
【CUDA】warp洗牌shuffle:_shfl_sync、__shfl_up_sync、__shfl_down_sync 和 __shfl_xor_sync函数
由计算能力 3.x 或更高版本的设备支持。
弃用通知:__shfl、__shfl_up、__shfl_down 和 __shfl_xor 在 CUDA 9.0 中已针对所有设备弃用。
删除通知:当面向具有 7.x 或更高计算能力的设备时,__shfl、__shfl_up、__shfl_down 和 __shfl_xor 不再可用,而应使用它们的同步变体
warp级别洗牌(shuffle)函数,这些函数允许同一个warp内的线程直接交换数据,而无需通过共享内存,从而减少延迟并提高效率。这些函数都是同步的,要求warp内所有线程都参与(通过掩码指定参与线程),因此函数名中带有`_sync`。
函数原型
函数原型(以整数类型为例,也有浮点版本):
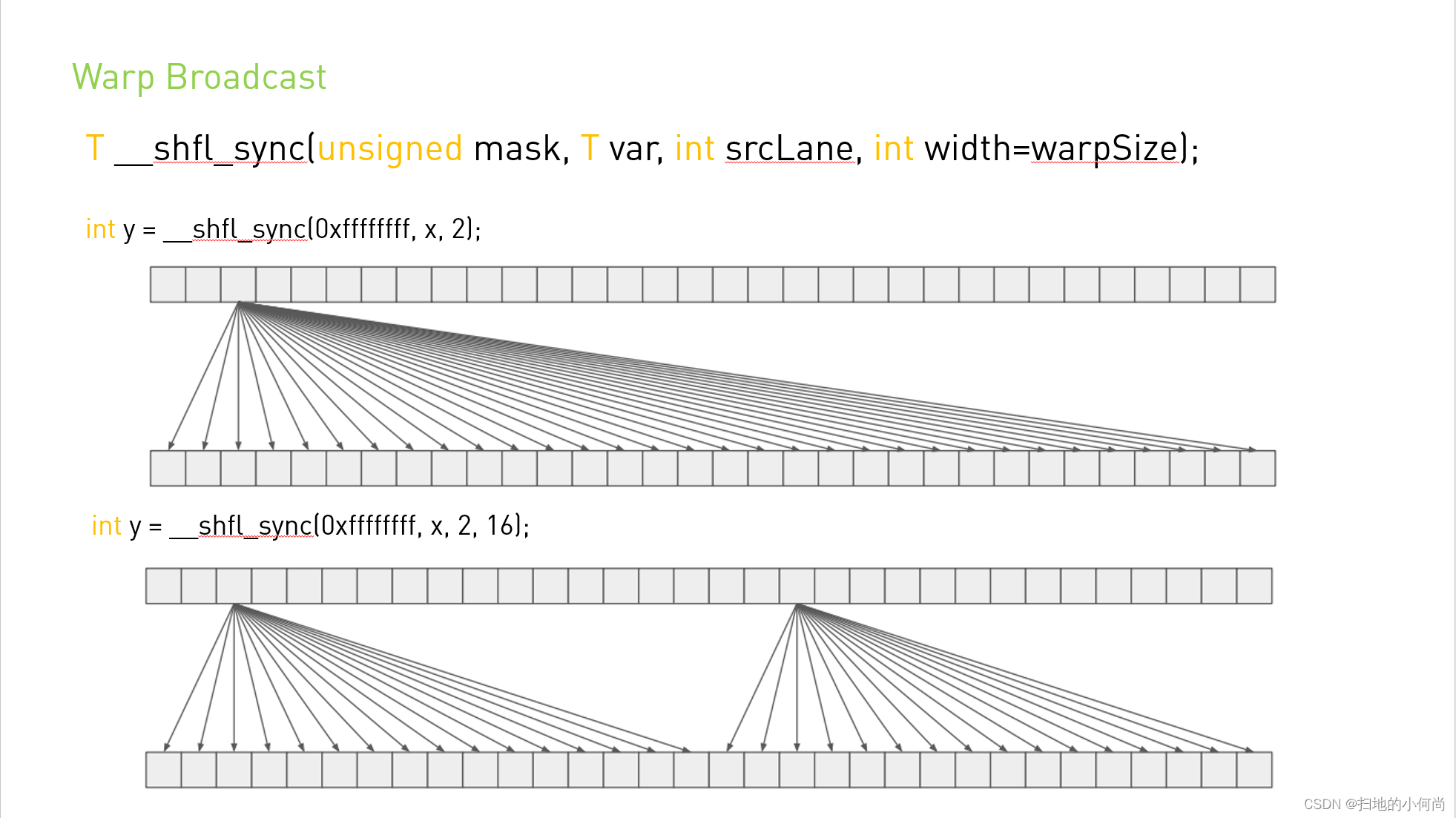
T __shfl_sync(unsigned mask, T var, int srcLane, int width=warpSize);
T __shfl_up_sync(unsigned mask, T var, unsigned int delta, int width=warpSize);
T __shfl_down_sync(unsigned mask, T var, unsigned int delta, int width=warpSize);
T __shfl_xor_sync(unsigned mask, T var, int laneMask, int width=warpSize);
参数说明:
mask: 一个32位掩码,每个位代表warp中的一个线程(从0开始编号)。只有掩码中设置为1的对应线程才会参与操作。通常使用全1掩码(0xffffffff)表示整个warp参与。
var: 要交换的变量。
srcLane: 指定从哪个线程读取数据。分组内的相对索引(0 ~ width-1)。 (__shfl_sync)
delta: 向上或向下移动的偏移量。 (__shfl_up_sync 和 __shfl_down_sync)
laneMask : 用于按位异或的掩码,与当前线程ID异或后得到目标线程ID。(__shfl_xor_sync)
返回值:
目标线程的var值。非mask指定的线程返回值未定义
注意:width参数(可选)允许将warp划分为更小的组(必须是2的幂,且小于等于warpSize)。例如,width=16则将warp分成两个16线程的组,洗牌操作只在组内进行。
函数说明
下面分别说明:
1. __shfl_sync: 从指定线程复制数据
T __shfl_sync(unsigned mask, T var, int srcLane, int width=32);
所有参与线程(mask 覆盖的) 从srcLane线程中获取变量var的值。
例如:假设warp大小为4,mask 0xf 覆盖了全部线程0,1,2,3。如果线程 n(0~3) 调用 __shfl_sync(0xf, x, 2),那么线程n将得到线程2的x值。
(如果mask = 0x01,那么只覆盖线程 0,那么 0~3 线程调用 __shfl_sync(0xf, x, 2),只有线程 0 将得到线程2的x值。)
示例:线程1获取线程0的val值
__global__ void kernel() {
int val = threadIdx.x; // 每个线程的ID即其值
int target = __shfl_sync(0xFFFFFFFF, val, 0); // 所有线程都读取线程0的值
printf("Thread %d: target=%d\n", threadIdx.x, target);
}
/* 输出:
Thread 0: target=0
Thread 1: target=0
... (所有线程输出0) */下图: mask=0xffffffff 覆盖所有线程,srcLane=2,所以所有线程参与从 ID=2 的线程获取数据:
(图片来源:CUDA中的Warp Shuffle-CSDN博客)
2. __shfl_up_sync: 向上<序号往前> 找线程获取数据
T __shfl_up_sync(unsigned mask, T var, unsigned int delta, int width=32);
所有参与的线程(tids=n) 从线程(tidt=n -delta)中获取数据。如果(tidt=n -delta < 0),则当前线程保持不变(返回自己的var)。
例如:warp大小为4,线程0,1,2,3。如果线程2调用 __shfl_up_sync(0xf, x, 1),则线程2将获取线程1(2-1)的x值。线程0调用时,0-1=-1,所以返回自己的x。
示例:每个线程从相对本身靠前2个位置的线程获取值
__global__ void kernel() {
int val = threadIdx.x;
int result = __shfl_up_sync(0xFFFFFFFF, val, 2);
printf("Thread %d: result=%d\n", threadIdx.x, result);
}
/* 输出:
Thread 0: result=0 // 0-2<0 返回自身
Thread 1: result=1 // 1-2<0 返回自身
Thread 2: result=0 // 2-2=0
Thread 3: result=1 // 3-2=1
... */下图: mask=0xffffffff 覆盖所有线程,delta=2,所以所有线程参与,从ID=本身 ID -delta 的线程获取数据,前 2 个因为 ID -delta<0,所以返回的是自身的数据:

(图片来源:CUDA中的Warp Shuffle-CSDN博客)
3. __shfl_down_sync: 向 下<序号往后> 找线程获取数据
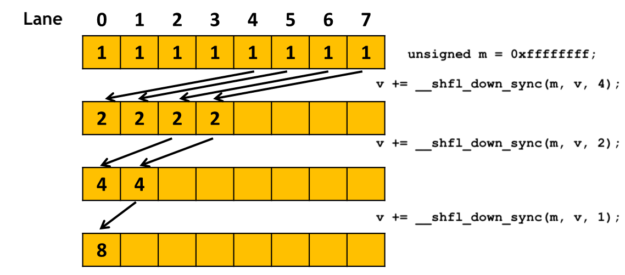
T __shfl_down_sync(unsigned mask, T var, unsigned int delta, int width=32);
当前线程(tids=n) 从线程(tidt=n +delta)中获取数据。如果(tidt=n +delta 超过width-1(或warpSize-1)),则当前线程保持不变(返回自己的var)。
例如:warp大小为4,线程0,1,2,3。线程1调用 __shfl_down_sync(0xf, x, 2) 将获取线程3(1+2)的x。线程3调用时,3+2=5,超过3,所以返回自己的x。
示例:每个线程从相对本身靠后2个位置的线程获取值
__global__ void kernel() {
int val = threadIdx.x;
int result = __shfl_down_sync(0xFFFFFFFF, val, 2);
printf("Thread %d: result=%d\n", threadIdx.x, result);
}
/* 输出:
Thread 0: result=2 // 0+2=2
Thread 1: result=3 // 1+2=3
Thread 30: result=30 // 30+2=32≥32 返回自身
Thread 31: result=31 */下图: mask=0xffffffff 覆盖所有线程,delta=3,所以所有线程参与,从ID=本身 ID +3 的线程获取数据,后 3 个因为 ID +delta> width-1,所以返回的是自身的数据。

(图片来源:CUDA中的Warp Shuffle-CSDN博客)
4. __shfl_xor_sync: 按线程ID的异或操作交换数据
T __shfl_xor_sync(unsigned mask, T var, int laneMask, int width=32);
所有参与的线程(tids=n),各自从 tidt=(tids XOR laneMask)的线程取值
例如:warp大小为4(线程0,1,2,3),laneMask=1。则:
线程0:0^1=1 -> 从线程1获取
线程1:1^1=0 -> 从线程0获取
线程2:2^1=3 -> 从线程3获取
线程3:3^1=2 -> 从线程2获取
这实际上实现了两两交换(0<->1, 2<->3)。如果laneMask=3,则:
线程0:0^3=3 -> 从线程3获取
线程1:1^3=2 -> 从线程2获取
线程2:2^3=1 -> 从线程1获取
线程3:3^3=0 -> 从线程0获取
这实现了4个线程的循环交换(0->3, 3->0; 1->2, 2->1),也就是相邻两个线程对交换。
注意:这些函数要求warp内所有活动线程(由mask指定)必须执行相同的洗牌操作,否则结果未定义。
下面给出一个简单的代码示例(概念性代码,实际使用时需注意线程同步和掩码设置):
示例:相邻线程交换数据(laneMask=1)
__global__ void kernel() {
int val = threadIdx.x;
int result = __shfl_xor_sync(0xFFFFFFFF, val, 1);
printf("Thread %d: result=%d\n", threadIdx.x, result);
}
/* 输出:
Thread 0: result=1 // 0^1=1
Thread 1: result=0 // 1^1=0
Thread 2: result=3 // 2^1=3
Thread 3: result=2 // 3^1=2
... */下图:
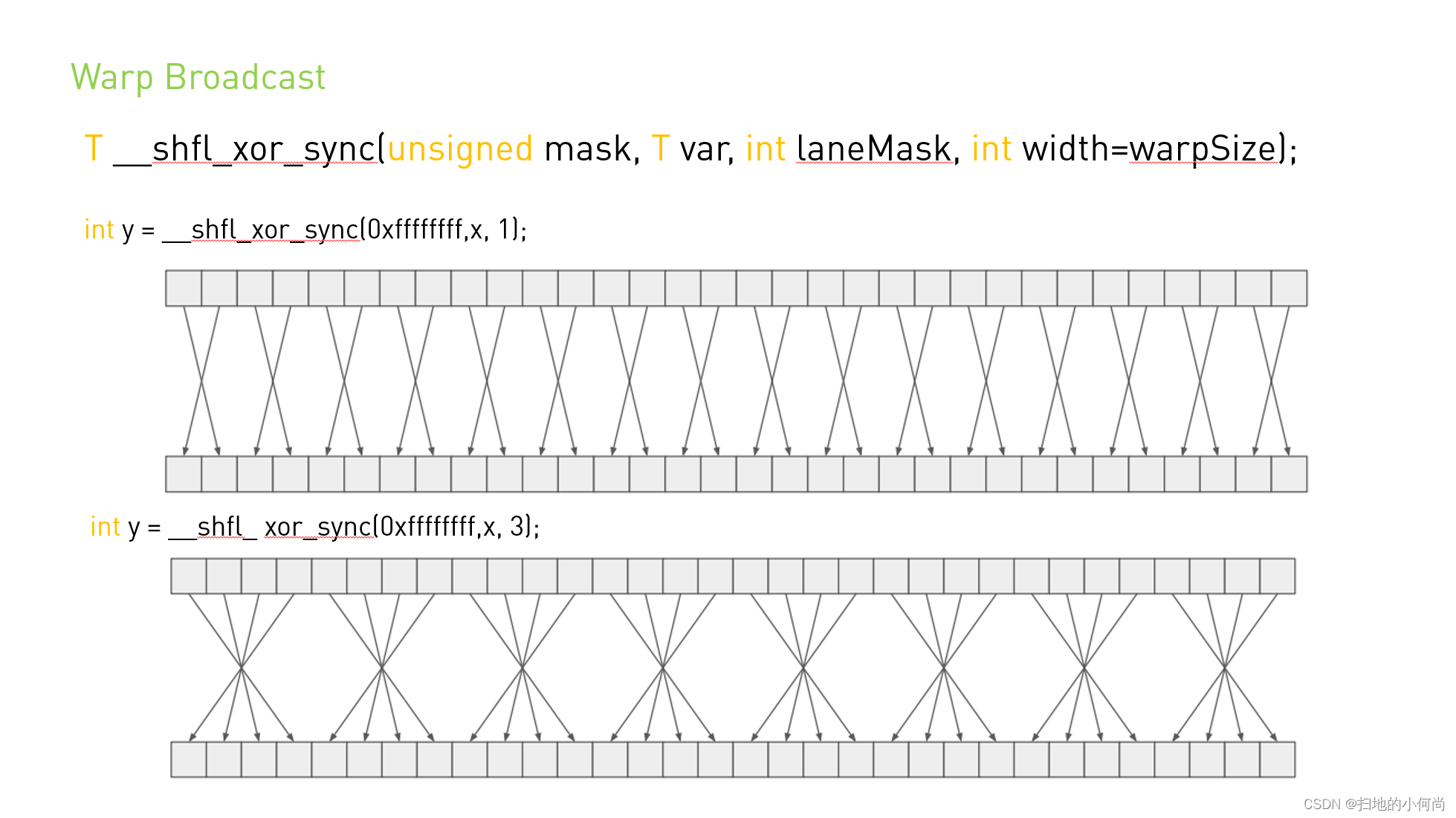
(图片来源:CUDA中的Warp Shuffle-CSDN博客)
注意事项
- warp内所有线程必须执行相同的洗牌指令
- 不同lane的var值可以不同实用场景总结
## 使用场景
- 广播数据
- 数据偏移
- 交错访问-
- 广播:
__shfl_sync(0xFFFFFFFF, data, 0) - 前缀和:
__shfl_up_sync+ 累加 - 规约:
__shfl_xor_sync树形求和
- 广播:
// 获取相邻线程的值
int left = __shfl_up_sync(mask, var, 1);
int right = __shfl_down_sync(mask, var, 1);1. 掩码生成
// 动态生成全warp掩码
unsigned mask = __activemask();
// 常用掩码模式
constexpr unsigned FULL_MASK = 0xffffffff;2. 浮点精度处理
// 直接支持float交换
float result = __shfl_sync(FULL_MASK, input, srcLane);
// double需要计算能力≥6.0
double dbl_result = __shfl_sync(FULL_MASK, dbl_var, srcLane);3. 高效规约示例(warp内求和)
__device__ float warp_reduce_sum(float val) {
for (int offset = 16; offset > 0; offset /= 2)
val += __shfl_down_sync(FULL_MASK, val, offset);
return val; // 线程0持有总和
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号