
HashMap
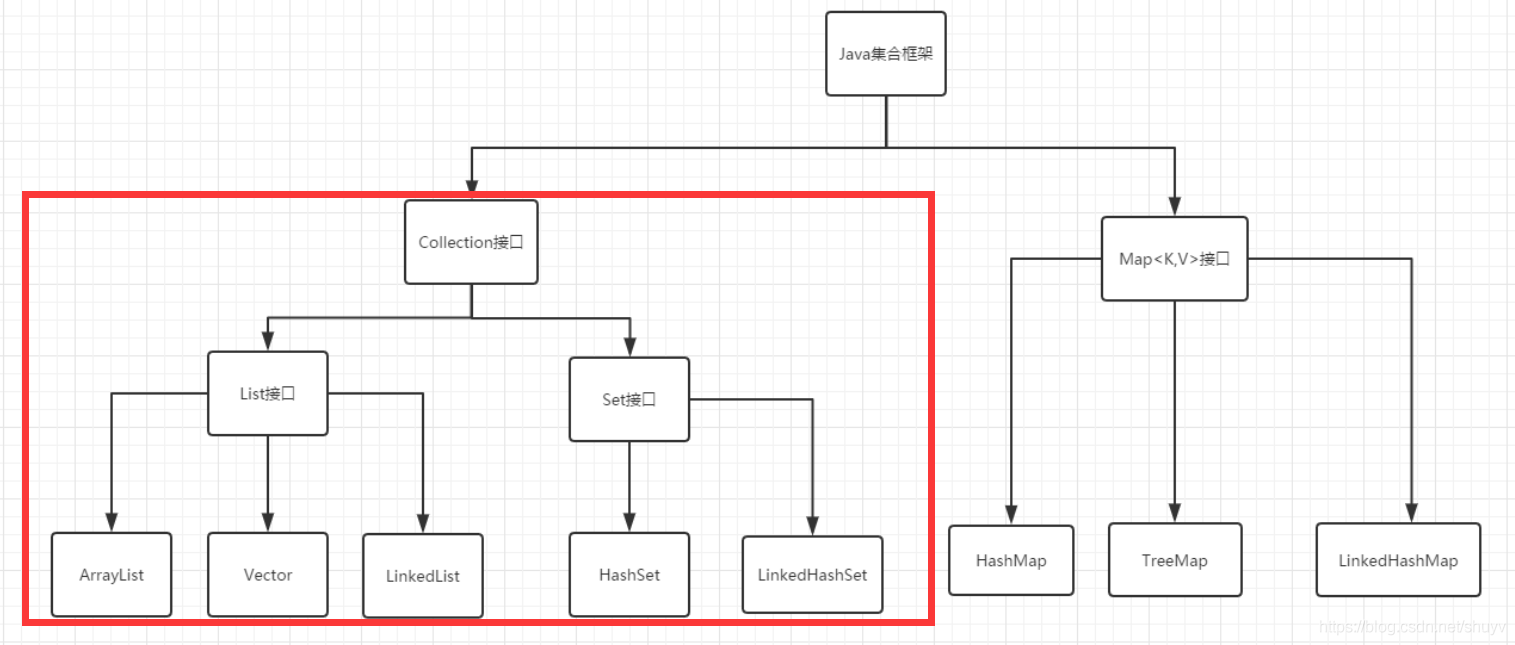
1、ArrayList和LinkedList和vector的异同点:
相同点:都实现了List接口,可存储有序、可重复的元素
ArrayList的底层实现是动态数组 (1)适合随机访问某个元素,查询快,增删慢
(2)线程不安全的,存储效率高
(3)扩容时,ArrayList容量会增长为原来的1.5倍
LinkedList的底层实现是双向链表 适合频繁的插入删除元素,线程不安全的
vector的底层实现是数组 (1)是线程安全的,底层使用synchronize进行加锁,但是存储效率并不高
(2)扩容时,vector容量会增长为原来的2倍
2、 HashMap在JDK7中的实现原理以及底层源码
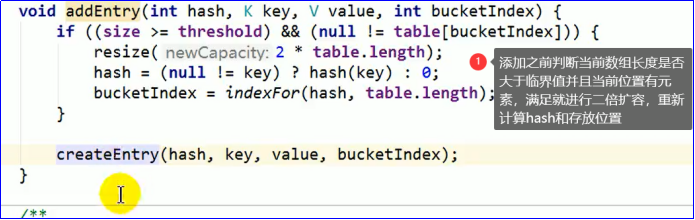
threshold代表数组临界值 超过临界值就会自动扩容 threshold = capacity * 负载因子
题目一:为什么负载因子是0.75
如果设置1:即数组空间都用完后在进行扩容,空间利用率得到了保证,但很容易产生链表,一旦产生链表查找效率就会变低
如果设置为0.5:空间利用率得不到保证
所以在他们之间取中间值
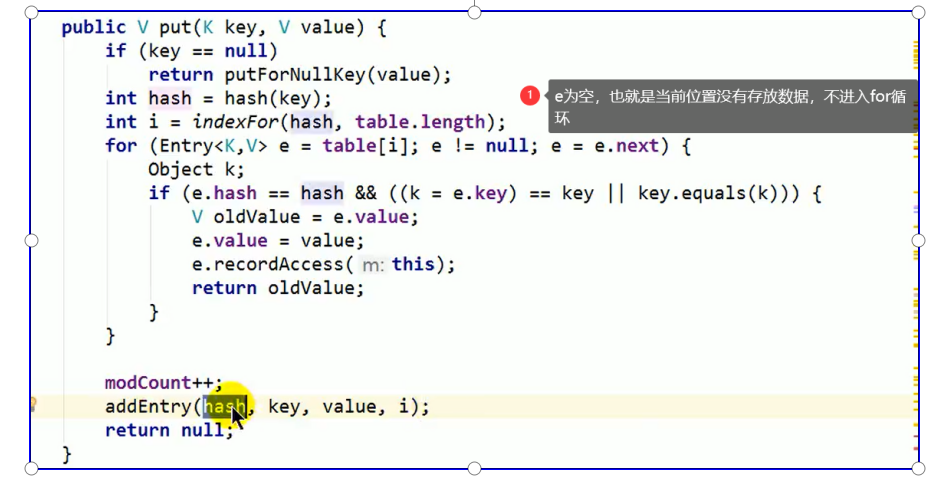
key的hashcode可能不同 但是计算出来的数组存放位置可能一样
如果两个key的hashcode不一样一定不相同
如果两个key的hashcode一样 不一定相同,还需要调用equals方法比较
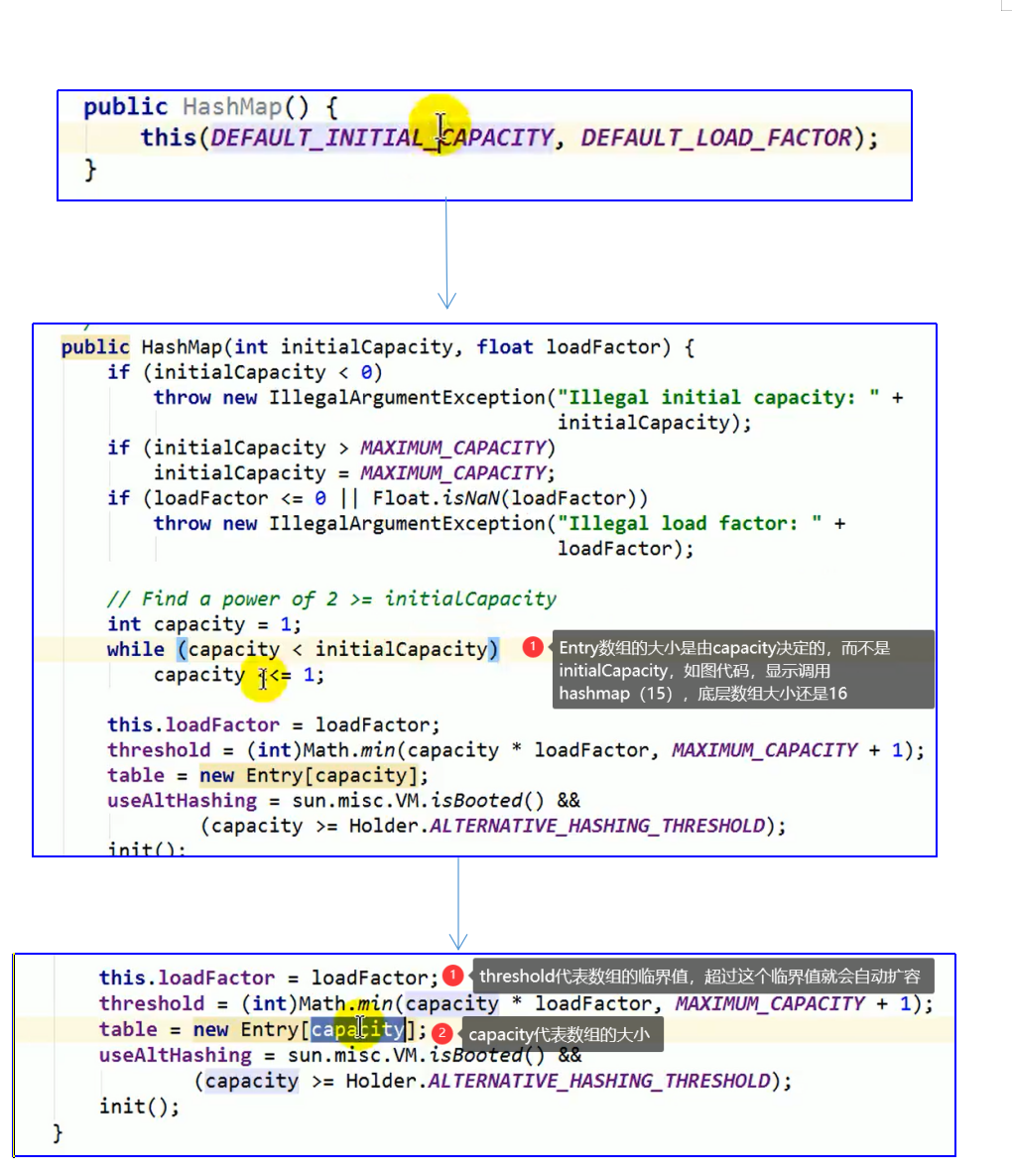
(1)HashMap map = new HashMap();在实例化以后,底层创建了长度为16的一维数组,Entry[ ] table
(2)如图思维导图

(3)HashMap在jdk7中的底层源码
第一步:实例化后底层源码
第二步:put调用底层源码
第三步 添加操作 调用addEntry函数
第四步 调用createEntry函数

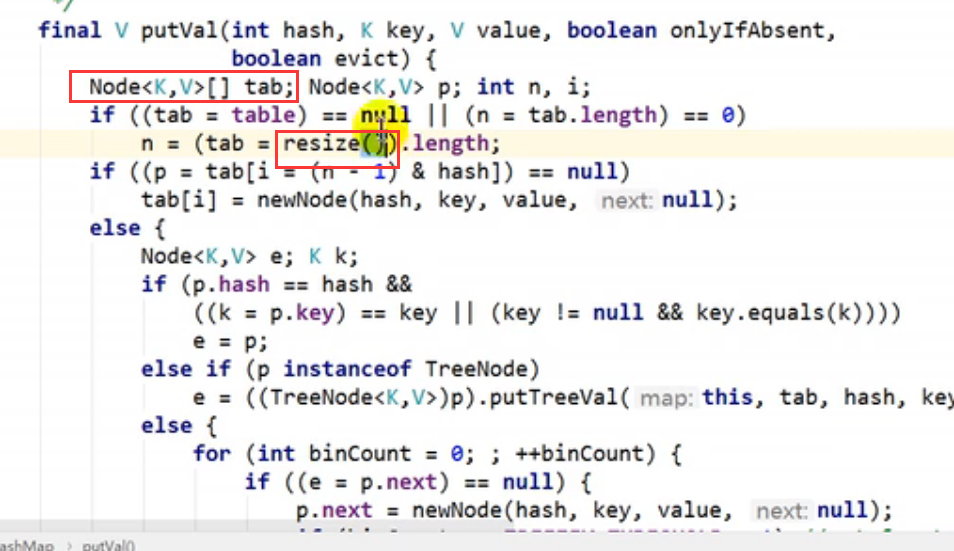
3、 HashMap在JDK8中的实现原理以及源码分析
(1)HashMap map = new HashMap();在实例化以后,底层没有创建数组,而是首次调用put方法时,底层创建长度为16的数组 Node[ ]
jdk7中的底层结构是数组+链表 jdk8的底层结构是数组+链表+红黑树 ,当数组上的某一索引位置上的元素以链表形式存在的数据个数 >8 ,并且当前数组长度 >64的时候,此时次索引位置上的数据用红黑树存储
(2)源码分析
第一步:

第二步:

第三步:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号