
【RDMA】GDR和GDA的区别(GPUDirect Async vs GPU Direct RDMA)
简述
- GDR(GPU Direct RDMA)直达网卡,解决了 “数据路径” 问题:让 RDMA 设备直接访问 GPU 内存,无需主机内存中转;
- GDA GPUDirect Async 直达异步(操控),解决了 “控制路径” 问题:让 GPU 自主管理通信流程,无需 CPU 参与控制。
介绍
GDA 通常是指 NVIDIA 的 GPUDirect Async 技术,它与 GDR(GPU Direct RDMA)都属于 NVIDIA GPUDirect 技术家族的成员。
简单说明
GDR(GPU Direct RDMA) :
允许 GPU 直接访问内存缓冲区,通常来自主机或其他设备,而无需 CPU 参与。该技术主要用于基于 RDMA 的通信,让 GPU 可以直接向网络接口卡(NIC)或另一个 GPU 发送 / 接收数据,绕过 CPU 以减少开销,常用于高性能计算(HPC)等场景。
GDA(GPUDirect Async) :
主要用于在 GPU 加速应用程序中卸载通信控制逻辑。它可以让 GPU 和 HCA(主机通道适配器)之间直接对话,在 GPU 设备内存上分配 InfiniBand 结构,并通过对等 DMA API 和修改后的 HCA 初始化例程将它们公开给 HCA,进一步优化数据传输过程中的控制和管理,降低延迟。
在没有 GDA 的情况下,即使有 GDR(GPU Direct RDMA)支持 GPU 与 RDMA 设备的直接内存访问,通信控制逻辑仍需 CPU 参与。具体流程大致如下:
1. GPU 将数据写入自身内存(无需先拷贝到主机内存,这是 GDR 已解决的问题);
2. CPU 需要介入并执行一系列操作:将 GPU 内存地址信息写入 RDMA 设备的发送队列(SQ),配置 DMA 传输参数,最后触发网卡开始传输;
3. 传输完成后,CPU 还需处理中断或轮询完成队列(CQ),再通知 GPU 传输结果。
而 GDA 的核心作用是将这些控制逻辑从 CPU 卸载到 GPU:允许 GPU 直接操作 RDMA 设备的队列(如 SQ/CQ),自主发起和管理数据传输,无需 CPU 介入配置或触发。这进一步减少了通信延迟(避免 CPU 上下文切换和调度开销),并让 GPU 计算与数据传输能更紧密地重叠执行。
总得来说就是:
- GDR 解决了 “数据路径” 问题:让 RDMA 设备直接访问 GPU 内存,无需主机内存中转;
- GDA 解决了 “控制路径” 问题:让 GPU 自主管理通信流程,无需 CPU 参与控制。
举例说明
举例说明,如下图是在没有 GDA 技术之前, GPU 之间借助 GDR 进行 RDMA 通信的过程
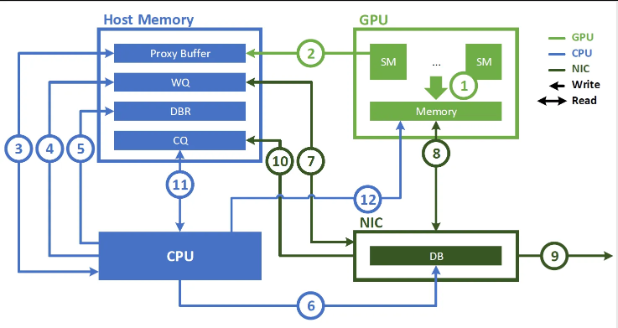
流程拆解(按序号顺序)
- GPU 准备数据
GPU 的流多处理器(SM)将数据写入 GPU 内存,这是待通过网卡发送的 “源数据” (无需拷贝到主机内存,这是 GDR 的核心价值)。 - 数据拷贝到主机代理缓冲区
由于没有 GDA,GPU 无法直接操作网卡的队列,因此需要将通信控制所需的元数据(如数据位置、传输指令等) 写入主机内存的 Proxy Buffer(代理缓冲区 ),因无 GDA,需借主机内存中转通信控制,这一步是为后续 CPU 操作做数据准备。 - CPU 写工作队列(WQ)
CPU 从 Proxy Buffer 读取这些元数据, 向主机内存的 WQ(Work Queue,工作队列 )写入通信任务描述,告知网卡 “要发什么数据、怎么发” ,是发起通信的控制指令前置操作。 - CPU 写数据块记录(DBR)
CPU 向 DBR(Data Block Record,数据块记录 )写入数据块相关元信息(如数据地址、长度 ),辅助网卡识别和处理要传输的数据。 - CPU 写完成队列(CQ)占位
CPU 往 CQ(Completion Queue,完成队列 )预先写入占位信息,用于后续接收网卡传输完成的反馈,让系统能感知通信状态。 - CPU 触发网卡 DMA
CPU 向 NIC(网卡 )发送指令,触发 DMA(直接内存访问 )传输,让网卡开始从主机内存读取数据,正式启动数据外发流程。 - 网卡读 WQ/DBR
NIC 从主机内存的 WQ 读取工作任务,从 DBR 读取数据元信息,明确传输任务细节,为抓取数据做准备。 - 网卡读 GPU 数据(GDR 核心)
借助 GDR 技术,NIC 跳过主机内存中转,直接从 GPU 内存读取数据(也可能结合步骤 2 已拷贝到 Proxy Buffer 的数据,具体看场景 ),减少数据搬运开销。 - 网卡发送数据
NIC 将读取到的数据通过网络发往目标端,完成实际的数据输出。 - 网卡写 CQ 完成通知
传输完成后,NIC 向主机内存的 CQ 写入完成状态,告知系统通信已结束。 - CPU 轮询 / 处理 CQ
CPU 检查 CQ 中的完成通知,确认传输结果(成功 / 失败 ),并做后续清理、状态更新等操作。 - (可选)网卡写回 GPU 反馈
若有需要,NIC 会把传输状态等反馈写回 GPU 内存,让 GPU 知晓通信结果,不过这一步并非必需,依场景而定。
无 GDA 时的核心问题
整个流程里,CPU 全程深度参与控制:从初始化任务队列、配置元数据,到触发传输、轮询结果,每一步都离不开 CPU 干预。这会带来两个关键弊端:
- 延迟高:CPU 上下文切换、队列操作都耗时,拖慢整体通信速度;
- CPU 资源占用:CPU 被通信控制绑定,没法干其他计算任务,尤其在高频、大规模通信场景,会成为性能瓶颈。
GDA(GPUDirect Async)的价值
GDA(GPUDirect Async)的价值,就是把 “CPU 代理控制” 的逻辑 卸载到 GPU ,让 GPU 能直接操作 NIC 的队列(WQ/CQ 等 )、自主发起 / 管理传输,砍掉 CPU 参与的控制流程,
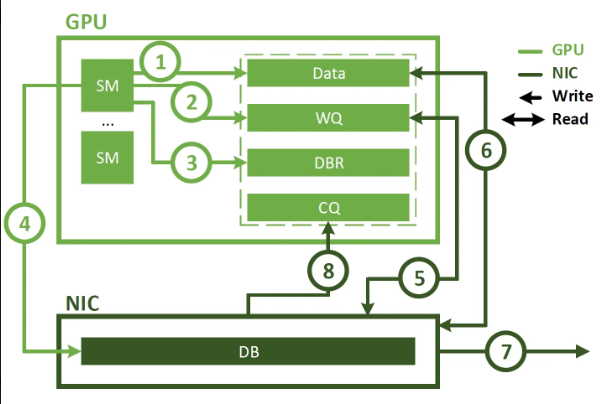
图中展现了 GDA(GPUDirect Async)模式下,GPU 自主管理网卡通信 的流程,核心是把原本 CPU 承担的 “控制流” 完全卸载到 GPU,实现更高效的端到端通信。
流程拆解(按序号顺序)
1. GPU 准备数据GPU 的流多处理器(SM)将待发送的数据写入 GPU 内存的 Data 区域,完成数据准备。
2. GPU 写工作队列(WQ)GPU 直接向自身内存中的 WQ(Work Queue,工作队列 )写入通信任务描述(比如 “要发送的数据地址、长度、目标地址” 等控制信息 ),无需 CPU 参与 配置任务。
3. GPU 写数据块记录(DBR)GPU 向自身内存的 DBR(Data Block Record,数据块记录 )写入数据元信息(辅助网卡识别数据 ),同样由 GPU 自主完成,跳过 CPU 干预。
4. GPU 触发网卡 DMAGPU 直接向 NIC(网卡 )发送指令,触发 DMA(直接内存访问 )传输。这一步是 GDA 的核心 —— GPU 自主发起通信,不再依赖 CPU 发命令。
5. 网卡读 WQ/DBRNIC 从 GPU 内存读取 WQ 的任务指令和 DBR 的元数据,明确 “要传输什么数据、怎么传”,直接与 GPU 内存交互。
6. 网卡读 GPU 数据借助 GDR(GPU Direct RDMA )能力,NIC 直接从 GPU 内存的 Data 区域读取待发送的数据,跳过主机内存中转,减少数据搬运耗时。
7. 网卡发送数据NIC 将读取到的数据通过网络发往目标端,完成实际的数据输出。
8. 网卡写 CQ 完成通知传输完成后,NIC 直接向 GPU 内存的 CQ(Completion Queue,完成队列 )写入 “传输完成” 的状态通知,让 GPU 自主感知结果。
GDA 带来的核心变化
对比之前无 GDA 的流程,这张图最关键的差异是 “控制流完全由 GPU 主导”:
• 原本 CPU 负责的 “写 WQ/DBR、触发传输、轮询 CQ” 等操作,全部交给 GPU 自主完成;
• 数据路径(GDR 实现的 GPU - NIC 直接访问 )+ 控制路径(GDA 实现的 GPU 自主控制 )彻底打通,形成 端到端的 GPU 直连网卡通信。
价值总结
GDA 让 GPU 真正实现了 “数据发送 + 通信控制” 全自主,带来两大关键优势:
1. 延迟更低:砍掉 CPU 参与的控制流程,减少上下文切换、队列等待的耗时;
2. CPU 彻底解放:CPU 不再被通信控制绑定,能专注跑其他计算任务,提升系统整体效率。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号