是组织和协调两个会话进程之间的通信,并对数据交换进行管理。
用户可以按照半双工、单工和全双工的方式建立会话。当建立会话时,用户必须提供他们想要连接的远程地址。而这些地址与MAC(介质访问控制子层)地址或网络层的逻辑地址不同,它们是为用户专门设计的,更便于用户记忆。域名(DN)就是一种网络上使用的远程地址例如:www.3721.com就是一个域名。会话层的具体功能如下:
会话管理:允许用户在两个实体设备之间建立、维持和终止会话,并支持它们之间的数据交换。例如提供单方向会话或双向同时会话,并管理会话中的发送顺序,以及会话所占用时间的长短。
会话流量控制:提供会话流量控制和交叉会话功能。
寻址:使用远程地址建立会话连接。l
出错控制:从逻辑上讲会话层主要负责数据交换的建立、保持和终止,但实际的工作却是接收来自传输层的数据,并负责纠正错误。会话控制和远程过程调用均属于这一层的功能。但应注意,此层检查的错误不是通信介质的错误,而是磁盘空间、打印机缺纸等类型的高级错误。
表示层
表示层(Presentation Layer)是OSI模型的第六层,它对来自应用层的命令和数据进行解释,对各种语法赋予相应的含义,并按照一定的格式传送给会话层。其主要功能是“处理用户信息的表示问题,如编码、数据格式转换和加密解密”等。表示层的具体功能如下:
数据格式处理:协商和建立数据交换的格式,解决各应用程序之间在数据格式表示上的差异。
数据的编码:处理字符集和数字的转换。例如由于用户程序中的数据类型(整型或实型、有符号或无符号等)、用户标识等都可以有不同的表示方式,因此,在设备之间需要具有在不同字符集或格式之间转换的功能。
压缩和解压缩:为了减少数据的传输量,这一层还负责数据的压缩与恢复。
数据的加密和解密:可以提高网络的安全性。
应用层
应用层(Application Layer)是OSI参考模型的最高层,它是计算机用户,以及各种应用程序和网络之间的接口,其功能是直接向用户提供服务,完成用户希望在网络上完成的各种工作。它在其他6层工作的基础上,负责完成网络中应用程序与网络操作系统之间的联系,建立与结束使用者之间的联系,并完成网络用户提出的各种网络服务及应用所需的监督、管理和服务等各种协议。此外,该层还负责协调各个应用程序间的工作。
应用层为用户提供的服务和协议有:文件服务、目录服务、文件传输服务(FTP)、远程登录服务(Telnet)、电子邮件服务(E-mail)、打印服务、安全服务、网络管理服务、数据库服务等。上述的各种网络服务由该层的不同应用协议和程序完成,不同的网络操作系统之间在功能、界面、实现技术、对硬件的支持、安全可靠性以及具有的各种应用程序接口等各个方面的差异是很大的。应用层的主要功能如下:
用户接口:应用层是用户与网络,以及应用程序与网络间的直接接口,使得用户能够与网络进行交互式联系。
实现各种服务:该层具有的各种应用程序可以完成和实现用户请求的各种服务。
3.Linux中的网络模型
Linux网络子系统提供了对各种网络标准的存取和各种硬件的支持,其可以分为插口层,协议层和接口层,整体结构如图所示:
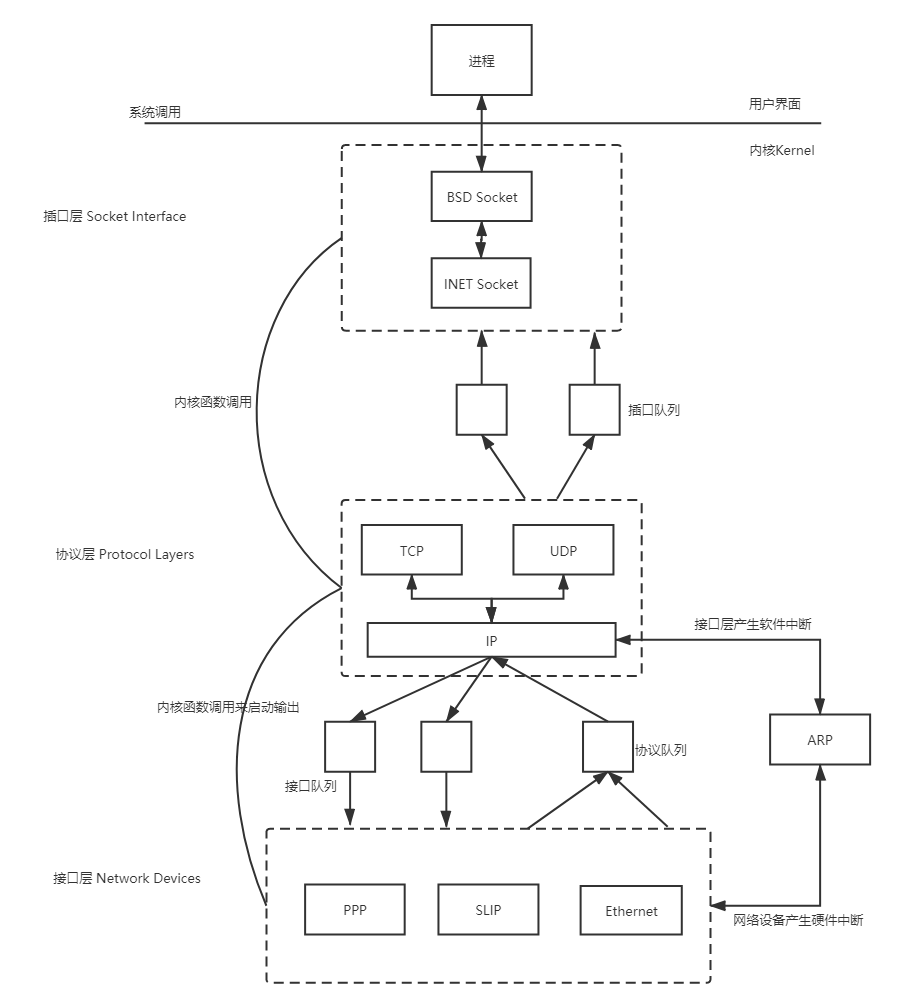
BSD Socket层:这一部分处理BSD socket相关操作,每个socket在内核中以struct socket结构体现,这一部分的文件主要有:/net/socket.c、/net/protocol.c等。
INET socket层:BSD socket是个可以用于各种网络协议的接口,而当用于tcp/ip,即建立了AF_INET形式的socket时,还需要保留些额外的参数,于是就有了struct sock结构。文件主要有:/net/ipv4/protocol.c、/net/ipv4/af_inet.c、/net/core/sock.c等。
TCP/UDP层:处理传输层的操作,传输层用struct inet_protocol和struct proto两个结构表示,文件主要有:/net/ipv4/udp.c、/net/ipv4/datagram.c、/net/ipv4/tcp.c等。
IP层:处理网络层的操作,网络层用struct packet_type结构表示,文件主要有:/net/ipv4/ip_forward.c、ip_fragment.c、ip_input.c等。
数据链路层和驱动程序:每个网络设备以struct net_device表示,通用的处理在dev.c中,驱动程序都在/driver/net目录下。
各层次中涉及的主要函数及数据结构如图所示:
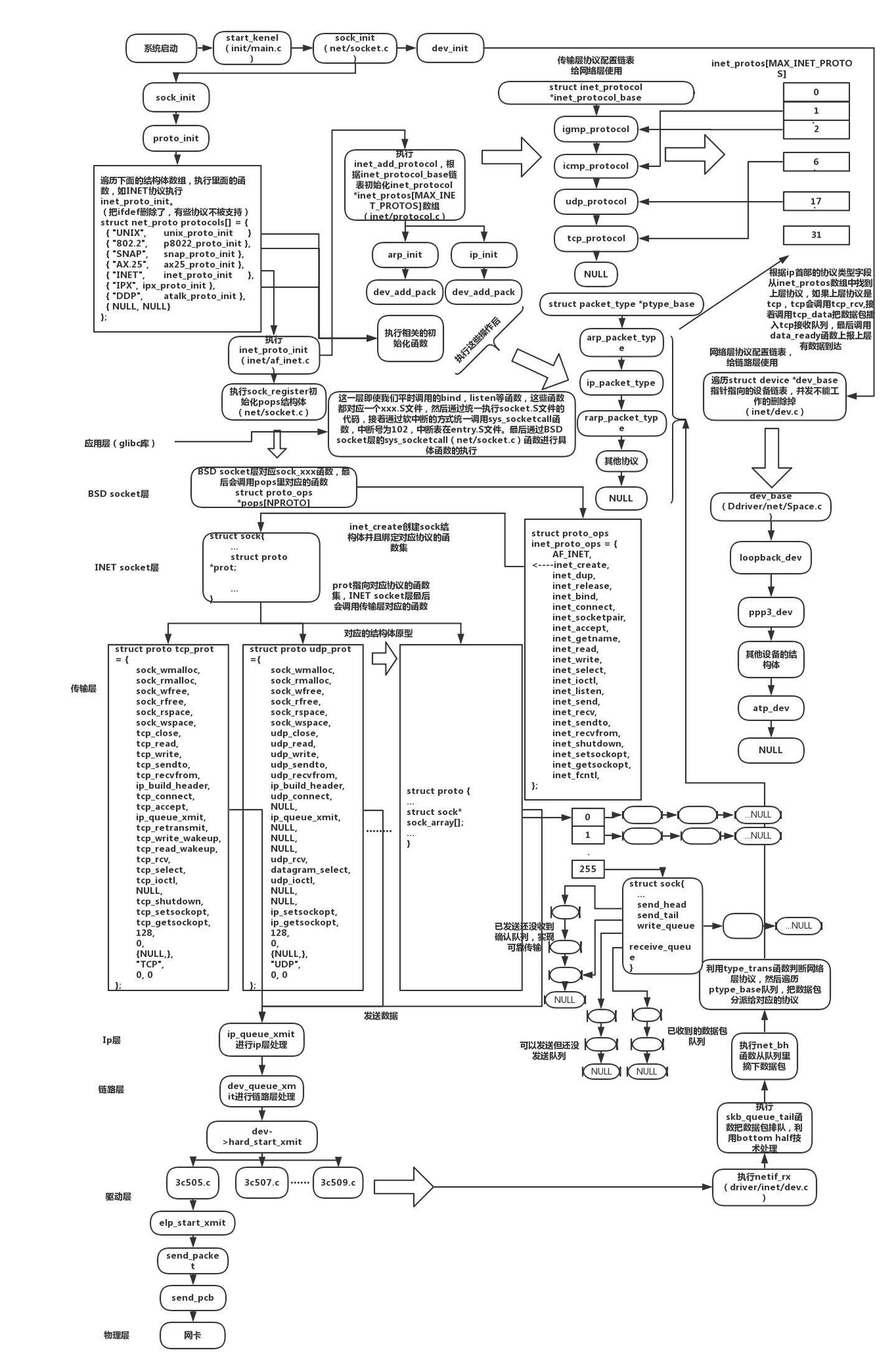
4.socket简介
socket是独立于具体协议的网络编程接口,在OSI模型中,主要位于会话层和传输层之间。socket起源于Unix,而Unix/Linux基本哲学之一就是“一切皆文件”,都可以用“打开open –> 读写write/read –> 关闭close”模式来操作。Socket就是该模式的一个实现,是一种特殊的文件,一些socket函数就是对其进行的操作(读/写IO、打开、关闭)。接下来对这些函数进行简要介绍:
4.1socket()函数
1 int socket(int domain, int type, int protocol);
socket函数对应于普通文件的打开操作。普通文件的打开操作返回一个文件描述字,而socket()用于创建一个socket描述符(socket descriptor),它唯一标识一个socket。这个socket描述字跟文件描述字一样,后续的操作都有用到它,把它作为参数,通过它来进行一些读写操作。
正如可以给fopen的传入不同参数值,以打开不同的文件。创建socket的时候,也可以指定不同的参数创建不同的socket描述符,socket函数的三个参数分别为:
- domain:即协议域,又称为协议族(family)。常用的协议族有,AF_INET、AF_INET6、AF_LOCAL(或称AF_UNIX,Unix域socket)、AF_ROUTE等等。协议族决定了socket的地址类型,在通信中必须采用对应的地址,如AF_INET决定了要用ipv4地址(32位的)与端口号(16位的)的组合、AF_UNIX决定了要用一个绝对路径名作为地址。
- type:指定socket类型。常用的socket类型有,SOCK_STREAM、SOCK_DGRAM、SOCK_RAW、SOCK_PACKET、SOCK_SEQPACKET等等。
- protocol:故名思意,就是指定协议。常用的协议有,IPPROTO_TCP、IPPTOTO_UDP、IPPROTO_SCTP、IPPROTO_TIPC等,它们分别对应TCP传输协议、UDP传输协议、STCP传输协议、TIPC传输协议。
注意:并不是上面的type和protocol可以随意组合的,如SOCK_STREAM不可以跟IPPROTO_UDP组合。当protocol为0时,会自动选择type类型对应的默认协议。
当我们调用socket创建一个socket时,返回的socket描述字它存在于协议族(address family,AF_XXX)空间中,但没有一个具体的地址。如果想要给它赋值一个地址,就必须调用bind()函数,否则就当调用connect()、listen()时系统会自动随机分配一个端口。
4.2bind()函数
正如上面所说bind()函数把一个地址族中的特定地址赋给socket。例如对应AF_INET、AF_INET6就是把一个ipv4或ipv6地址和端口号组合赋给socket。
1 int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
函数的三个参数分别为:
- sockfd:即socket描述字,它是通过socket()函数创建了,唯一标识一个socket。bind()函数就是将给这个描述字绑定一个名字。
- addr:一个const struct sockaddr *指针,指向要绑定给sockfd的协议地址。这个地址结构根据地址创建socket时的地址协议族的不同而不同,如ipv4对应的是:
1 struct sockaddr_in { 2 sa_family_t sin_family; /* address family: AF_INET */ 3 in_port_t sin_port; /* port in network byte order */ 4 struct in_addr sin_addr; /* internet address */ 5 }; 6 7 /* Internet address. */ 8 struct in_addr { 9 uint32_t s_addr; /* address in network byte order */ 10 };
ipv6对应的是:
1 struct sockaddr_in6 { 2 sa_family_t sin6_family; /* AF_INET6 */ 3 in_port_t sin6_port; /* port number */ 4 uint32_t sin6_flowinfo; /* IPv6 flow information */ 5 struct in6_addr sin6_addr; /* IPv6 address */ 6 uint32_t sin6_scope_id; /* Scope ID (new in 2.4) */ 7 }; 8 9 struct in6_addr { 10 unsigned char s6_addr[16]; /* IPv6 address */ 11 };
Unix域对应的是:
1 #define UNIX_PATH_MAX 108 2 3 struct sockaddr_un { 4 sa_family_t sun_family; /* AF_UNIX */ 5 char sun_path[UNIX_PATH_MAX]; /* pathname */ 6 };
- addrlen:对应的是地址的长度。
通常服务器在启动的时候都会绑定一个众所周知的地址(如ip地址+端口号),用于提供服务,客户就可以通过它来接连服务器;而客户端就不用指定,有系统自动分配一个端口号和自身的ip地址组合。这就是为什么通常服务器端在listen之前会调用bind(),而客户端就不会调用,而是在connect()时由系统随机生成一个。
4.3 listen()、connect()函数
如果作为一个服务器,在调用socket()、bind()之后就会调用listen()来监听这个socket,如果客户端这时调用connect()发出连接请求,服务器端就会接收到这个请求。
1 int listen(int sockfd, int backlog); 2 int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
listen函数的第一个参数即为要监听的socket描述字,第二个参数为相应socket可以排队的最大连接个数。socket()函数创建的socket默认是一个主动类型的,listen函数将socket变为被动类型的,等待客户的连接请求。
connect函数的第一个参数即为客户端的socket描述字,第二参数为服务器的socket地址,第三个参数为socket地址的长度。客户端通过调用connect函数来建立与TCP服务器的连接。
4.4 accept()函数
TCP服务器端依次调用socket()、bind()、listen()之后,就会监听指定的socket地址了。TCP客户端依次调用socket()、connect()之后就想TCP服务器发送了一个连接请求。TCP服务器监听到这个请求之后,就会调用accept()函数取接收请求,这样连接就建立好了。之后就可以开始网络I/O操作了,即类同于普通文件的读写I/O操作。
1 int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
accept函数的第一个参数为服务器的socket描述字,第二个参数为指向struct sockaddr *的指针,用于返回客户端的协议地址,第三个参数为协议地址的长度。如果accpet成功,那么其返回值是由内核自动生成的一个全新的描述字,代表与返回客户的TCP连接。
注意:accept的第一个参数为服务器的socket描述字,是服务器开始调用socket()函数生成的,称为监听socket描述字;而accept函数返回的是已连接的socket描述字。一个服务器通常通常仅仅只创建一个监听socket描述字,它在该服务器的生命周期内一直存在。内核为每个由服务器进程接受的客户连接创建了一个已连接socket描述字,当服务器完成了对某个客户的服务,相应的已连接socket描述字就被关闭。
4.5recv()/send()等函数
相关操作有一下几组:
- read()/write()
- recv()/send()
- readv()/writev()
- recvmsg()/sendmsg()
- recvfrom()/sendto()
1 #include <unistd.h> 2 3 ssize_t read(int fd, void *buf, size_t count); 4 ssize_t write(int fd, const void *buf, size_t count); 5 6 #include <sys/types.h> 7 #include <sys/socket.h> 8 9 ssize_t send(int sockfd, const void *buf, size_t len, int flags); 10 ssize_t recv(int sockfd, void *buf, size_t len, int flags); 11 12 ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, 13 const struct sockaddr *dest_addr, socklen_t addrlen); 14 ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, 15 struct sockaddr *src_addr, socklen_t *addrlen); 16 17 ssize_t sendmsg(int sockfd, const struct msghdr *msg, int flags); 18 ssize_t recvmsg(int sockfd, struct msghdr *msg, int flags);
read函数是负责从fd中读取内容.当读成功时,read返回实际所读的字节数,如果返回的值是0表示已经读到文件的结束了,小于0表示出现了错误。如果错误为EINTR说明读是由中断引起的,如果是ECONNREST表示网络连接出了问题。
write函数将buf中的nbytes字节内容写入文件描述符fd.成功时返回写的字节数。失败时返回-1,并设置errno变量。 在网络程序中,当我们向套接字文件描述符写时有俩种可能。1)write的返回值大于0,表示写了部分或者是全部的数据。2)返回的值小于0,此时出现了错误。我们要根据错误类型来处理。如果错误为EINTR表示在写的时候出现了中断错误。如果为EPIPE表示网络连接出现了问题(对方已经关闭了连接)。
4.6 close()函数
在服务器与客户端建立连接之后,会进行一些读写操作,完成了读写操作就要关闭相应的socket描述字,好比操作完打开的文件要调用fclose关闭打开的文件。
1 int close(int fd);
close一个TCP socket的缺省行为时把该socket标记为以关闭,然后立即返回到调用进程。该描述字不能再由调用进程使用,也就是说不能再作为read或write的第一个参数。
注意:close操作只是使相应socket描述字的引用计数-1,只有当引用计数为0的时候,才会触发TCP客户端向服务器发送终止连接请求。
4.7 socket中TCP的三次握手建立连接
我们知道tcp建立连接要进行“三次握手”,即交换三个分组。大致流程如下:
- 客户端向服务器发送一个SYN J
- 服务器向客户端响应一个SYN K,并对SYN J进行确认ACK J+1
- 客户端再想服务器发一个确认ACK K+1
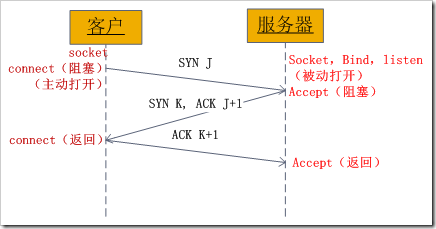
从图中可以看出,当客户端调用connect时,触发了连接请求,向服务器发送了SYN J包,这时connect进入阻塞状态;服务器监听到连接请求,即收到SYN J包,调用accept函数接收请求向客户端发送SYN K ,ACK J+1,这时accept进入阻塞状态;客户端收到服务器的SYN K ,ACK J+1之后,这时connect返回,并对SYN K进行确认;服务器收到ACK K+1时,accept返回,至此三次握手完毕,连接建立。即客户端的connect在三次握手的第二次返回,而服务器端的accept在三次握手的第三次返回。
4.8 socket中TCP的四次挥手释放连接
上面介绍了socket中TCP的三次握手建立过程,及其涉及的socket函数。现在我们介绍socket中的四次握手释放连接的过程,请看下图:
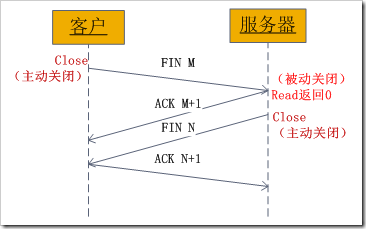
图示过程如下:
-
某个应用进程首先调用 close主动关闭连接,这时TCP发送一个FIN M;
-
另一端接收到FIN M之后,执行被动关闭,对这个FIN进行确认。它的接收也作为文件结束符传递给应用进程,因为FIN的接收意味着应用进程在相应的连接上再也接收不到额外数据;
-
一段时间之后,接收到文件结束符的应用进程调用 close关闭它的socket。这导致它的TCP也发送一个FIN N;
-
接收到这个FIN的源发送端TCP对它进行确认。
这样每个方向上都有一个FIN和ACK。
5.TCP/IP协议栈在Linux内核中的运行分析
5.1 测试代码
本文基于以下代码进行分析:
客户端:
1 #include <stdio.h> /* perror */ 2 #include <stdlib.h> /* exit */ 3 #include <sys/types.h> /* WNOHANG */ 4 #include <sys/wait.h> /* waitpid */ 5 #include <string.h> /* memset */ 6 #include <sys/time.h> 7 #include <sys/types.h> 8 #include <unistd.h> 9 #include <fcntl.h> 10 #include <sys/socket.h> 11 #include <errno.h> 12 #include <arpa/inet.h> 13 #include <netdb.h> /* gethostbyname */ 14 15 #define true 1 16 #define false 0 17 18 #define PORT 3490 /* Server的端口 */ 19 #define MAXDATASIZE 100 /* 一次可以读的最大字节数 */ 20 21 int main(int argc, char *argv[]){ 22 int serverfd; //服务器套接字 23 struct hostent *he; //主机信息 24 struct sockaddr_in server_addr; //服务器地址信息 25 26 if (argc != 2){ 27 fprintf(stderr, "usage: client hostname\n"); 28 exit(1); 29 } 30 //获取本机信息 31 if ((he = Gethostbyname(argv[1])) == NULL){ 32 /* 注意:获取DNS信息时,显示出错需要用herror而不是perror */ 33 /* herror 在新的版本中会出现警告,已经建议不要使用了 */ 34 perror("gethostbyname"); 35 exit(1); 36 } 37 38 if ((serverfd = Socket(PF_INET, SOCK_STREAM, 0)) == -1) //创建套接字 39 { 40 perror("socket"); 41 exit(1); 42 } 43 44 server_addr.sin_family = AF_INET; 45 server_addr.sin_port = htons(PORT); /* short, NBO */ 46 server_addr.sin_addr = *((struct in_addr *)he->h_addr_list[0]); 47 memset(&(server_addr.sin_zero), 0, 8); /* 其余部分设成0 */ 48 49 if (Connect(serverfd, (struct sockaddr *)&server_addr, 50 sizeof(struct sockaddr)) == -1) 51 { 52 perror("connect"); 53 exit(1); 54 } 55 56 int bufSize; 57 char inputBuf[MAXDATASIZE]; 58 if ((bufSize = Recv(serverfd, inputBuf, MAXDATASIZE, 0)) == -1) 59 { 60 perror("recv"); 61 exit(1); 62 } 63 64 if (Send(serverfd, "hi\n", 3, 0) == -1) 65 perror("send"); 66 67 68 inputBuf[bufSize] = '\0'; 69 printf("Received: %s", inputBuf); 70 close(serverfd); 71 72 return true; 73 }
服务器:
1 #include <stdio.h> /* perror */ 2 #include <stdlib.h> /* exit */ 3 #include <sys/types.h> /* WNOHANG */ 4 #include <sys/wait.h> /* waitpid */ 5 #include <string.h> /* memset */ 6 #include <sys/time.h> 7 #include <sys/types.h> 8 #include <unistd.h> 9 #include <fcntl.h> 10 #include <sys/socket.h> 11 #include <errno.h> 12 #include <arpa/inet.h> 13 #include <netdb.h> /* gethostbyname */ 14 15 16 /* byte order trans */ 17 #define Htons(a) htons(a) 18 #define Inet_ntoa(a) inet_ntoa(a) 19 20 /* Name */ 21 #define Gethostbyname(a) gethostbyname(a) 22 23 #define true 1 24 #define false 0 25 26 #define MYPORT 3490 /* 监听的端口 */ 27 #define BACKLOG 10 /* listen的请求接收队列长度 */ 28 #define MAXDATASIZE 100 /*接收缓存最大值*/ 29 30 int main(int argc, char *argv[]){ 31 int myfd; //自己的socket描述符 32 int clientfd; //客户端的socket描述符 33 struct sockaddr_in local_add; //本地地址 34 struct sockaddr_in client_add; //客户端地址 35 36 if( (myfd = Socket(PF_INET, SOCK_STREAM, 0)) == -1){ //绑定本机端口 37 perror("bind"); 38 exit(1); 39 } 40 41 local_add.sin_family = AF_INET; 42 local_add.sin_port = htons(MYPORT); /* 网络字节顺序 */ 43 local_add.sin_addr.s_addr = INADDR_ANY; /* 自动填本机IP */ 44 memset(&(local_add.sin_zero), 0, 8); /* 其余部分置0 */ 45 46 if (Bind(myfd, (struct sockaddr *)&local_add, sizeof(local_add)) == -1) //绑定本机端口 47 { 48 perror("bind"); 49 exit(1); 50 } 51 52 if( Listen(myfd, BACKLOG) == -1){ //监听端口 53 perror("listen"); 54 exit(1); 55 } 56 57 while(true){ 58 int sin_size = sizeof(struct sockaddr_in); 59 //接受连接请求 60 clientfd = Accept(myfd, (struct sockaddr*)&client_add, &sin_size); 61 if(clientfd == -1){ 62 perror("accpet"); 63 continue; 64 } 65 //连接成功,输出客户端的ip地址 66 printf("Got connection from %s\n", inet_ntoa(client_add.sin_addr)); 67 if(fork() == 0){ //子进程 68 if(Send(clientfd, "hello\n", 6, 0) == -1) //向客户端发送hello 69 perror("send"); 70 int bufSize; 71 char inputBuf[MAXDATASIZE]; 72 //接受客户端发送来的信息 73 if((bufSize = Recv(clientfd, inputBuf, MAXDATASIZE, 0)) == -1){ 74 perror("recv"); 75 exit(1); 76 } 77 inputBuf[bufSize] = '\0'; 78 printf("Received: %s", inputBuf); 79 close(clientfd); //关闭客户端套接字 80 exit(0); //退出子进程 81 } 82 83 close(clientfd); //关闭客户端套接字 84 85 //清除所有子进程 86 while(waitpid(-1, NULL, WNOHANG) > 0){;} 87 } 88 close(myfd); 89 return true; 90 }
5.2 网络协议栈初始化流程
这需要从内核启动流程说起。当内核完成自解压过程后进入内核启动流程,这一过程先在 arch/mips/kernel/head.S 程序中,这个程序负责数据区(BBS)、中断描述表(IDT)、段描述表(GDT)、页表和寄存器的初始化,程序中定义了内核的入口函数 kernel_entry()、kernel_entry() 函数是体系结构相关的汇编代码,它首先初始化内核堆栈段为创建系统中的第一过程进行准备,接着用一段循环将内核映像的未初始化的数据段清零,最后跳到 start_kernel() 函数中初始化硬件相关的代码,完成 Linux Kernel 环境的建立。
start_kenrel() 定义在 init/main.c 中,真正的内核初始化过程就是从这里才开始。函数 start_kerenl() 将会调用一系列的初始化函数,如:平台初始化,内存初始化,陷阱初始化,中断初始化,进程调度初始化,缓冲区初始化,完成内核本身的各方面设置,目的是最终建立起基本完整的 Linux 内核环境。
start_kernel() 中主要函数及调用关系如下:
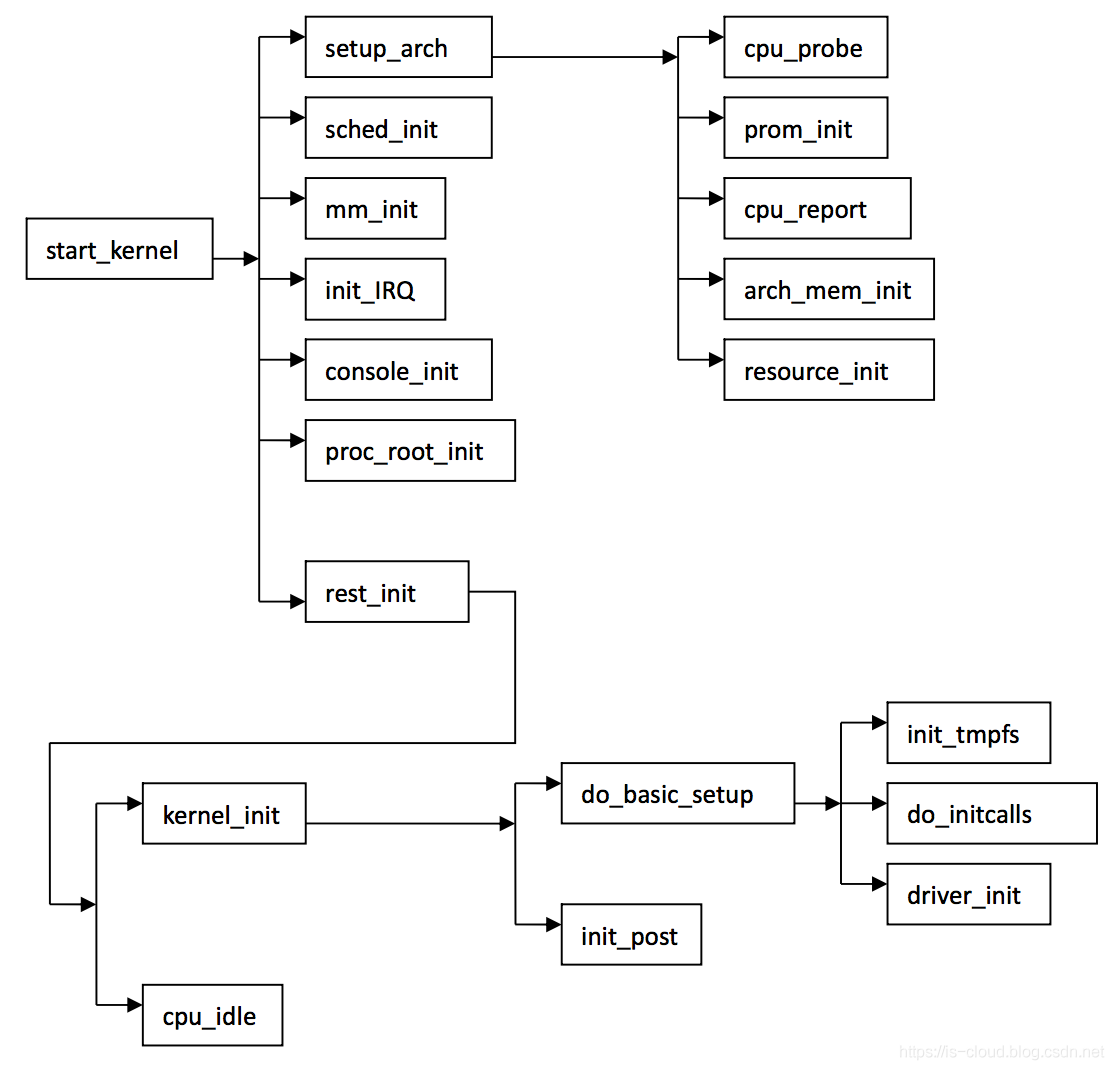
start_kernel() 的过程中会执行 socket_init() 来完成协议栈的初始化,实现如下:
1 void sock_init(void)//网络栈初始化 2 { 3 int i; 4 5 printk("Swansea University Computer Society NET3.019\n"); 6 7 /* 8 * Initialize all address (protocol) families. 9 */ 10 11 for (i = 0; i < NPROTO; ++i) pops[i] = NULL; 12 13 /* 14 * Initialize the protocols module. 15 */ 16 17 proto_init(); 18 19 #ifdef CONFIG_NET 20 /* 21 * Initialize the DEV module. 22 */ 23 24 dev_init(); 25 26 /* 27 * And the bottom half handler 28 */ 29 30 bh_base[NET_BH].routine= net_bh; 31 enable_bh(NET_BH); 32 #endif 33 }
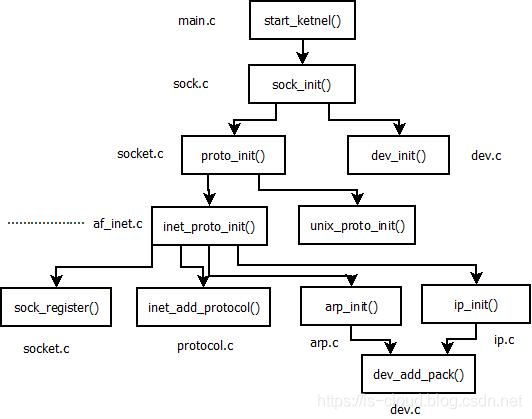
sock_init() 包含了内核协议栈的初始化工作:
- sock_init:Initialize sk_buff SLAB cache,注册 SOCKET 文件系统。
- net_inuse_init:为每个 CPU 分配缓存。
- proto_init:在 /proc/net 域下建立 protocols 文件,注册相关文件操作函数。
- net_dev_init:建立 netdevice 在 /proc/sys 相关的数据结构,并且开启网卡收发中断;为每个 CPU 初始化一个数据包接收队列(softnet_data),包接收的回调;注册本地回环操作,注册默认网络设备操作。
- inet_init:注册 INET 协议族的 SOCKET 创建方法,注册 TCP、UDP、ICMP、IGMP 接口基本的收包方法。为 IPv4 协议族创建 proc 文件。此函数为协议栈主要的注册函数:
rc = proto_register(&udp_prot, 1);:注册 INET 层 UDP 协议,为其分配快速缓存。(void)sock_register(&inet_family_ops);:向static const struct net_proto_family *net_families[NPROTO]结构体注册 INET 协议族的操作集合(主要是 INET socket 的创建操作)。inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0;:向externconst struct net_protocol *inet_protos[MAX_INET_PROTOS]结构体注册传输层 UDP 的操作集合。static struct list_head inetsw[SOCK_MAX]; for (r = &inetsw[0]; r < &inetsw[SOCK_MAX];++r) INIT_LIST_HEAD(r);:初始化 SOCKET 类型数组,其中保存了这是个链表数组,每个元素是一个链表,连接使用同种 SOCKET 类型的协议和操作集合。for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q):inet_register_protosw(q);:向 sock 注册协议的的调用操作集合。
arp_init();:启动 ARP 协议支持。ip_init();:启动 IP 协议支持。udp_init();:启动 UDP 协议支持。dev_add_pack(&ip_packet_type);:向ptype_base[PTYPE_HASH_SIZE];注册 IP 协议的操作集合。socket.c提供的系统调用接口。
5.3 应用层流程
5.3.1 发送端
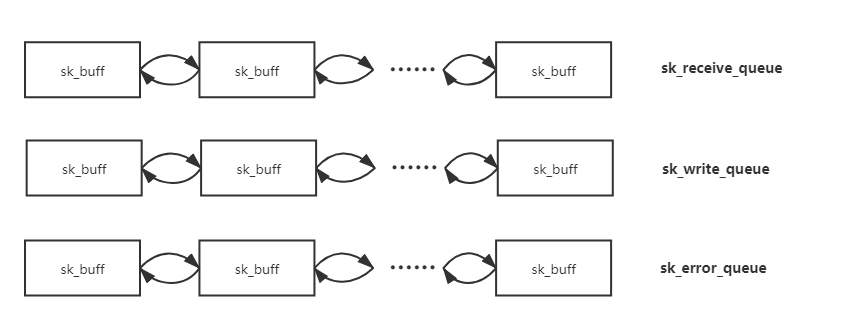
1.网络应用调用Socket API socket (int family, int type, int protocol) 创建一个 socket,该调用最终会调用 Linux system call socket() ,并最终调用 Linux Kernel 的 sock_create() 方法。该方法返回被创建好了的那个 socket 的 file descriptor。对于每一个 userspace 网络应用创建的 socket,在内核中都有一个对应的 struct socket和 struct sock。其中,struct sock 有三个队列(queue),分别是 rx , tx 和 err,在 sock 结构被初始化的时候,这些缓冲队列也被初始化完成;在收据收发过程中,每个 queue 中保存要发送或者接受的每个 packet 对应的 Linux 网络栈 sk_buffer 数据结构的实例 skb。
2.对于TCP socket 来说,应用调用 connect()API ,使得客户端和服务器端通过该 socket 建立一个虚拟连接。在此过程中,TCP 协议栈通过三次握手会建立 TCP 连接。默认地,该 API 会等到 TCP 握手完成连接建立后才返回。在建立连接的过程中的一个重要步骤是,确定双方使用的 Maxium Segemet Size (MSS)。因为 UDP 是面向无连接的协议,因此它是不需要该步骤的。
3.应用调用 Linux Socket 的 send 或者 write API 来发出一个 message 给接收端。
4.sock_sendmsg 被调用,它使用 socket descriptor 获取 sock struct,创建 message header 和 socket control message。
5._sock_sendmsg 被调用,根据 socket 的协议类型,调用相应协议的发送函数。
6.对于TCP ,调用 tcp_sendmsg 函数。
7.对于UDP 来说,userspace 应用可以调用 send()/sendto()/sendmsg() 三个 system call 中的任意一个来发送 UDP message,它们最终都会调用内核中的 udp_sendmsg() 函数。
5.3.2 接收端
1.每当用户应用调用 read 或者 recvfrom 时,该调用会被映射为/net/socket.c 中的 sys_recv 系统调用,并被转化为 sys_recvfrom 调用,然后调用 sock_recgmsg 函数。
2.对于 INET 类型的 socket,/net/ipv4/af inet.c 中的 inet_recvmsg 方法会被调用,它会调用相关协议的数据接收方法。
3.对TCP 来说,调用 tcp_recvmsg。该函数从 socket buffer 中拷贝数据到 user buffer。
4.对UDP 来说,从 user space 中可以调用三个 system call recv()/recvfrom()/recvmsg() 中的任意一个来接收 UDP package,这些系统调用最终都会调用内核中的 udp_recvmsg 方法。
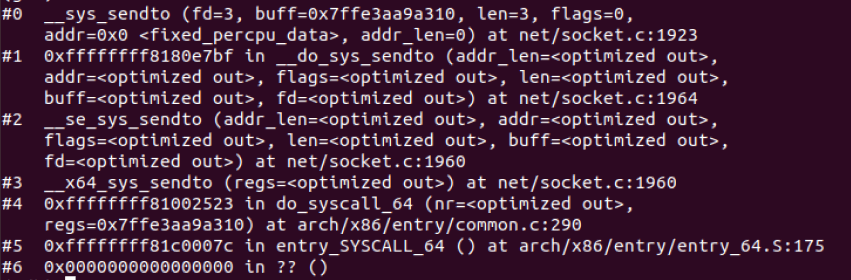
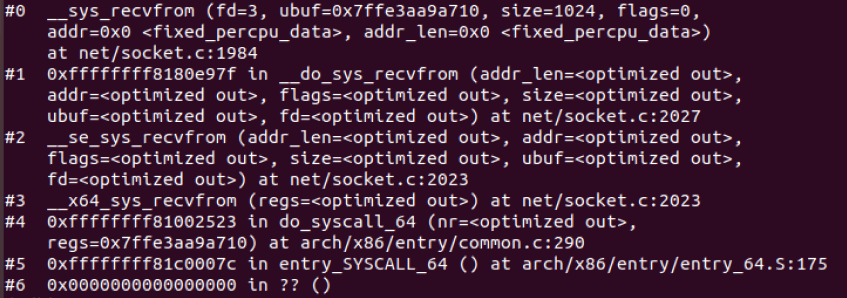
5.3.3 调试结果
5.4 传输层
传输层的最终目的是向它的用户提供高效的、可靠的和成本有效的数据传输服务,主要功能包括:
(1)构造TCP segment
(2)计算checksum
(3)发送回复包(ACK)
(4)滑动窗口协议
TCP协议栈的大致流程如图所示:
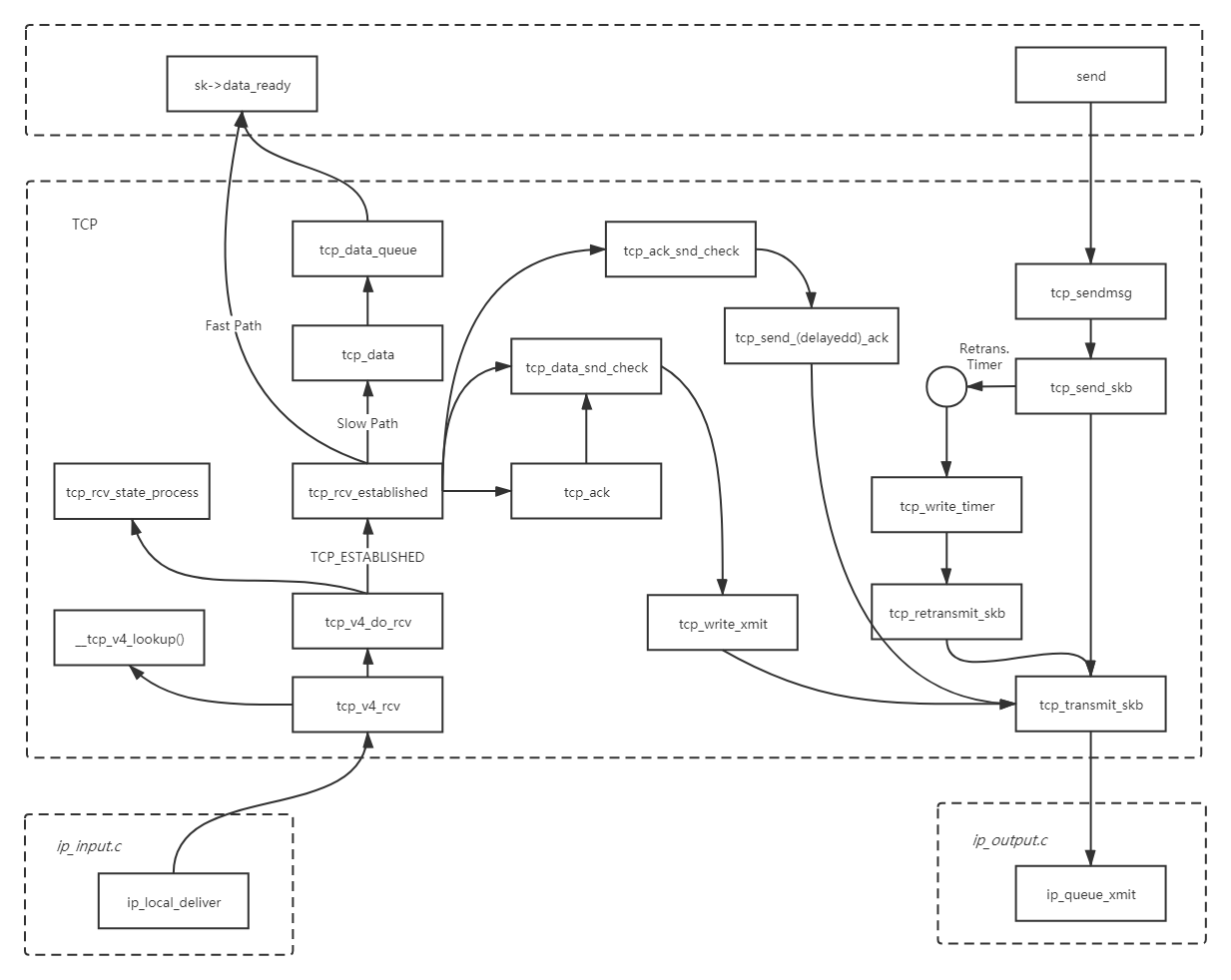
5.4.1TCP栈发送数据过程简介
1.tcp_sendmsg 函数会首先检查已经建立的 TCP connection 的状态,然后获取该连接的 MSS,开始 segement 发送流程。
2.构造TCP 段的 playload:它在内核空间中创建该 packet 的 sk_buffer 数据结构的实例 skb,从 userspace buffer 中拷贝 packet 的数据到 skb 的 buffer。
3.构造TCP header。
4.计算TCP 校验和(checksum)和 顺序号 (sequence number):TCP校验和是一个端到端的校验和,由发送端计算,然后由接收端验证。其目的是为了发现TCP首部和数据在发送端到接收端之间发生的任何改动。如果接收方检测到校验和有差错,则TCP段会被直接丢弃。TCP校验和覆盖 TCP 首部和 TCP 数据;TCP的校验和是必需的。
5.发到 IP 层处理:调用 IP handler 句柄 ip_queue_xmit,将 skb 传入 IP 处理流程。
5.4.2TCP栈接收数据过程简介
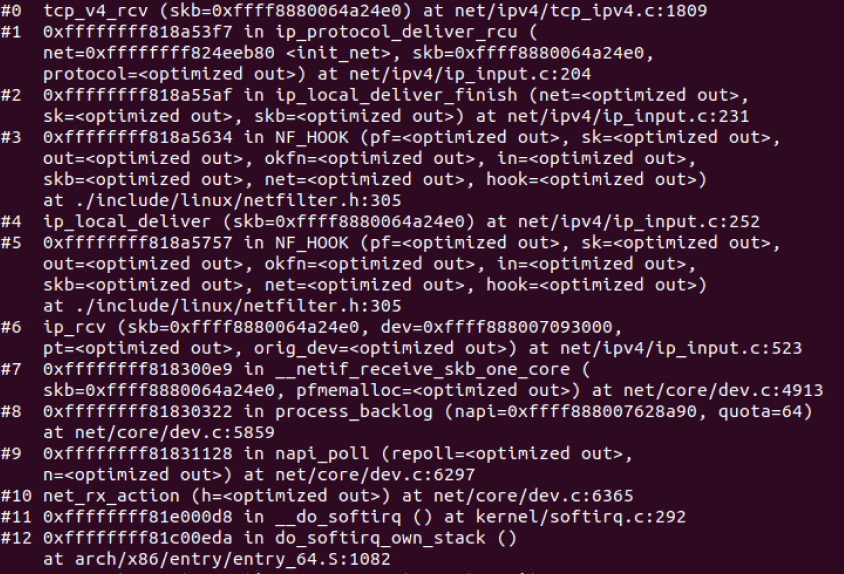
1.传输层TCP 处理入口在 tcp_v4_rcv 函数(位于 linux/net/ipv4/tcp ipv4.c 文件中),它会做 TCP header 检查等处理。
2.调用 _tcp_v4_lookup,查找该package的open socket。如果找不到,该package会被丢弃。接下来检查 socket 和 connection 的状态。
3.如果socket 和 connection 一切正常,调用 tcp_prequeue 使 package 从内核进入 user space,放进 socket 的 receive queue。然后 socket 会被唤醒,调用 system call,并最终调用 tcp_recvmsg 函数去从 socket recieve queue 中获取 segment。
5.4.3TCP栈相关代码分析
send和recv是TCP常用的发送数据和接受数据函数:
1 ssize_t recv(int sockfd, void *buf, size_t len, int flags) 2 ssize_t send(int sockfd, const void *buf, size_t len, int flags)
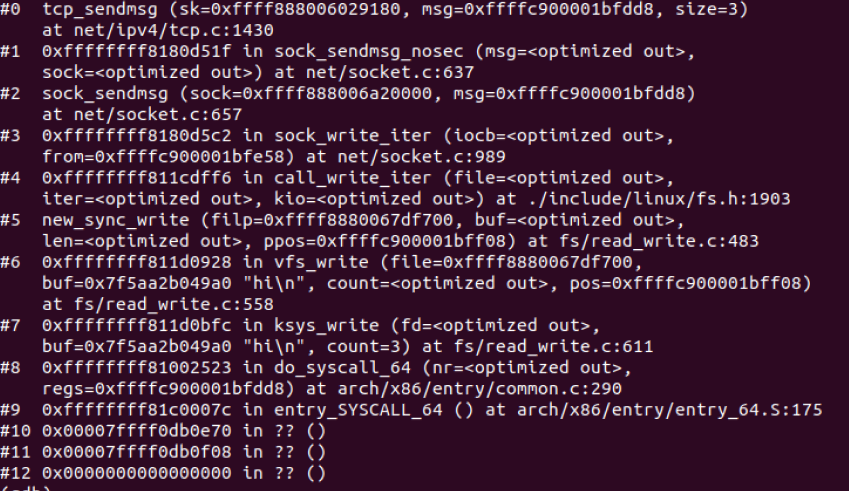
首先,当调用send()函数时,内核封装send()为sendto(),然后发起系统调用。其实也很好理解,send()就是sendto()的一种特殊情况,而sendto()在内核的系统调用服务程序为sys_sendto。
1 int __sys_sendto(int fd, void __user *buff, size_t len, unsigned int flags, 2 struct sockaddr __user *addr, int addr_len) 3 { 4 struct socket *sock; 5 struct sockaddr_storage address; 6 int err; 7 struct msghdr msg; 8 struct iovec iov; 9 int fput_needed; 10 err = import_single_range(WRITE, buff, len, &iov, &msg.msg_iter); 11 if (unlikely(err)) 12 return err; 13 sock = sockfd_lookup_light(fd, &err, &fput_needed); 14 if (!sock) 15 goto out; 16 17 msg.msg_name = NULL; 18 msg.msg_control = NULL; 19 msg.msg_controllen = 0; 20 msg.msg_namelen = 0; 21 if (addr) { 22 err = move_addr_to_kernel(addr, addr_len, &address); 23 if (err < 0) 24 goto out_put; 25 msg.msg_name = (struct sockaddr *)&address; 26 msg.msg_namelen = addr_len; 27 } 28 if (sock->file->f_flags & O_NONBLOCK) 29 flags |= MSG_DONTWAIT; 30 msg.msg_flags = flags; 31 err = sock_sendmsg(sock, &msg); 32 33 out_put: 34 fput_light(sock->file, fput_needed); 35 out: 36 return err; 37 }
这里定义了一个struct msghdr msg,它是用来表示要发送的数据的一些属性。
1 struct msghdr { 2 void *msg_name; /* 接收方的struct sockaddr结构体地址 (用于udp)*/ 3 int msg_namelen; /* 接收方的struct sockaddr结构体地址(用于udp)*/ 4 struct iov_iter msg_iter; /* io缓冲区的地址 */ 5 void *msg_control; /* 辅助数据的地址 */ 6 __kernel_size_t msg_controllen; /* 辅助数据的长度 */ 7 unsigned int msg_flags; /*接受消息的表示 */ 8 struct kiocb *msg_iocb; /* ptr to iocb for async requests */ 9 };
还有一个struct iovec,它被称为io向量,用来表示io数据的一些信息。
1 struct iovec 2 { 3 void __user *iov_base; /* 要传输数据的用户态下的地址*) */ 4 __kernel_size_t iov_len; /*要传输数据的长度 */ 5 };
所以,__sys_sendto函数其实做了3件事:1.通过fd获取了对应的struct socket。2.创建了用来描述要发送的数据的结构体struct msghdr。3.调用了sock_sendmsg来执行实际的发送。继续追踪这个函数,会看到最终调用的是sock->ops->sendmsg(sock,msg,msg_data_left(msg));,即socket在初始化时复制给结构体struct proto tcp_prot的函数tcp_sendmsg。
1 struct proto tcp_prot = { 2 .name = "TCP", 3 .owner = THIS_MODULE, 4 .close = tcp_close, 5 .pre_connect = tcp_v4_pre_connect, 6 .connect = tcp_v4_connect, 7 .disconnect = tcp_disconnect, 8 .accept = inet_csk_accept, 9 .ioctl = tcp_ioctl, 10 .init = tcp_v4_init_sock, 11 .destroy = tcp_v4_destroy_sock, 12 .shutdown = tcp_shutdown, 13 .setsockopt = tcp_setsockopt, 14 .getsockopt = tcp_getsockopt, 15 .keepalive = tcp_set_keepalive, 16 .recvmsg = tcp_recvmsg, 17 .sendmsg = tcp_sendmsg, 18 ...... 19 }
tcp_sendmsg实际上调用的是int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size)。
1 int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size) 2 { 3 struct tcp_sock *tp = tcp_sk(sk);/*进行了强制类型转换*/ 4 struct sk_buff *skb; 5 flags = msg->msg_flags; 6 ...... 7 if (copied) 8 tcp_push(sk, flags & ~MSG_MORE, mss_now, 9 TCP_NAGLE_PUSH, size_goal); 10 }
在tcp_sendmsg_locked中,完成的是将所有的数据组织成发送队列,这个发送队列是struct sock结构中的一个域sk_write_queue,这个队列的每一个元素是一个skb,里面存放的就是待发送的数据。然后调用了tcp_push()函数。
1 struct sock{ 2 ... 3 struct sk_buff_head sk_write_queue;/*指向skb队列的第一个元素*/ 4 ... 5 struct sk_buff *sk_send_head;/*指向队列第一个还没有发送的元素*/ 6 }
在tcp协议的头部有几个标志字段:URG、ACK、RSH、RST、SYN、FIN,tcp_push中会判断这个skb的元素是否需要push,如果需要就将tcp头部字段的push置一,置一的过程如下:
1 static void tcp_push(struct sock *sk, int flags, int mss_now, 2 int nonagle, int size_goal) 3 { 4 struct tcp_sock *tp = tcp_sk(sk); 5 struct sk_buff *skb; 6 7 skb = tcp_write_queue_tail(sk); 8 if (!skb) 9 return; 10 if (!(flags & MSG_MORE) || forced_push(tp)) 11 tcp_mark_push(tp, skb); 12 13 tcp_mark_urg(tp, flags); 14 15 if (tcp_should_autocork(sk, skb, size_goal)) { 16 17 /* avoid atomic op if TSQ_THROTTLED bit is already set */ 18 if (!test_bit(TSQ_THROTTLED, &sk->sk_tsq_flags)) { 19 NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPAUTOCORKING); 20 set_bit(TSQ_THROTTLED, &sk->sk_tsq_flags); 21 } 22 /* It is possible TX completion already happened 23 * before we set TSQ_THROTTLED. 24 */ 25 if (refcount_read(&sk->sk_wmem_alloc) > skb->truesize) 26 return; 27 } 28 29 if (flags & MSG_MORE) 30 nonagle = TCP_NAGLE_CORK; 31 32 __tcp_push_pending_frames(sk, mss_now, nonagle); 33 }
首先struct tcp_skb_cb结构体存放的就是tcp的头部,头部的控制位为tcp_flags,通过tcp_mark_push会将skb中的cb,也就是48个字节的数组,类型转换为struct tcp_skb_cb,这样位于skb的cb就成了tcp的头部。
1 static inline void tcp_mark_push(struct tcp_sock *tp, struct sk_buff *skb) 2 { 3 TCP_SKB_CB(skb)->tcp_flags |= TCPHDR_PSH; 4 tp->pushed_seq = tp->write_seq; 5 } 6 7 ... 8 #define TCP_SKB_CB(__skb) ((struct tcp_skb_cb *)&((__skb)->cb[0])) 9 ... 10 11 struct sk_buff { 12 ... 13 char cb[48] __aligned(8); 14 ... 15 }
1 struct tcp_skb_cb { 2 __u32 seq; /* Starting sequence number */ 3 __u32 end_seq; /* SEQ + FIN + SYN + datalen */ 4 __u8 tcp_flags; /* tcp头部标志,位于第13个字节tcp[13]) */ 5 ...... 6 };
然后,tcp_push调用__tcp_push_pending_frames(sk, mss_now, nonagle);函数发送数据:
1 void __tcp_push_pending_frames(struct sock *sk, unsigned int cur_mss, 2 int nonagle) 3 { 4 5 if (tcp_write_xmit(sk, cur_mss, nonagle, 0, 6 sk_gfp_mask(sk, GFP_ATOMIC))) 7 tcp_check_probe_timer(sk); 8 }
随后又调用了tcp_write_xmit来发送数据:
1 static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle, 2 int push_one, gfp_t gfp) 3 { 4 struct tcp_sock *tp = tcp_sk(sk); 5 struct sk_buff *skb; 6 unsigned int tso_segs, sent_pkts; 7 int cwnd_quota; 8 int result; 9 bool is_cwnd_limited = false, is_rwnd_limited = false; 10 u32 max_segs; 11 /*统计已发送的报文总数*/ 12 sent_pkts = 0; 13 ...... 14 15 /*若发送队列未满,则准备发送报文*/ 16 while ((skb = tcp_send_head(sk))) { 17 unsigned int limit; 18 19 if (unlikely(tp->repair) && tp->repair_queue == TCP_SEND_QUEUE) { 20 /* "skb_mstamp_ns" is used as a start point for the retransmit timer */ 21 skb->skb_mstamp_ns = tp->tcp_wstamp_ns = tp->tcp_clock_cache; 22 list_move_tail(&skb->tcp_tsorted_anchor, &tp->tsorted_sent_queue); 23 tcp_init_tso_segs(skb, mss_now); 24 goto repair; /* Skip network transmission */ 25 } 26 27 if (tcp_pacing_check(sk)) 28 break; 29 30 tso_segs = tcp_init_tso_segs(skb, mss_now); 31 BUG_ON(!tso_segs); 32 /*检查发送窗口的大小*/ 33 cwnd_quota = tcp_cwnd_test(tp, skb); 34 if (!cwnd_quota) { 35 if (push_one == 2) 36 /* Force out a loss probe pkt. */ 37 cwnd_quota = 1; 38 else 39 break; 40 } 41 42 if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now))) { 43 is_rwnd_limited = true; 44 break; 45 ...... 46 limit = mss_now; 47 if (tso_segs > 1 && !tcp_urg_mode(tp)) 48 limit = tcp_mss_split_point(sk, skb, mss_now, 49 min_t(unsigned int, 50 cwnd_quota, 51 max_segs), 52 nonagle); 53 54 if (skb->len > limit && 55 unlikely(tso_fragment(sk, TCP_FRAG_IN_WRITE_QUEUE, 56 skb, limit, mss_now, gfp))) 57 break; 58 59 if (tcp_small_queue_check(sk, skb, 0)) 60 break; 61 62 if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp))) 63 break; 64 ...... 65 }
tcp_write_xmit位于tcpoutput.c中,它实现了tcp的拥塞控制,然后调用了tcp_transmit_skb(sk, skb, 1, gfp)传输数据,实际上调用的是__tcp_transmit_skb。
1 static int __tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, 2 int clone_it, gfp_t gfp_mask, u32 rcv_nxt) 3 { 4 5 skb_push(skb, tcp_header_size); 6 skb_reset_transport_header(skb); 7 ...... 8 /* 构建TCP头部和校验和 */ 9 th = (struct tcphdr *)skb->data; 10 th->source = inet->inet_sport; 11 th->dest = inet->inet_dport; 12 th->seq = htonl(tcb->seq); 13 th->ack_seq = htonl(rcv_nxt); 14 15 tcp_options_write((__be32 *)(th + 1), tp, &opts); 16 skb_shinfo(skb)->gso_type = sk->sk_gso_type; 17 if (likely(!(tcb->tcp_flags & TCPHDR_SYN))) { 18 th->window = htons(tcp_select_window(sk)); 19 tcp_ecn_send(sk, skb, th, tcp_header_size); 20 } else { 21 /* RFC1323: The window in SYN & SYN/ACK segments 22 * is never scaled. 23 */ 24 th->window = htons(min(tp->rcv_wnd, 65535U)); 25 } 26 ...... 27 icsk->icsk_af_ops->send_check(sk, skb); 28 29 if (likely(tcb->tcp_flags & TCPHDR_ACK)) 30 tcp_event_ack_sent(sk, tcp_skb_pcount(skb), rcv_nxt); 31 32 if (skb->len != tcp_header_size) { 33 tcp_event_data_sent(tp, sk); 34 tp->data_segs_out += tcp_skb_pcount(skb); 35 tp->bytes_sent += skb->len - tcp_header_size; 36 } 37 38 if (after(tcb->end_seq, tp->snd_nxt) || tcb->seq == tcb->end_seq) 39 TCP_ADD_STATS(sock_net(sk), TCP_MIB_OUTSEGS, 40 tcp_skb_pcount(skb)); 41 42 tp->segs_out += tcp_skb_pcount(skb); 43 /* OK, its time to fill skb_shinfo(skb)->gso_{segs|size} */ 44 skb_shinfo(skb)->gso_segs = tcp_skb_pcount(skb); 45 skb_shinfo(skb)->gso_size = tcp_skb_mss(skb); 46 47 /* Leave earliest departure time in skb->tstamp (skb->skb_mstamp_ns) */ 48 49 /* Cleanup our debris for IP stacks */ 50 memset(skb->cb, 0, max(sizeof(struct inet_skb_parm), 51 sizeof(struct inet6_skb_parm))); 52 53 err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl); 54 ...... 55 }
tcp_transmit_skb是tcp发送数据位于传输层的最后一步,这里首先对TCP数据段的头部进行了处理,然后调用了网络层提供的发送接口icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.f1);实现了数据的发送,自此,数据离开了传输层,传输层的任务也就结束了。
对于recv函数,与send类似,自然也是recvfrom的特殊情况,调用的也就是__sys_recvfrom,整个函数的调用路径与send非常类似:
1 int __sys_recvfrom(int fd, void __user *ubuf, size_t size, unsigned int flags, 2 struct sockaddr __user *addr, int __user *addr_len) 3 { 4 ...... 5 err = import_single_range(READ, ubuf, size, &iov, &msg.msg_iter); 6 if (unlikely(err)) 7 return err; 8 sock = sockfd_lookup_light(fd, &err, &fput_needed); 9 ..... 10 msg.msg_control = NULL; 11 msg.msg_controllen = 0; 12 /* Save some cycles and don't copy the address if not needed */ 13 msg.msg_name = addr ? (struct sockaddr *)&address : NULL; 14 /* We assume all kernel code knows the size of sockaddr_storage */ 15 msg.msg_namelen = 0; 16 msg.msg_iocb = NULL; 17 msg.msg_flags = 0; 18 if (sock->file->f_flags & O_NONBLOCK) 19 flags |= MSG_DONTWAIT; 20 err = sock_recvmsg(sock, &msg, flags); 21 22 if (err >= 0 && addr != NULL) { 23 err2 = move_addr_to_user(&address, 24 msg.msg_namelen, addr, addr_len); 25 ..... 26 }
__sys_recvfrom调用了sock_recvmsg来接收数据,整个函数实际调用的是sock->ops->recvmsg(sock, msg, msg_data_left(msg), flags);,同样,根据tcp_prot结构的初始化,调用的其实是tcp_rcvmsg。接受函数比发送函数要复杂得多,因为数据接收不仅仅只是接收,tcp的三次握手也是在接收函数实现的,所以收到数据后要判断当前的状态,是否正在建立连接等,根据发来的信息考虑状态是否要改变,在这里,我们仅仅考虑在连接建立后数据的接收。
1 int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int nonblock, 2 int flags, int *addr_len) 3 { 4 ...... 5 if (sk_can_busy_loop(sk) && skb_queue_empty(&sk->sk_receive_queue) && 6 (sk->sk_state == TCP_ESTABLISHED)) 7 sk_busy_loop(sk, nonblock); 8 9 lock_sock(sk); 10 ..... 11 if (unlikely(tp->repair)) { 12 err = -EPERM; 13 if (!(flags & MSG_PEEK)) 14 goto out; 15 16 if (tp->repair_queue == TCP_SEND_QUEUE) 17 goto recv_sndq; 18 19 err = -EINVAL; 20 if (tp->repair_queue == TCP_NO_QUEUE) 21 goto out; 22 ...... 23 last = skb_peek_tail(&sk->sk_receive_queue); 24 skb_queue_walk(&sk->sk_receive_queue, skb) { 25 last = skb; 26 ...... 27 if (!(flags & MSG_TRUNC)) { 28 err = skb_copy_datagram_msg(skb, offset, msg, used); 29 if (err) { 30 /* Exception. Bailout! */ 31 if (!copied) 32 copied = -EFAULT; 33 break; 34 } 35 } 36 37 *seq += used; 38 copied += used; 39 len -= used; 40 41 tcp_rcv_space_adjust(sk); 42 ...... 43 }
这里共维护了三个队列:prequeue、backlog、receive_queue、分别为预处理队列,后备队列和接收队列,在连接建立后,若没有数据到来,接收队列为空,进程会在sk_busy_loop函数内循环等待,知道接收队列不为空,并调用函数skb_copy_datagram_msg将接收到的数据拷贝到用户态,实际调用的是__skb_datagram_iter,这里同样用了struct msghdr *msg来实现。
1 int __skb_datagram_iter(const struct sk_buff *skb, int offset, 2 struct iov_iter *to, int len, bool fault_short, 3 size_t (*cb)(const void *, size_t, void *, struct iov_iter *), 4 void *data) 5 { 6 int start = skb_headlen(skb); 7 int i, copy = start - offset, start_off = offset, n; 8 struct sk_buff *frag_iter; 9 10 /* 拷贝tcp头部 */ 11 if (copy > 0) { 12 if (copy > len) 13 copy = len; 14 n = cb(skb->data + offset, copy, data, to); 15 offset += n; 16 if (n != copy) 17 goto short_copy; 18 if ((len -= copy) == 0) 19 return 0; 20 } 21 22 /* 拷贝数据部分 */ 23 for (i = 0; i < skb_shinfo(skb)->nr_frags; i++) { 24 int end; 25 const skb_frag_t *frag = &skb_shinfo(skb)->frags[i]; 26 27 WARN_ON(start > offset + len); 28 29 end = start + skb_frag_size(frag); 30 if ((copy = end - offset) > 0) { 31 struct page *page = skb_frag_page(frag); 32 u8 *vaddr = kmap(page); 33 34 if (copy > len) 35 copy = len; 36 n = cb(vaddr + frag->page_offset + 37 offset - start, copy, data, to); 38 kunmap(page); 39 offset += n; 40 if (n != copy) 41 goto short_copy; 42 if (!(len -= copy)) 43 return 0; 44 } 45 start = end; 46 } 47 }
拷贝完成后,函数返回,整个接收的过程也就完成了。
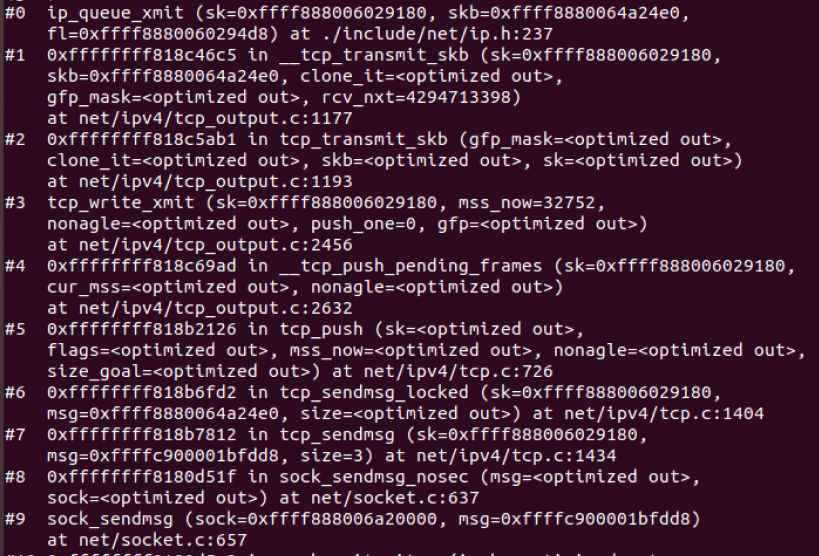
5.4.4 调试结果
5.5 网络层
网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。网络层将数据链路层提供的帧组成数据包,包中封装有网络层包头,其中含有逻辑地址信息- -源站点和目的站点地址的网络地址。其主要任务包括
(1)路由处理,即选择下一跳
(2)添加 IP header
(3)计算 IP header checksum,用于检测 IP 报文头部在传播过程中是否出错
(4)可能的话,进行 IP 分片
(5)处理完毕,获取下一跳的 MAC 地址,设置链路层报文头,然后转入链路层处理。
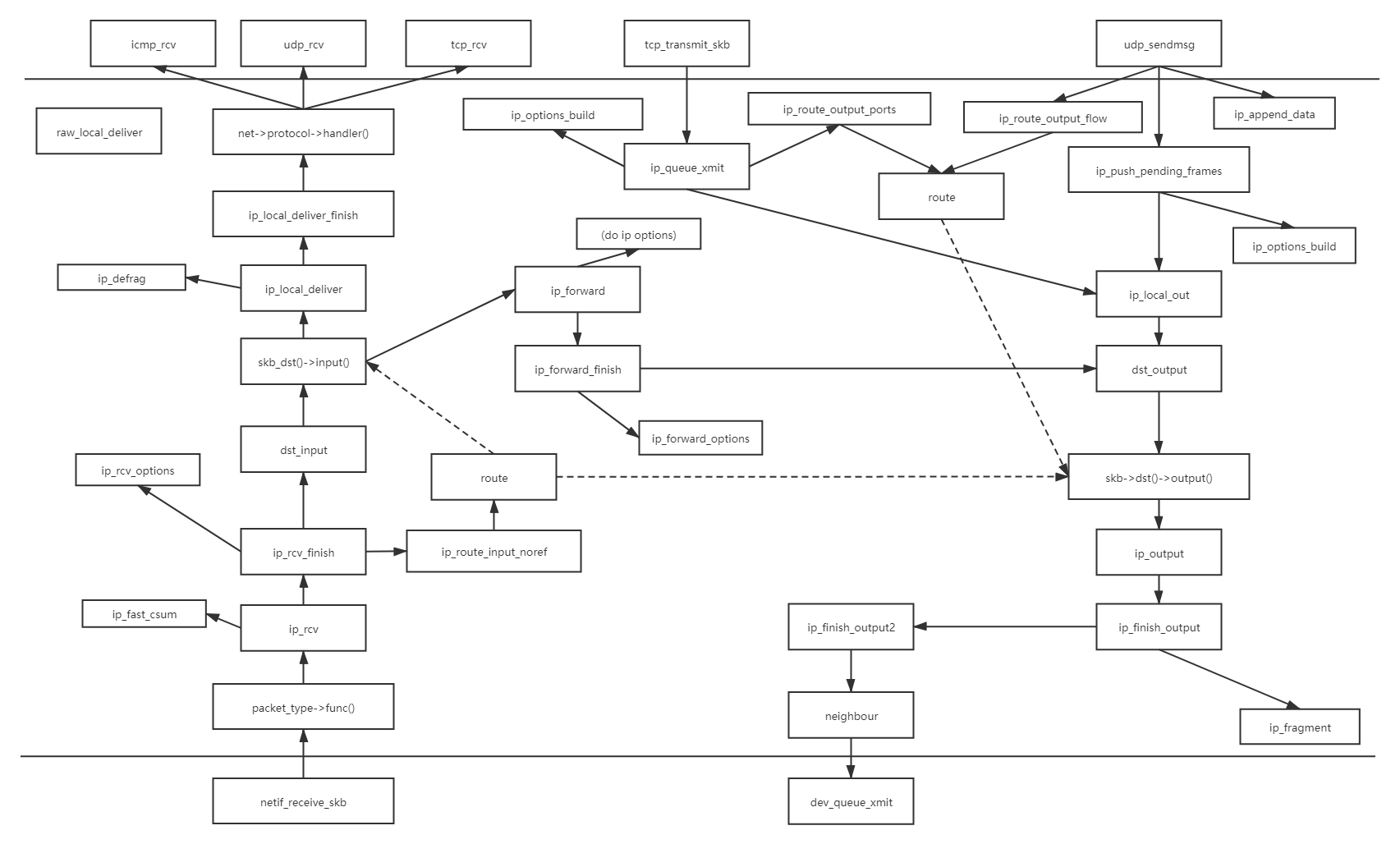
IP协议栈的大致流程图:
5.5.1 网络层发送数据过程简介
1.首先,ip_queue_xmit(skb)会检查skb->dst路由信息。如果没有,比如套接字的第一个包,就使用ip_route_output()选择一个路由。
2.接着,填充IP包的各个字段,比如版本、包头长度、TOS等。
3.中间的一些分片等,可参阅相关文档。基本思想是,当报文的长度大于mtu,gso的长度不为0就会调用 ip_fragment 进行分片,否则就会调用ip_finish_output2把数据发送出去。ip_fragment 函数中,会检查 IP_DF 标志位,如果待分片IP数据包禁止分片,则调用 icmp_send()向发送方发送一个原因为需要分片而设置了不分片标志的目的不可达ICMP报文,并丢弃报文,即设置IP状态为分片失败,释放skb,返回消息过长错误码。
4.接下来就用 ip_finish_ouput2 设置链路层报文头了。如果,链路层报头缓存有(即hh不为空),那就拷贝到skb里。如果没,那么就调用neigh_resolve_output,使用 ARP 获取。
5.5.2 网络层接收数据过程简介
1.IP层的入口函数在 ip_rcv 函数。该函数首先会做包括 package checksum 在内的各种检查,如果需要的话会做 IP defragment(将多个分片合并),然后 packet 调用已经注册的 Pre-routing netfilter hook ,完成后最终到达 ip_rcv_finish 函数。
2.ip_rcv_finish 函数会调用 ip_router_input 函数,进入路由处理环节。它首先会调用 ip_route_input 来更新路由,然后查找 route,决定该 package 将会被发到本机还是会被转发还是丢弃: (1)如果是发到本机的话,调用 ip_local_deliver 函数,可能会做 de-fragment(合并多个 IP packet),然后调用 ip_local_deliver 函数。该函数根据 package 的下一个处理层的 protocal number,调用下一层接口,包括 tcp_v4_rcv (TCP), udp_rcv (UDP),icmp_rcv (ICMP),igmp_rcv(IGMP)。对于 TCP 来说,函数 tcp_v4_rcv 函数会被调用,从而处理流程进入 TCP 栈。(2)如果需要转发 (forward),则进入转发流程。该流程需要处理 TTL,再调用 dst_input 函数。该函数会 <1>处理 Netfilter Hook<2>执行 IP fragmentation<3>调用 dev_queue_xmit,进入链路层处理流程。
5.5.3网络层相关代码分析
ip宏定义实现
1 //IP首部长度 2 #define IP_HEADER_LEN 20 3 4 //IP版本号位置 以太网首部2+6+6,与下面那个在用的时候上区别下 5 #define IP_HEADER_LEN_VER_P 0xe 6 7 //IP版本号位置 以太网首部2+6+6 8 #define IP_P 0xe 9 //IP 16位标志位置 10 #define IP_FLAGS_P 0x14 11 //IP 生存时间位置 12 #define IP_TTL_P 0x16 13 //IP协议类型位置,如ICMP,TCP,UDP 1个字节 14 #define IP_PROTO_P 0x17 15 //首部校验和 16 #define IP_CHECKSUM_P 0x18 17 // IP源地址位置 14+12 18 #define IP_SRC_P 0x1a 19 // IP目标地址位置 14+12+4 20 #define IP_DST_P 0x1e 21 22 //IP总长度 23 #define IP_TOTLEN_H_P 0x10 24 #define IP_TOTLEN_L_P 0x11 25 26 //协议类型 27 #define IP_PROTO_ICMP_V 0x01 28 #define IP_PROTO_TCP_V 0x06 29 #define IP_PROTO_UDP_V 0x11
在IP数据包前增加以太网header
1 // make a return eth header from a received eth packet 2 void make_eth( unsigned char *buf) 3 { 4 unsigned char i = 0; 5 6 //copy the destination mac from the source and fill my mac into src 7 while(i < sizeof(mac_addr)) 8 { 9 buf[ETH_DST_MAC + i] = buf[ETH_SRC_MAC + i]; 10 buf[ETH_SRC_MAC + i] = macaddr[i]; 11 i++; 12 } 13 }
判定是否发给本机的函数,填充函数,以及校验和函数
1 //判定过程与eth_type_is_arp_and_my_ip类似 2 unsigned char eth_type_is_ip_and_my_ip( unsigned char *buf, unsigned int len) 3 { 4 unsigned char i = 0; 5 6 //eth+ip+udp header is 42 7 if(len < MIN_FRAMELEN) 8 { 9 return( 0); 10 } 11 12 if(buf[ETH_TYPE_H_P] != ETHTYPE_IP_H_V || buf[ETH_TYPE_L_P] != ETHTYPE_IP_L_V) 13 { 14 return( 0); 15 } 16 17 if(buf[IP_HEADER_LEN_VER_P] != 0x45) 18 { 19 // must be IP V4 and 20 byte header 20 return( 0); 21 } 22 23 while(i < sizeof(ipv4_addr)) 24 { 25 if(buf[IP_DST_P + i] != ipaddr[i]) 26 { 27 return( 0); 28 } 29 30 i++; 31 } 32 33 return( 1); 34 } 35 //下面那个ip填充函数调用它,主要是补充填充和校验和 36 void fill_ip_hdr_checksum( unsigned char *buf) 37 { 38 unsigned int ck; 39 // clear the 2 byte checksum 40 buf[IP_CHECKSUM_P] = 0; 41 buf[IP_CHECKSUM_P + 1] = 0; 42 buf[IP_FLAGS_P] = 0x40; // don't fragment 43 buf[IP_FLAGS_P + 1] = 0; // fragement offset 44 buf[IP_TTL_P] = 64; // ttl 45 // calculate the checksum: 46 //校验和计算,在下下面那个函数里面,输入参数的含义下面看就晓得了 47 ck = checksum(&buf[IP_P], IP_HEADER_LEN, 0); 48 buf[IP_CHECKSUM_P] = ck >> 8; 49 buf[IP_CHECKSUM_P + 1] = ck & 0xff; 50 } 51 52 // make a return ip header from a received ip packet 53 //与以太网填充函数类似,填充ip地址 54 void make_ip( unsigned char *buf) 55 { 56 unsigned char i = 0; 57 58 while(i < sizeof(ipv4_addr)) 59 { 60 buf[IP_DST_P + i] = buf[IP_SRC_P + i]; 61 buf[IP_SRC_P + i] = ipaddr[i]; 62 i++; 63 } 64 65 fill_ip_hdr_checksum(buf); 66 }
校验和的具体实现
1 unsigned int checksum( unsigned char * buf, unsigned int len, unsigned char type) 2 { 3 // type 0=ip 4 // 1=udp 5 // 2=tcp 6 unsigned long sum = 0; 7 8 //if(type==0){ 9 // // do not add anything 10 //} 11 if(type== 1) 12 { 13 sum+=IP_PROTO_UDP_V; // protocol udp 14 // the length here is the length of udp (data+header len) 15 // =length given to this function - (IP.scr+IP.dst length) 16 sum+=len- 8; // = real tcp len 17 } 18 if(type== 2) 19 { 20 sum+=IP_PROTO_TCP_V; 21 // the length here is the length of tcp (data+header len) 22 // =length given to this function - (IP.scr+IP.dst length) 23 sum+=len- 8; // = real tcp len 24 } 25 // build the sum of 16bit words 26 while(len > 1) 27 { 28 sum += 0xFFFF & (*buf<<8|*(buf+ 1)); 29 buf+= 2; 30 len-= 2; 31 } 32 // if there is a byte left then add it (padded with zero) 33 if (len) 34 { 35 sum += (0xFF & *buf)<< 8; 36 } 37 // now calculate the sum over the bytes in the sum 38 // until the result is only 16bit long 39 while (sum>> 16) 40 { 41 sum = (sum & 0xFFFF)+(sum >> 16); 42 } 43 // build 1's complement: 44 return( ( unsigned int) sum ^ 0xFFFF); 45 }
5.5.4 调试结果

6. 时序图


 浙公网安备 33010602011771号
浙公网安备 33010602011771号