

【NCCL】什么是PXN
将 NVLink 与网络通信相结合
PXN 使得GPU能够通过NVLink及后续的PCIe路径与目标节点的网卡进行通信,取代了传统上需要经由QPI或其他CPU间协议传输的方案——后者往往无法提供完整的带宽性能。这种设计确保每个GPU在尽可能使用本地网卡的同时,在需要时也能访问其他网卡资源。
具体实现中,GPU不再在本地显存中为本地网卡准备发送缓冲区,而是通过NVLink将数据写入中间GPU的缓冲区,随后向管理目标网卡的CPU代理(而非本地CPU代理)发送数据就绪通知。虽然GPU-CPU间的同步操作可能因需要跨CPU插槽而稍慢,但数据传输本身仅通过NVLink和PCIe交换机完成,从而确保了最大传输带宽。
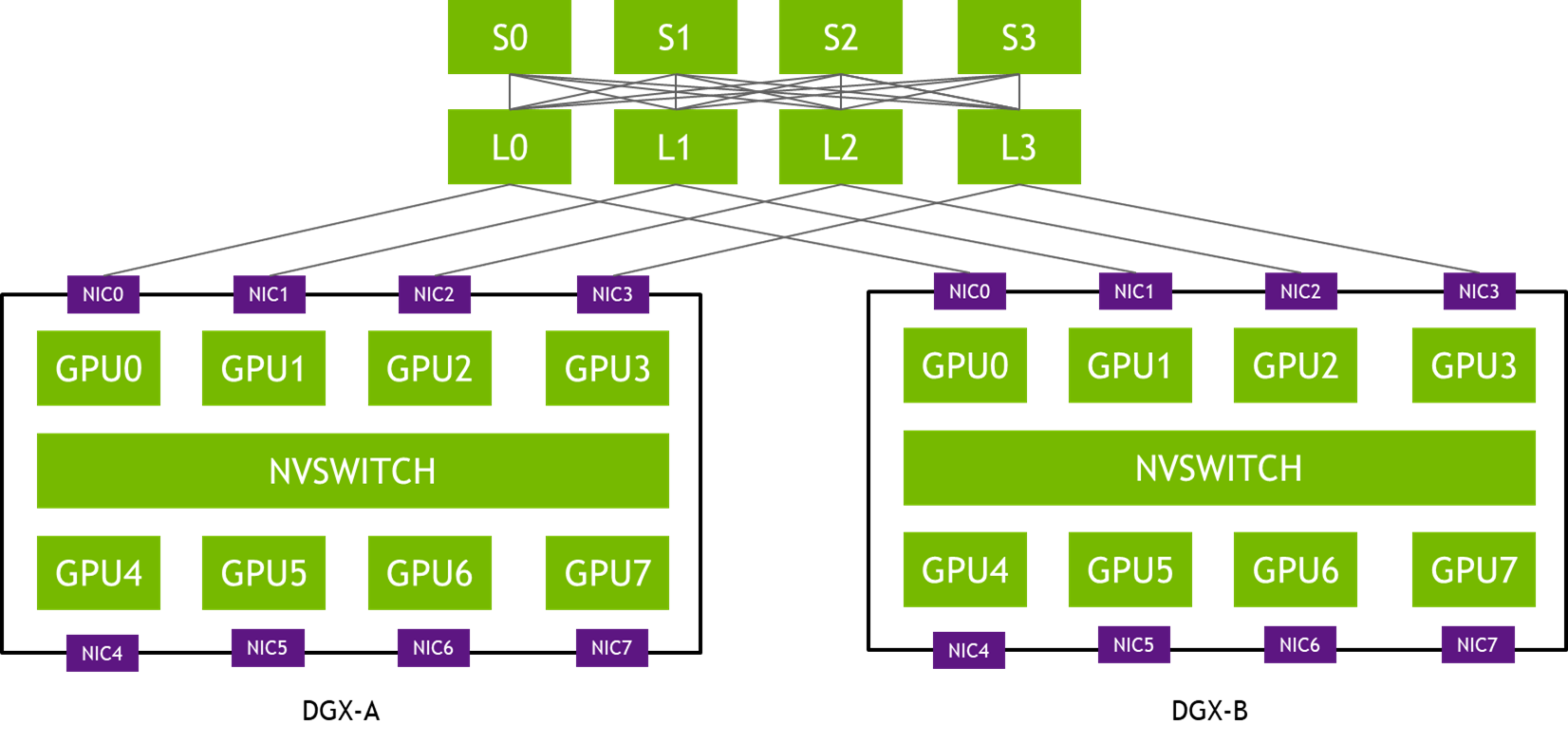
图 1.通道优化拓扑
在图 1 的拓扑中,每个 DGX 系统的 NIC-0 连接到同一个leaf 交换机 (L0),NIC-1 连接到同一个leaf 交换机 (L1),依此类推。这种设计通常称为 通道优化(rail-optimized)。通道优化(rail-optimized)的网络拓扑有助于all-reduce 性能最大化的同时最大限度地减少流之间的网络干扰。它还可以通过在通道之间建立更轻的连接来降低网络成本。
PXN利用节点内GPU之间的NVIDIA NVSwitch互联架构,首先将数据发送至与目标GPU处于同一通信通道的GPU,随后在不跨通道传输的情况下将数据送达目的地。这种机制实现了消息聚合与网络流量优化。
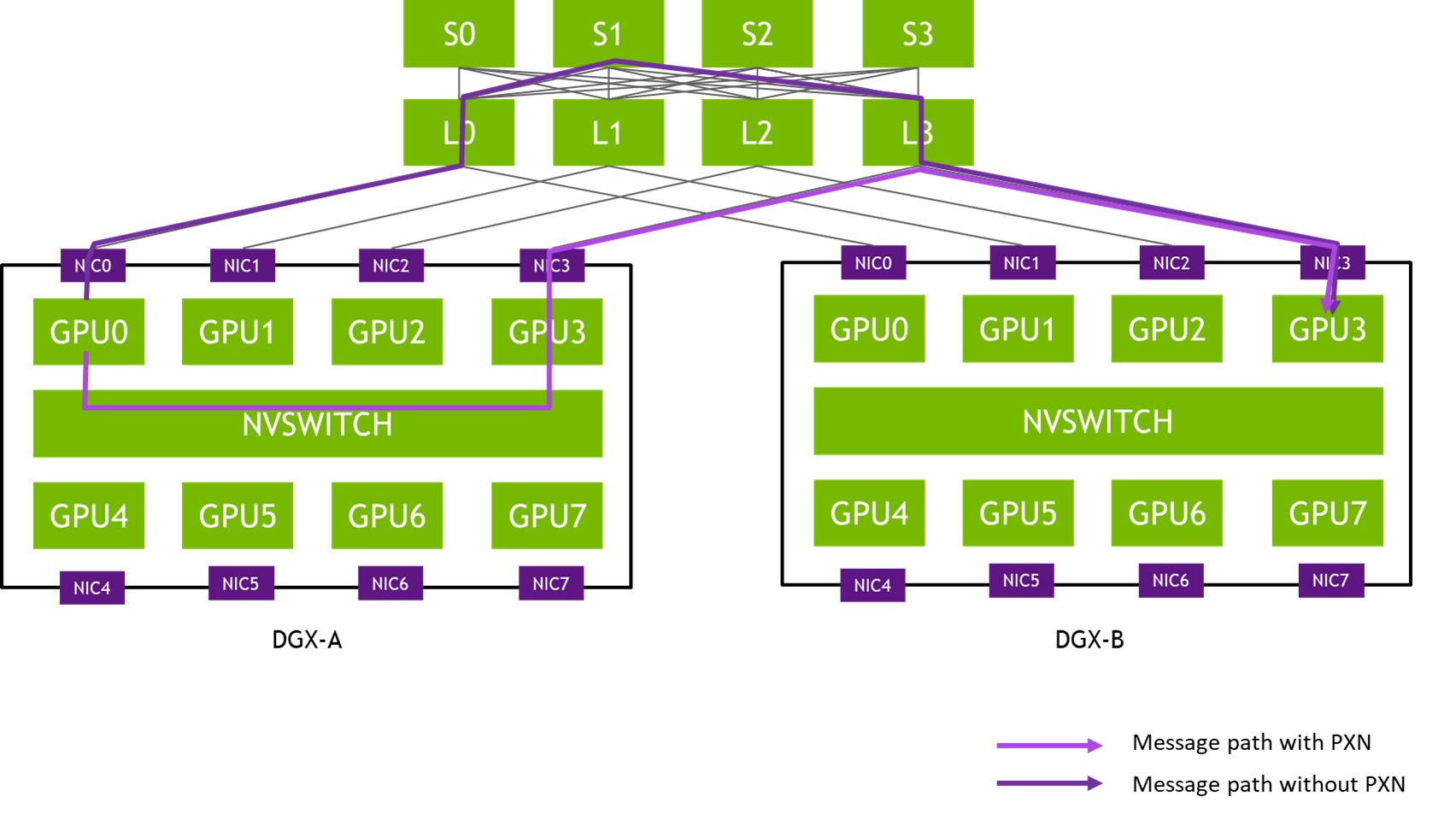
图2 从DGX-A中GPU0到DGX-B中GPU3的示例消息路径
在NCCL 2.12版本之前,图X中的消息需要穿越三级网络交换机(L0、S1和L3),可能引发拥塞并受其他流量影响导致延迟。该方案通过聚合同一网卡对 间传输的消息,提高有效消息速率与网络带宽最大化。
消息聚合机制
With PXN, all GPUs on a given node move their data onto a single GPU for a given destination. This enables the network layer to aggregate messages, by implementing a new multireceive function. The function enables the remote CPU proxy to send all messages as one as soon as they are all ready.
基于PXN架构,节点上所有GPU针对特定目标节点的数据传输都会先汇聚至单个GPU。该机制使得网络层可以通过实例化 multireceive 函数来实现消息聚合——远程CPU代理可在所有消息准备就绪后,将其作为单个数据流统一发送。
For example, if a GPU on a node is performing an all2all operation and is to receive data from all eight GPUs from a remote node, NCCL calls a multireceive with eight buffers and sizes. On the sender side, the network layer can then wait until all eight sends are ready, then send all eight messages at one time, which can have a significant effect on the message rate.
以all2all操作为例:当某节点上的GPU需要从远程节点的全部八个GPU接收数据时,NCCL会调用包含八个buffers及对应sizes的multireceive函数。在发送端,网络层将等待全部八个发送任务准备就绪,随后一次性发送,这对提升消息处理速率具有显著效果。
Another aspect of message aggregation is that connections are now shared between all GPUs of a node for a given destination. This means fewer connections to establish. It can also affect the routing efficiency, if the routing algorithm was relying on having a lot of different connections to get good entropy.
消息聚合的另一优势在于节点内所有GPU 到目标节点的连接实现了共享。这不仅减少了需要建立的连接数量,还可能影响路由效率——特别是当路由算法原本依赖大量独立连接来获取良好熵值时。
图3对比了启用与未启用PXN架构时alltoall 集合操作的完成耗时。此外,PXN还为 all-reduce操作提供了更灵活的GPU选择空间。
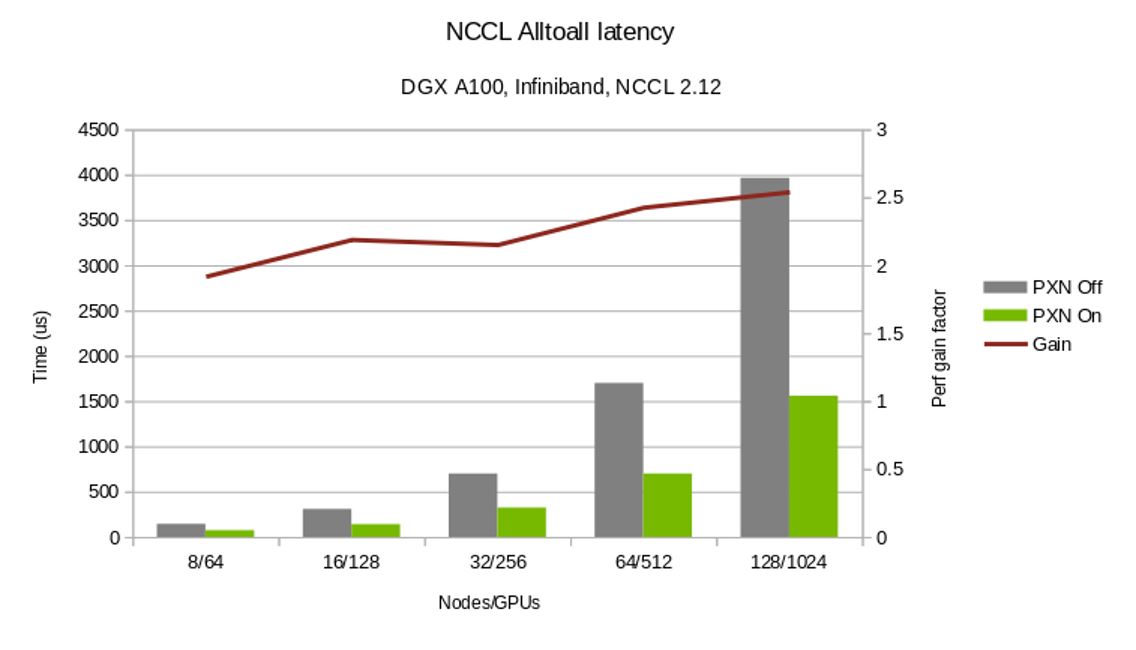
PXN improves all2all performance
Figure 4 shows that all2all entails communication from each process to every other process. In other words, the number of messages exchanged as part of an all2all operation in an N-GPU cluster is O(N2).
Figure 4. all2all collective operation across four participating processes
The messages exchanged between the GPUs are distinct and can’t be optimized using algorithms such as tree/ring (used for allreduce). When you run billion+ parameter models across 100s of GPUs, the number of messages can trigger congestion, create network hotspots, and adversely affect performance.
As discussed earlier, PXN combines NVLink and PCI communications to reduce traffic flow through the second-tier spine switches and optimizes network traffic. It also improves message rates by aggregating up to eight messages into one. Both improvements significantly improve all2all performance.
all-reduce on 1:1 GPU:NIC topologies
Another problem that PXN solves is the case of topologies where there is a single GPU close to each NIC. The ring algorithm requires two GPUs to be close to each NIC. Data must go from the network to a first GPU, go around all GPUs through NVLink, and then exit from the last GPU onto the network. The first and last GPUs must both be close to the NIC. The first GPU must be able to receive from the network efficiently, and the last GPU must be able to send through the network efficiently. If only one GPU is close to a given NIC, then you cannot close the ring and must send data through the CPU, which can heavily affect performance.
With PXN, as long as the last GPU can access the first GPU through NVLink, it can move its data to the first GPU. The data is sent from there to the NIC, keeping all transfers local to PCI switches.
This case is not only relevant for PCI topologies featuring one GPU and one NIC per PCI switch but can also happen on other topologies when an NCCL communicator only includes a subset of GPUs. Consider a node with 8xGPUs interconnected with an NVLink hypercube mesh (Figure 5).
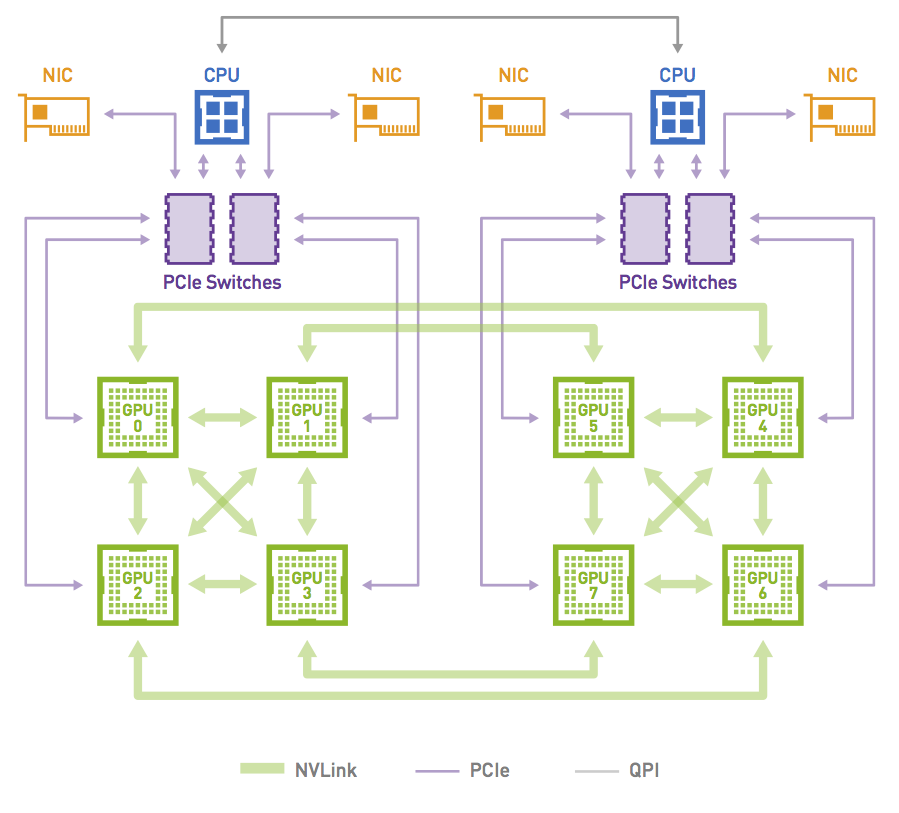
Figure 5. Network topology in a NVIDIA DGX-1 system
Figure 6 shows a ring that can be formed by leveraging the high-bandwidth NVLink connections that are available in the topology when the communicator includes all the 8xGPUs in the system. This is possible as both GPU0 and GPU1 share access to the same local NIC.
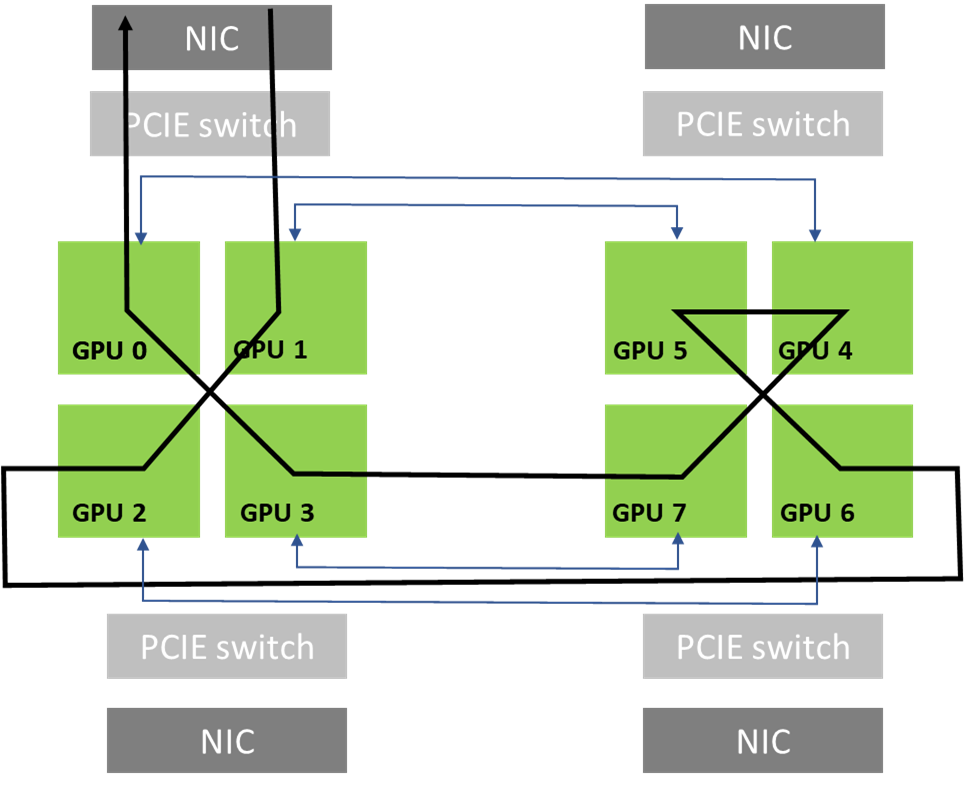
Figure 6. Example ring path used by NCCL
The communicator can just include a subset of the GPUs. For example, it can just include GPUs 0, 2, 4, and 6. In that case, creating rings is impossible without crossing rails: rings entering the node from GPU 0 would have to exit from GPUs 2, 4, or 6, which do not have direct access to the local NICs of GPUs 0 (NICs 0 and 1).
On the other hand, PXN enables rings to be formed as GPU 2 could move data back to GPU 0 before going through NIC 0/1.
This case is common with model parallelism, depending on how the model is split. If for example a model is split between GPUs 0-3, then another model runs on GPUs 4-7. That means GPU 0 and 4 take care of the same part of the model, and an NCCL communicator is created with all GPUs 0 and 4 on all nodes, to perform all-reduce operations for the corresponding layers. Those communicators can’t perform all-reduce operations efficiently without PXN.
The only way to have efficient model parallelism so far was to split the model on GPUs 0, 2, 4, 6 and 1, 3, 5, 7 so that NCCL subcommunicators would include GPUs [0,1], [2,3], [4,5] and [6,7] instead of [0,4], [1,5], [2,6], and [3,7]. The new PXN feature gives you more flexibility and eases the use of model parallelism.
Summary
The NCCL 2.12 release significantly improves all2all communication collective performance. Downloadthe latest NCCL release and experience the improved performance firsthand.
For more information see the following resources:
- NCCL product page
- NCCL: High-Speed Inter-GPU Communication for Large-Scale Training GTC session
- Massively Scale Your Deep Learning Training with NCCL 2.4
- 工作原理:GPU可在中间GPU上准备缓冲区,通过NVLink写入,然后通知管理目标NIC的CPU代理:数据已就绪。PXN先将GPU上的数据移动到与目的地相同的通道上,然后在不跨越通道<见后面说明> 的情况下将其发送到目的地,实现消息聚合和网络流量优化。
- 作用优势:PXN解决了每个NIC附近只有一个GPU的拓扑情况问题,只要最后一个GPU可通过NVLink访问第一个GPU,它就可将数据移动到第一个GPU,再由其发送到NIC,将所有传输保持在PCI交换机本地。同时,PXN通过将多达八条消息聚合为一条消息来提高消息速率,还能在给定目的地的所有GPU节点之间共享连接,减少连接数量,提高all2all性能,简化模型并行性的使用。
GPU 不是在其本地内存上准备一个缓冲区供本地 NIC 发送,而是在中间 GPU 上准备一个缓冲区,并通过 NVLink 写入该缓冲区。
然后,它通知管理该 NIC 的 CPU 代理数据已准备好,而不是通知其自己的 CPU 代理。
GPU-CPU同步可能会慢一些,因为它可能需要跨CPU插槽,但数据本身仅使用NVLink和PCI交换机,保证最大带宽。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号