
【NVSHMEM】NVSHMEM 3.0新增特性和兼容性
一、内容概要
使用NVSHMEM 3.0增强新平台上应用程序的可移植性和兼容性
NVSHMEM 3.0引入了多节点、多互联、主机设备ABI向后兼容和cpu辅助的ib GPU Direct Async (IBGDA)功能。
多节点、多互联:
以前只能 nvlink 在同一节点内 GPU 互联,3.0 支持不同节点上的 GPU 之间互联。
ABI向后兼容:
小版本号的变更,ABI 保持兼容。ABI 不兼容时,大的版本号会变化。相同小版本号的库,新的向后兼容旧的。
cpu辅助的ib GPU Direct Async :
在CPU 代理的 RDMA 通信 和 传统 GPU 发起的 RDMA 通信(IBGDA,CPU 只负责最初的资源创建) 之间又增加一种CPU-assisted InfiniBand GPU Direct Async .
二、详细内容
Enhancing Application Portability and Compatibility across New Platforms Using NVIDIA Magnum IO NVSHMEM 3.0
NVSHMEM is a parallel programming interface that provides efficient and scalable communication for NVIDIA GPU clusters. Part of NVIDIA Magnum IO and based on OpenSHMEM, NVSHMEM creates a global address space for data that spans the memory of multiple GPUs and can be accessed with fine-grained GPU-initiated operations, CPU-initiated operations, and operations on CUDA streams.
NVSHMEM是一个并行编程接口,为NVIDIA GPU集群提供高效和可扩展的通信。NVSHMEM是NVIDIA Magnum IO的一部分,基于OpenSHMEM, NVSHMEM为跨越多个gpu内存的数据创建了一个全局地址空间,可以通过细粒度的gpu发起的操作,cpu发起的操作和CUDA流上的操作来访问。
Existing communication models, such as the Message Passing Interface (MPI), orchestrate data transfers using the CPU. In contrast, NVSHMEM uses asynchronous, GPU-initiated data transfers, eliminating synchronization overheads between the CPU and the GPU.
现有的通信模型,如消息传递接口(Message Passing Interface, MPI),使用CPU编排数据传输。相反,NVSHMEM使用异步的、GPU发起的数据传输,消除了CPU和GPU之间的同步开销。
This post dives into the details of the NVSHMEM 3.0 release, including new features and support that we are enabling across platforms and systems.
这篇文章深入探讨了NVSHMEM 3.0版本的细节,包括我们正在跨平台和系统上启用的新功能和支持。
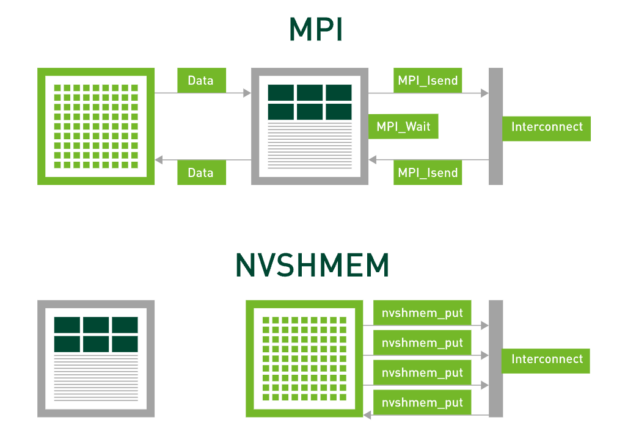
Figure 1. NVSHMEM and MPI comparison图1所示。NVSHMEM和MPI比较
New features and interface support in NVSHMEM 3.0
NVSHMEM 3.0中的新功能和接口支持
NVSHMEM 3.0 introduces multi-node, multi-interconnect support, host-device ABI backward compatibility, and CPU-assisted InfiniBand GPU Direct Async (IBGDA).
NVSHMEM 3.0引入了多节点、多互联、主机设备ABI向后兼容和cpu辅助的ib GPU Direct Async (IBGDA)功能。
Multi-node, multi-interconnect support
支持多节点、多互联
Previously, NVSHMEM has supported connectivity between multiple GPUs within a node over P2P interconnect (NVIDIA NVLink/PCIe) and multiple GPUs across a node over RDMA interconnects, such as InfiniBand, RDMA over Converged Ethernet (RoCE), Slingshot, and so on (Figure 2).
以前,NVSHMEM支持通过P2P互连(NVIDIA NVLink/PCIe)在节点内的多个gpu之间进行连接,以及通过RDMA互连(如InfiniBand、RDMA over Converged Ethernet (RoCE)、Slingshot等)在节点上的多个gpu之间进行连接(图2)。

Figure 2. A topology view of multiple nodes connected over RDMA networks图2。通过RDMA网络连接的多个节点的拓扑视图
NVSHMEM 2.11 added support for Multi-Node NVLink (MNNVL or NVIDIA GB200 NVL72) systems (Figure 3). However, this support was limited to when NVLink was the only inter-node interconnect.
NVSHMEM 2.11增加了对多节点NVLink (MNNVL或NVIDIA GB200 NVL72)系统的支持(图3)。然而,这种支持仅限于当NVLink是唯一的节点间互连时。
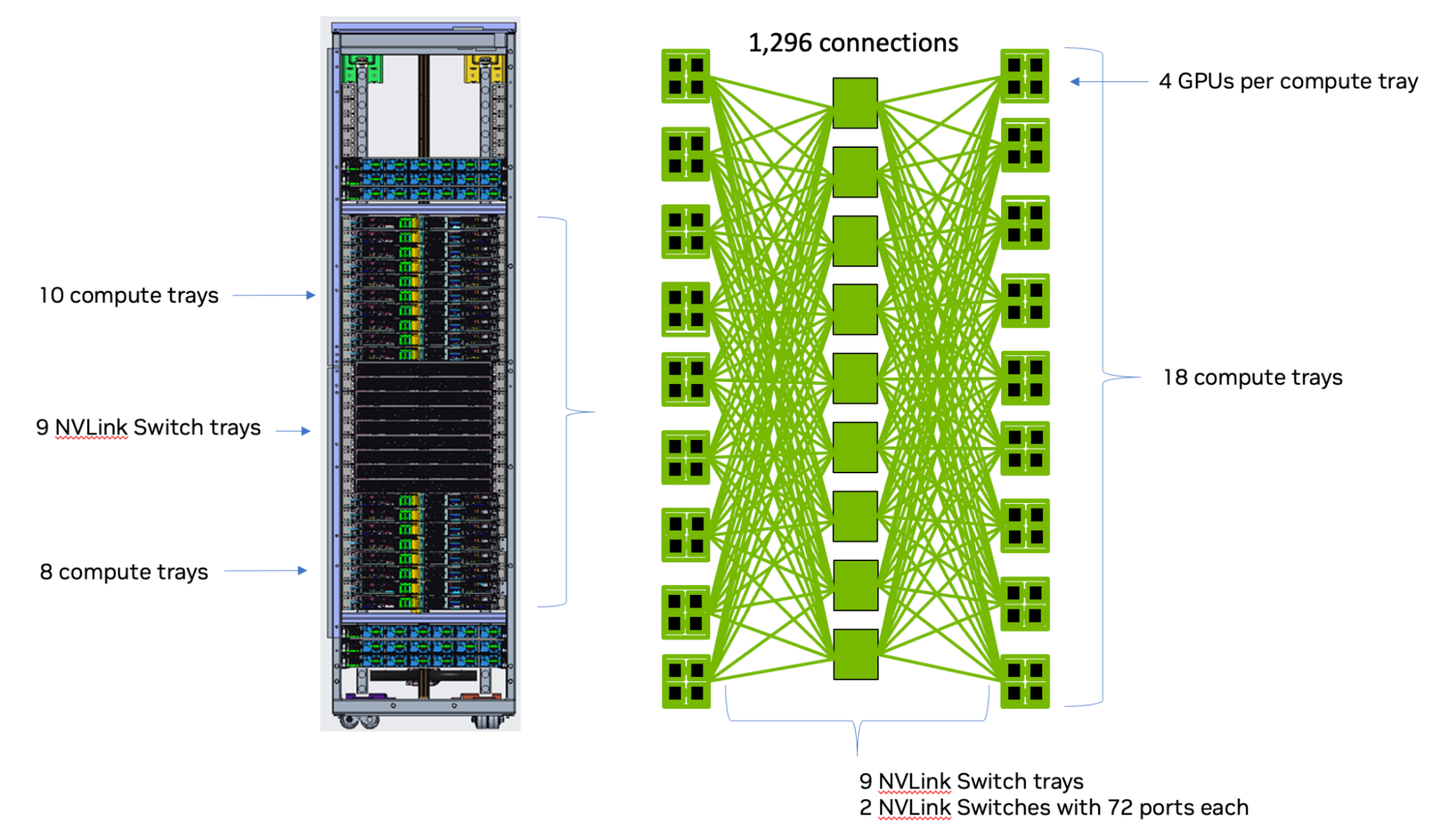
Figure 3. A topology view of a single NVIDIA GB200 NVL72 rack图3。
单个NVIDIA GB200 NVL72机架的拓扑视图
To address this limitation, new platform support was added to enable multiple racks of NVIDIA GB200 NVL72 systems connected to each other through RDMA networks (Figure 4). NVSHMEM 3.0 adds this platform support such that when two GPUs are part of the same NVLink fabric (for example, within the same NVIDIA GB200 NVL72 rack), NVLink will be used for communication.
为了解决这一限制,添加了新的平台支持,使多个NVIDIA GB200 NVL72系统机架能够通过RDMA网络相互连接(图4)。NVSHMEM 3.0增加了这种平台支持,当两个gpu是同一个NVLink结构的一部分时(例如,在同一个NVIDIA GB200 NVL72机架内),NVLink将用于通信。
In addition, when the GPUs are spread across NVLink fabrics (for example, across NVIDIA GB200 NVL72 racks), the remote network will be used for communication between those GPUs. This release also enhances the NVSHMEM_TEAM_SHARED capabilities to contain all GPUs that are part of the same NVLink clique that spans one or more nodes.
此外,当gpu分布在NVLink结构上时(例如,跨NVIDIA GB200 NVL72机架),远程网络将用于这些gpu之间的通信。此版本还增强了 NVSHMEM_TEAM_SHARED 功能,以包含跨越一个或多个节点的同一NVLink集团的所有gpu。
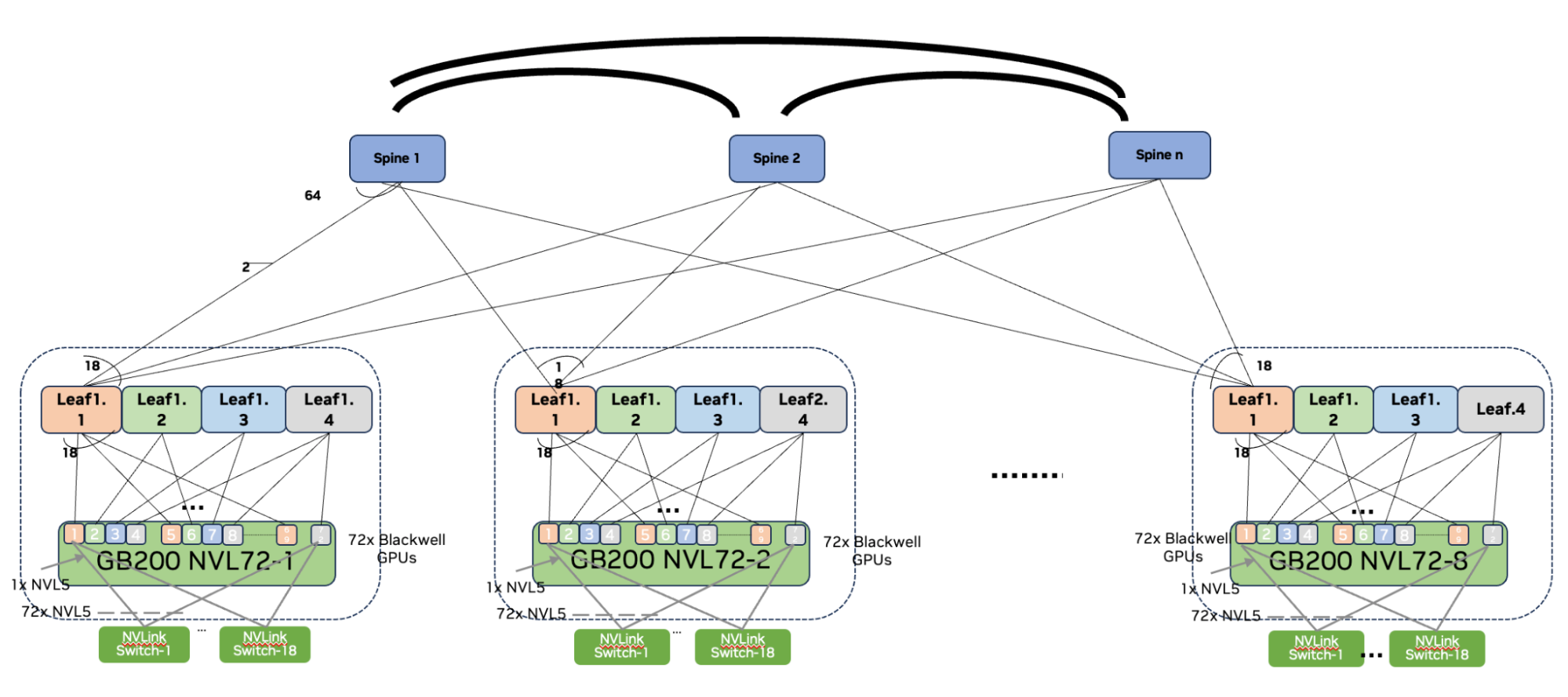
Figure 4. A topology view of multiple NVIDIA GB200 NVL72 racks connected over RDMA networks图4。通过RDMA网络连接的多个NVIDIA GB200 NVL72机架的拓扑视图
Host-device ABI backward compatibility
主机设备ABI向后兼容性
Historically, NVSHMEM has not supported backwards compatibility for applications or independently compiled bootstrap plug-ins. NVSHMEM 3.0 introduces backwards compatibility across NVSHMEM minor versions. An ABI breakage will be denoted by a change in the major version of NVSHMEM.
从历史上看,NVSHMEM不支持应用程序或独立编译的引导插件的向后兼容性。NVSHMEM 3.0引入了跨NVSHMEM小版本的向后兼容性。每当 NVSHMEM 的主版本号发生变化时,表示 ABI(应用二进制接口)发生了不兼容的变更。
This feature enables the following use cases for libraries or applications consuming ABI compatible versions of NVSHMEM:
对于采用ABI兼容版本NVSHMEM的库和应用程序,本特性支持以下使用场景:
- Libraries linked to a minor version 3.X of NVSHMEM can be installed on a system with a newer installed version 3.Y of NVSHMEM (Y > X).
依赖 3.X小版本号NVSHMEM 的(其他) 库,可安装在 部署了更新版本3.Y(Y>X)的NVSHMEM 的系统中正常运行.
- Multiple libraries shipped together in an SDK, which link to different minor versions of NVSHMEM, will be supported by a single newer version of NVSHMEM.
同一SDK中集成的不同的库分别依赖不同小版本的 NVSHMEM,可通过单一新版NVSHMEM实现兼容(统一)支持.
- A CUDA binary (also referred to as cubin) statically linked to an older version of the NVSHMEM device library can be loaded by a library using a newer version of NVSHMEM.
● 静态链接旧版NVSHMEM 的 device 库的CUDA二进制文件(cubin),可由基于新版NVSHMEM的库直接加载执行
| NVSHMEM Host Library 2.12NVSHMEM主机库2.12 | NVSHMEM Host Library 3.0NVSHMEM主机库3.0 | NVSHMEM Host Library 3.1 NVSHMEM主机库3.1 | NVSHMEM Host Library 3.2 NVSHMEM主机库3.2 | NVSHMEM Host Library 4.0 NVSHMEM主机库4.0 | |
| Application linked to NVSHMEM 3.1应用程序链接到NVSHMEM 3.1 | No 否 | No 否 | Yes 是 | Yes 是 | No 否 |
| Cubin linked to NVSHMEM 3.0链接到NVSHMEM 3.0的库宾 | No 否 | Yes 是 | Yes 是 | Yes 是 | No 否 |
| Multiple Libraries 多个库 | No 否 | No 否 | No 否 | Yes 是 | No 否 |
Table 1. Compatibility for NVSHMEM 3.0 and future versions表1。NVSHMEM 3.0和未来版本的兼容性
CPU-assisted InfiniBand GPU Direct Async
cpu辅助InfiniBand GPU Direct Async
In previous releases, NVSHMEM supported traditional InfiniBand GPU Direct Async (IBGDA), where the GPU directly drives the IB NIC, enabling massively parallel control plane operations. It is responsible for managing the Network Interface Card (NIC) control plane, such as ringing the doorbell when a new work request is published to the NIC.
在以前的版本中,NVSHMEM支持传统的InfiniBand GPU Direct Async (IBGDA), GPU直接驱动IB网卡,实现大规模并行控制平面操作。它负责管理网卡(Network Interface Card)的控制平面,例如在向网卡发布新的工作请求时按门铃。
NVSHMEM 3.0 adds support for a new modality in IBGDA called CPU-assisted IBGDA, which acts as an intermediate mode between proxy-based networking and traditional IBGDA. It splits responsibilities of the control plane between the GPU and CPU. The GPU generates work requests (control plane operations) and the CPU manages NIC doorbell-ringing requests for submitted work requests. It also enables dynamic selections of the NIC assistant to be CPU or GPU at runtime.
NVSHMEM 3.0在IBGDA中增加了对一种称为cpu辅助IBGDA的新模式的支持,它作为基于代理的网络和传统IBGDA之间的中间模式。它将控制平面的职责划分给GPU和CPU,GPU生成工作请求(控制平面操作),CPU管理提交工作请求后的网卡摇门铃请求。它还允许NIC助手在运行时动态选择CPU或GPU。
CPU-assisted IBGDA relaxes existing administrative-level configuration constraints in IBGDA peer mapping, thereby helping to improve IBGDA adoption on non-coherent platforms where administrative level configuration constraints are harder to enforce in large-scale cluster deployments.
cpu辅助的IBGDA放宽了IBGDA 对等映射(peer mapping)中 现有的管理级配置约束(administrative-level configuration constraints),从而有助于提高IBGDA在非一致平台上的采用,在这种平台上,在大规模集群部署中难以实施管理级配置约束。
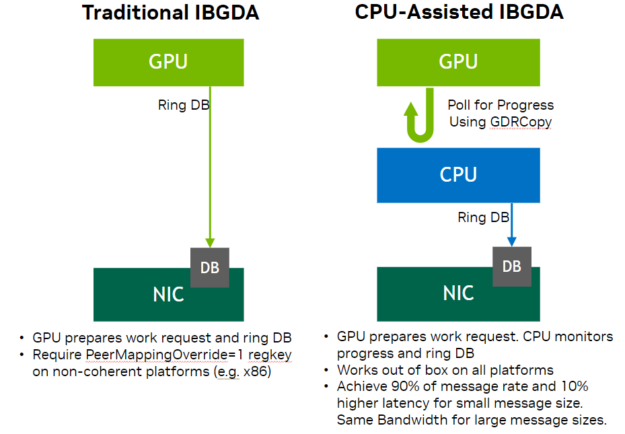
Figure 5. Comparison between traditional and CPU-assisted IBGDA图5。传统与cpu辅助IBGDA的比较
Non-interface support and minor enhancements
非接口支持和小的增强
NVSHMEM 3.0 also introduces minor enhancements and non-interface support, as detailed in this section.
NVSHMEM 3.0还引入了一些小的增强和非接口支持,如本节所述。
Object-oriented programming framework for symmetric
heap面向对象的对称堆编程框架
Historically, NVSHMEM has supported multiple symmetric heap kinds using a procedural programming model. This has limitations, such as a lack of namespace-based data encapsulation and code duplication and data redundancy.
从历史上看,NVSHMEM使用‘过程编程模型’支持多种对称堆类型。(不过) 这是有局限性的,比如缺乏基于名称空间的数据封装、代码复制和数据冗余。
NVSHMEM 3.0 introduces support for an object-oriented programming (OOP) framework that can manage different kinds of symmetric heaps such as static device memory and dynamic device memory using multi-level inheritance. This will enable easier extension to advanced features like on-demand registration of application buffers to symmetric heap in future releases.
NVSHMEM 3.0引入了对面向对象编程(OOP)框架的支持,该框架可以使用多级继承管理不同类型的对称堆,例如静态设备内存和动态设备内存。这将使在未来的版本中更容易扩展高级功能,如按需注册应用程序缓冲区到对称堆。
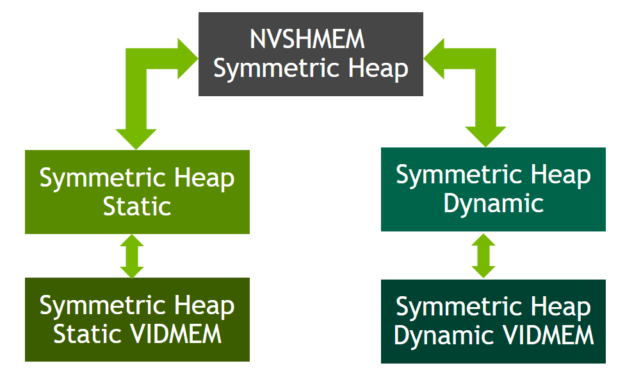
Figure 6. NVSHMEM 3.0 object-oriented hierarchy图6。NVSHMEM 3.0面向对象层次结构
Performance improvements and bug fixes
性能改进和bug修复
NVSHMEM 3.0 introduces various performance improvements and bug fixes for different components and scenarios. These include IBGDA setup, block scoped on-device reductions, system scoped atomic memory operation (AMO), IB Queue Pair (QP) mapping, memory registration, team management, and PTX build testing.
NVSHMEM 3.0为不同的组件和场景引入了各种性能改进和bug修复。其中包括IBGDA设置、块作用域设备上缩减、系统作用域原子内存操作(AMO)、IB队列对(QP)映射、内存注册、团队管理和PTX构建测试。
Summary
The 3.0 release of the NVIDIA NVSHMEM parallel programming interface introduces several new features, including multi-node multi-interconnect support, host-device ABI backward compatibility, CPU-assisted InfiniBand GPU Direct Async (IBGDA), and object-oriented programming framework for symmetric heap.
NVIDIA NVSHMEM并行编程接口3.0版本引入了几个新特性,包括多节点多互连支持、主机设备ABI向后兼容性、cpu辅助InfiniBand GPU直接异步(IBGDA)和面向对象的对称堆编程框架。
With host-device ABI backward compatibility, administrators can update to a new version of NVSHMEM without breaking already compiled applications, eliminating the need to modify the application source with each update.
由于主机-设备ABI向后兼容,管理员可以在不破坏已编译的应用程序的情况下更新到新版本的NVSHMEM,从而无需在每次更新时修改应用程序源代码。
CPU-assisted InfiniBand GPU Direct Async (IBGDA) enables users to benefit from the high message rate of the IBGDA transport on clusters where enforcing administrative level driver settings is not possible.
CPU 辅助的 InfiniBand GPU Direct Async(IBGDA)可以让用户在无法进行管理员级别驱动设置的集群环境下,也能利用 IBGDA 通信方式带来的高消息速率优势。
To learn more and get started, see the following resources:
要了解更多并开始,请参阅以下参考资料:
- IBGDA: Improving Network Performance of HPC Systems Using NVIDIA Magnum IO NVSHMEM and GPUDirect AsyncIBGDA:使用NVIDIA Magnum IO NVSHMEM和GPUDirect Async提高HPC系统的网络性能
- Scaling Scientific Computing with NVSHMEM用NVSHMEM扩展科学计算
- Accelerating NVSHMEM 2.0 Team-Based Collectives Using NCCL利用NCCL加速NVSHMEM 2.0团队集体
- NVSHMEM DocumentationNVSHMEM文档
- NVSHMEM Best Practices GuideNVSHMEM最佳实践指南
- NVSHMEM API DocumentationNVSHMEM API文档
- OpenSHMEM
- NVSHMEM Developer ForumNVSHMEM开发者论坛
Related resources 相关资源
- GTC session: Advanced Multi-GPU Scaling: Communication LibrariesGTC会议:高级多gpu扩展:通信库
- GTC session: Protein AI applications Using BioNemo for Agricultural Biotech TraitsGTC会议:利用BioNemo进行农业生物技术性状的蛋白质人工智能应用
- NGC Containers: NVIDIA Magnum IO Developer EnvironmentNGC容器:NVIDIA Magnum IO开发环境
- SDK: NVTX
- SDK: NVAPI
- SDK: GPUDirect Storage


 浙公网安备 33010602011771号
浙公网安备 33010602011771号