基于COCA词频表的文本词汇分布测试工具v0.1
美国语言协会对美国人日常使用的英语单词做了一份详细的统计,按照日常使用的频率做成了一张表,称为COCA词频表。排名越低的单词使用频率越高,该表可以用来统计词汇量。
如果你的词汇量约为6000,那么这张表频率6000以下的单词你应该基本都认识。(不过国内教育平时学的单词未必就是他们常用的,只能说大部分重合)

我一直有个想法,要是能用COCA词频表统计一本小说中所有的词汇都是什么等级的,然后根据自己的词汇量,就能大致确定这本小说是什么难度,自己能不能读了。
学习了C++的容器和标准库算法后,我发现这个想法很容易实现,于是写了个能够统计文本词频的小工具。现在只实现了基本功能,写得比较糙。还有很多要改进的地方,随着以后的学习,感觉这个工具还是可以再深挖的。
v0.1
1.可逐个分析文本中的每一个单词并得到其COCA词频,生成统计报告。
2.仅支持txt。
实现的重点主要分三块。
(1)COCA词典的建立
首先建立出COCA词典。我使用了恶魔的奶爸公众号提供的txt格式的COCA词频表,这张表是经过处理的,每行只有一个单词和对应的频率,所以读取起来很方便。
读取文本后,用map容器来建立“单词——频率”的一对一映射。
要注意的是有些单词因为使用意思和词性的不同,统计表里会出现两个频率,也就是熟词的偏僻意思。我只取了较低的那个为准,因为你读文本时,虽然可能不是真正的意思但起码这个单词是认识的,而且这种情况总体来说比较少见,所以影响不大。
存储时我用了26组map,一个首字母存一组,单词查询时按首字母查找。可能有更有效率的办法。
(2)单词的获取和处理
使用get()方法逐个获取文本的字符。
使用vector容器存储读到的文本内容。如果是字母或连字符就push进去,如果不是,就意味着一个单词读完了,接着开始处理,把读到的文本内容assign到一个字符串中组成完整的单词,然后根据其首字母查找词频。
每个单词查到词频后,使用自定义的frequency_classify()区分它在什么范围,再用word_frequency_analyze()统计在不同等级的分布。
最后报告结果,显示出每个等级的百分比。
(3)单词的修正
首先是分析过的单词不会再分析第二遍,因为一般原文中像I,he,she,it,a,this,that这种特别常见的词还是很多的,如果每个都统计进去,会导致不同文章看到的结果都是高频词占到80%,90%。应该以单词的种类为准,而不是数量。
其次有很多单词的变形COCA词频表是不统计的,像许多单词的过去式,复数,进行时等,还有was,were,has,had等。所以我单独加了word_usual_recheck()和word_form_recheck()两个函数来检查是否有这些情况,如果有变形的话,就变为原型再尝试查找一次。但是这样做相当于手动修正,不能覆盖到所有情况,比如有些单词的变形并不遵循传统。
我先用了乔布斯斯坦福大学的演讲稿测试。测试结果:
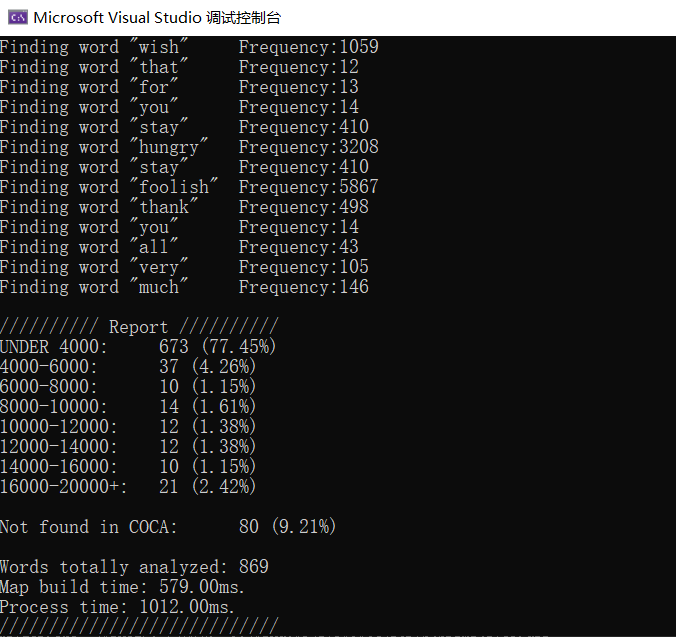
总共分析了869个单词,77.45%的单词都找到了,且分布在4000以下,可见演讲稿使用的绝大多数的单词都是极其常用的单词,有4000以上的词汇量就基本能读懂。
我再测试了一下《小王子》的原文。
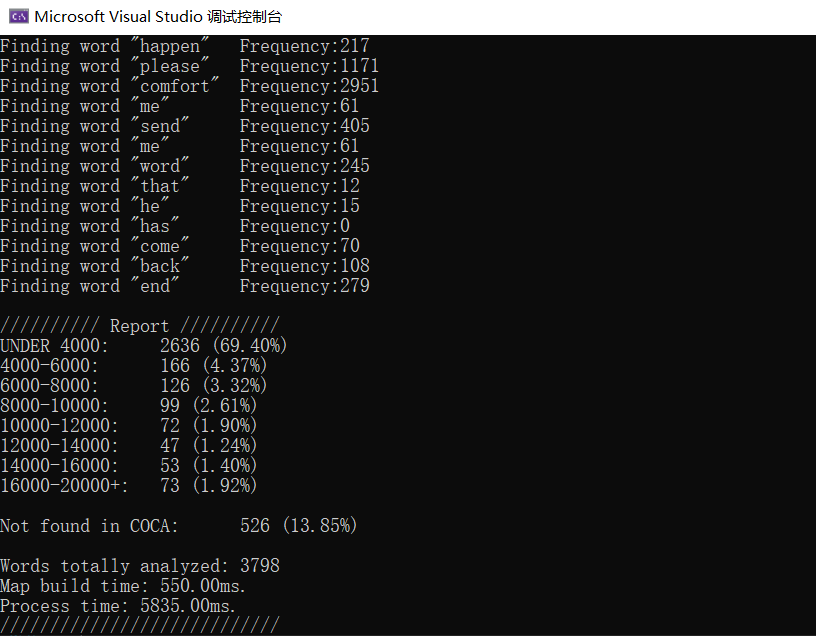
约70%的单词都找到了,且分布在4000以下,再加上4000-8000之间的,总共有接近80%的单词是六七千以下的级别。
为了对比,我再随便找了一篇纽约客上的文章测试。
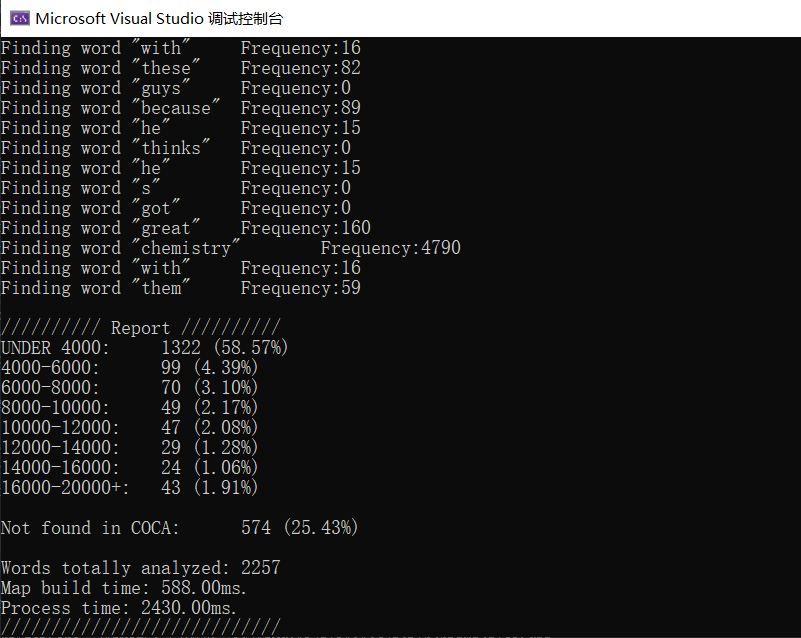
可以看到,高频词的比例明显降低了一些,约有10%的单词是8000以上的级别,还有更多的单词找不到了,说明出现了许多单词的变形,当然也可能包括人名,毕竟是讨论政治的文章,还有小部分可能是超出20000。
以下是代码。
TextVolcabularyAnalyzer.cpp
1 #include <iostream> 2 #include <fstream> 3 #include <string> 4 #include <algorithm> 5 #include <array> 6 #include <vector> 7 #include <iterator> 8 #include <map> 9 #include <numeric> 10 #include <iomanip> 11 #include <ctime> 12 13 #define COCA_WORDS_NUM 20201U 14 #define WORDS_HEAD_NUM 26U 15 16 #define WORDS_HEAD_A 0U 17 #define WORDS_HEAD_B 1U 18 #define WORDS_HEAD_C 2U 19 #define WORDS_HEAD_D 3U 20 #define WORDS_HEAD_E 4U 21 #define WORDS_HEAD_F 5U 22 #define WORDS_HEAD_G 6U 23 #define WORDS_HEAD_H 7U 24 #define WORDS_HEAD_I 8U 25 #define WORDS_HEAD_J 9U 26 #define WORDS_HEAD_K 10U 27 #define WORDS_HEAD_L 11U 28 #define WORDS_HEAD_M 12U 29 #define WORDS_HEAD_N 13U 30 #define WORDS_HEAD_O 14U 31 #define WORDS_HEAD_P 15U 32 #define WORDS_HEAD_Q 16U 33 #define WORDS_HEAD_R 17U 34 #define WORDS_HEAD_S 18U 35 #define WORDS_HEAD_T 19U 36 #define WORDS_HEAD_U 20U 37 #define WORDS_HEAD_V 21U 38 #define WORDS_HEAD_W 22U 39 #define WORDS_HEAD_X 23U 40 #define WORDS_HEAD_Y 24U 41 #define WORDS_HEAD_Z 25U 42 43 #define USUAL_WORD_NUM 17U 44 45 using namespace std; 46 47 typedef enum WordFrequencyType 48 { 49 WORD_UNDER_4000 = 0, 50 WORD_4000_6000, 51 WORD_6000_8000, 52 WORD_8000_10000, 53 WORD_10000_12000, 54 WORD_12000_14000, 55 WORD_14000_16000, 56 WORD_OVER_16000, 57 WORD_NOT_FOUND_COCA, 58 WORD_LEVEL_NUM 59 }TagWordFrequencyType; 60 61 const string alphabet_str = "abcdefghijklmnopqrstuvwxyz"; 62 63 const string report_str[WORD_LEVEL_NUM] = { 64 "UNDER 4000: ", 65 "4000-6000: ", 66 "6000-8000: ", 67 "8000-10000: ", 68 "10000-12000: ", 69 "12000-14000: ", 70 "14000-16000: ", 71 "16000-20000+: ", 72 "\nNot found in COCA:" 73 }; 74 75 //for usual words not included in COCA 76 const string usual_w_out_of_COCA_str[USUAL_WORD_NUM] = 77 { 78 "s","is","are","re","was","were", 79 "an","won","t","has","had","been", 80 "did","does","cannot","got","men" 81 }; 82 83 bool word_usual_recheck(const string &ws) 84 { 85 bool RetVal = false; 86 for (int i = 0; i < USUAL_WORD_NUM;i++) 87 { 88 if (ws == usual_w_out_of_COCA_str[i]) 89 { 90 RetVal = true; 91 } 92 else 93 { 94 //do nothing 95 } 96 } 97 return RetVal; 98 } 99 100 bool word_form_recheck(string& ws) 101 { 102 bool RetVal = false; 103 if (ws.length() > 3) 104 { 105 char e1, e2,e3; 106 e3 = ws[ws.length() - 3]; //last but two letter 107 e2 = ws[ws.length() - 2]; //last but one letter 108 e1 = ws[ws.length() - 1]; //last letter 109 110 if (e1 == 's') 111 { 112 ws.erase(ws.length() - 1); 113 RetVal = true; 114 } 115 else if (e2 == 'e' && e1 == 'd') 116 { 117 ws.erase(ws.length() - 1); 118 ws.erase(ws.length() - 1); 119 RetVal = true; 120 } 121 else if (e3 == 'i' && e2 == 'n' && e1 == 'g') 122 { 123 ws.erase(ws.length() - 1); 124 ws.erase(ws.length() - 1); 125 ws.erase(ws.length() - 1); 126 RetVal = true; 127 } 128 else 129 { 130 //do nothing 131 } 132 } 133 134 return RetVal; 135 } 136 137 TagWordFrequencyType frequency_classify(const int wfrq) 138 { 139 if (wfrq == 0) 140 { 141 return WORD_NOT_FOUND_COCA; 142 } 143 else if (wfrq > 0 && wfrq <= 4000) 144 { 145 return WORD_UNDER_4000; 146 } 147 else if (wfrq > 4000 && wfrq <= 6000) 148 { 149 return WORD_4000_6000; 150 } 151 else if (wfrq > 6000 && wfrq <= 8000) 152 { 153 return WORD_6000_8000; 154 } 155 else if (wfrq > 8000 && wfrq <= 10000) 156 { 157 return WORD_8000_10000; 158 } 159 else if (wfrq > 10000 && wfrq <= 12000) 160 { 161 return WORD_10000_12000; 162 } 163 else if (wfrq > 12000 && wfrq <= 14000) 164 { 165 return WORD_12000_14000; 166 } 167 else if (wfrq > 14000 && wfrq <= 16000) 168 { 169 return WORD_14000_16000; 170 } 171 else 172 { 173 return WORD_OVER_16000; 174 } 175 } 176 177 void word_frequency_analyze(array<int, WORD_LEVEL_NUM> & wfrq_array, TagWordFrequencyType wfrq_tag) 178 { 179 switch (wfrq_tag) 180 { 181 case WORD_UNDER_4000: 182 { 183 wfrq_array[WORD_UNDER_4000] += 1; 184 break; 185 } 186 case WORD_4000_6000: 187 { 188 wfrq_array[WORD_4000_6000] += 1; 189 break; 190 } 191 case WORD_6000_8000: 192 { 193 wfrq_array[WORD_6000_8000] += 1; 194 break; 195 } 196 case WORD_8000_10000: 197 { 198 wfrq_array[WORD_8000_10000] += 1; 199 break; 200 } 201 case WORD_10000_12000: 202 { 203 wfrq_array[WORD_10000_12000] += 1; 204 break; 205 } 206 case WORD_12000_14000: 207 { 208 wfrq_array[WORD_12000_14000] += 1; 209 break; 210 } 211 case WORD_14000_16000: 212 { 213 wfrq_array[WORD_14000_16000] += 1; 214 break; 215 } 216 case WORD_OVER_16000: 217 { 218 wfrq_array[WORD_OVER_16000] += 1; 219 break; 220 } 221 default: 222 { 223 wfrq_array[WORD_NOT_FOUND_COCA] += 1; 224 break; 225 } 226 } 227 } 228 229 bool isaletter(const char& c) 230 { 231 if ((c >= 'a' && c <= 'z') || (c >= 'A' && c<= 'Z')) 232 { 233 return true; 234 } 235 else 236 { 237 return false; 238 } 239 } 240 241 int main() 242 { 243 //file init 244 ifstream COCA_txt("D:\\COCA.txt"); 245 ifstream USER_txt("D:\\test.txt"); 246 247 //time init 248 clock_t startTime, endTime; 249 double build_map_time = 0; 250 double process_time = 0; 251 252 startTime = clock(); //build time start 253 254 //build COCA words map 255 map<string, int> COCA_WordsList[WORDS_HEAD_NUM]; 256 int readlines = 0; 257 258 while (readlines < COCA_WORDS_NUM) 259 { 260 int frequency = 0; string word = ""; 261 COCA_txt >> frequency; 262 COCA_txt >> word; 263 264 //transform to lower uniformly 265 transform(word.begin(), word.end(), word.begin(), tolower); 266 267 //import every word 268 for (int whead = WORDS_HEAD_A; whead < WORDS_HEAD_NUM; whead++) 269 { 270 //check word head 271 if (word[0] == alphabet_str[whead]) 272 { 273 //if a word already exists, only load its lower frequency 274 if (COCA_WordsList[whead].find(word) == COCA_WordsList[whead].end()) 275 { 276 COCA_WordsList[whead].insert(make_pair(word, frequency)); 277 } 278 else 279 { 280 COCA_WordsList[whead][word] = frequency < COCA_WordsList[whead][word] ? frequency : COCA_WordsList[whead][word]; 281 } 282 } 283 else 284 { 285 // do nothing 286 } 287 } 288 readlines++; 289 } 290 291 endTime = clock(); //build time stop 292 build_map_time = (double)(endTime - startTime) / CLOCKS_PER_SEC; 293 294 //user prompt 295 cout << "COCA words list imported.\nPress any key to start frequency analysis...\n"; 296 cin.get(); 297 298 startTime = clock(); //process time start 299 300 //find text words 301 vector<char> content_read; 302 string word_readed; 303 vector<int> frequecy_processed = { 0 }; 304 array<int, WORD_LEVEL_NUM> words_analysis_array{ 0 }; 305 char char_read = ' '; 306 307 //get text char one by one 308 while (USER_txt.get(char_read)) 309 { 310 //only letters and '-' between letters will be received 311 if (isaletter(char_read) || char_read == '-') 312 { 313 content_read.push_back(char_read); 314 } 315 else 316 { 317 //char which is not a letter marks the end of a word 318 if (!content_read.empty()) //skip single letter 319 { 320 int current_word_frequency = 0; 321 322 //assign letters to make the word 323 word_readed.assign(content_read.begin(), content_read.end()); 324 transform(word_readed.begin(), word_readed.end(), word_readed.begin(), tolower); 325 326 cout << "Finding word \"" << word_readed << "\" \t"; 327 cout << "Frequency:"; 328 329 //check the word's head and find its frequency in COCA list 330 for (int whead = WORDS_HEAD_A; whead < WORDS_HEAD_NUM; whead++) 331 { 332 if (word_readed[0] == alphabet_str[whead]) 333 { 334 cout << COCA_WordsList[whead][word_readed]; 335 current_word_frequency = COCA_WordsList[whead][word_readed]; 336 337 //check if the word has been processed 338 if (current_word_frequency == 0) 339 { 340 //addtional check 341 if (word_usual_recheck(word_readed)) 342 { 343 word_frequency_analyze(words_analysis_array, WORD_UNDER_4000); 344 } 345 else if (word_form_recheck(word_readed)) 346 { 347 current_word_frequency = COCA_WordsList[whead][word_readed]; //try again 348 if (current_word_frequency > 0) 349 { 350 frequecy_processed.push_back(current_word_frequency); 351 word_frequency_analyze(words_analysis_array, frequency_classify(current_word_frequency)); 352 } 353 else 354 { 355 // do nothing 356 } 357 } 358 else 359 { 360 word_frequency_analyze(words_analysis_array, WORD_NOT_FOUND_COCA); 361 } 362 } 363 else if (find(frequecy_processed.begin(), frequecy_processed.end(), current_word_frequency) 364 == frequecy_processed.end()) 365 { 366 //classify this word and make statistics 367 frequecy_processed.push_back(current_word_frequency); 368 word_frequency_analyze(words_analysis_array, frequency_classify(current_word_frequency)); 369 } 370 else 371 { 372 // do nothing 373 } 374 } 375 else 376 { 377 //do nothing 378 } 379 } 380 cout << endl; 381 382 //classify this word and make statistics 383 //word_frequency_analyze(words_analysis_array, frequency_classify(current_word_frequency)); 384 content_read.clear(); 385 } 386 else 387 { 388 //do nothing 389 } 390 } 391 } 392 393 endTime = clock(); //process time stop 394 process_time = (double)(endTime - startTime) / CLOCKS_PER_SEC; 395 396 //calc whole words processed 397 int whole_words_analyzed = 0; 398 whole_words_analyzed = accumulate(words_analysis_array.begin(), words_analysis_array.end(), 0); 399 400 //report result 401 cout << "\n////////// Report ////////// \n"; 402 for (int i = 0;i< words_analysis_array.size();i++) 403 { 404 cout << report_str[i] <<"\t"<< words_analysis_array[i] << " ("; 405 cout<<fixed<<setprecision(2)<<(float)words_analysis_array[i] * 100 / whole_words_analyzed << "%)" << endl; 406 } 407 cout << "\nWords totally analyzed: " << whole_words_analyzed << endl; 408 409 //show run time 410 cout << "Map build time: " << build_map_time*1000 << "ms.\n"; 411 cout << "Process time: " << process_time*1000 << "ms.\n"; 412 cout << "////////////////////////////" << endl; 413 414 //close file 415 COCA_txt.close(); 416 USER_txt.close(); 417 418 return 0; 419 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号