
dubbo
一 什么是dubbo
下面从Dubbo官网直接拿来,看一下基于RPC层,服务提供方和服务消费方之间的调用关系,如图所示:
上述节点简单介绍以及他们之间的关系:
- Container: 服务运行容器,负责加载、运行服务提供者。必须。
- Provider: 暴露服务的服务提供方,会向注册中心注册自己提供的服务。必须。
- Consumer: 调用远程服务的服务消费方,会向注册中心订阅自己所需的服务。必须。
- Registry: 服务注册与发现的注册中心。注册中心会返回服务提供者地址列表给消费者。非必须。
- Monitor: 统计服务的调用次数和调用时间的监控中心。服务消费者和提供者会定时发送统计数据到监控中心。 非必须。
上图中,蓝色的表示与业务有交互,绿色的表示只对Dubbo内部交互。上述图所描述的调用流程如下:
- 服务提供方发布服务到服务注册中心;
- 服务消费方从服务注册中心订阅服务;
-
服务消费方调用已经注册的可用服务
二 dubbo通信协议
1. dubbo协议
缺省协议,使用基于mina1.1.7+hessian3.2.1的tbremoting交互。
连接个数:单连接
连接方式:长连接
传输协议:TCP
传输方式:NIO异步传输
序列化:Hessian二进制序列化
适用范围:传入传出参数数据包较小(建议小于100K),消费者比提供者个数多,单一消费者无法压满提供者,尽量不要用dubbo协议传输大文件或超大字符串。
适用场景:常规远程服务方法调用
1、dubbo默认采用dubbo协议,dubbo协议采用单一长连接和NIO异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况
2、他不适合传送大数据量的服务,比如传文件,传视频等,除非请求量很低。
配置如下:
<dubbo:protocol name="dubbo" port="20880" />
<dubbo:protocol name=“dubbo” port=“9090” server=“netty” client=“netty” codec=“dubbo”
serialization=“hessian2” charset=“UTF-8” threadpool=“fixed” threads=“100” queues=“0” iothreads=“9”
buffer=“8192” accepts=“1000” payload=“8388608” />
3、Dubbo协议缺省每服务每提供者每消费者使用单一长连接,如果数据量较大,可以使用多个连接。
<dubbo:protocol name="dubbo" connections="2" />
4、为防止被大量连接撑挂,可在服务提供方限制大接收连接数,以实现服务提供方自我保护
<dubbo:protocol name="dubbo" accepts="1000" />
2. rmi协议
Java标准的远程调用协议。
连接个数:多连接
连接方式:短连接
传输协议:TCP
传输方式:同步传输
序列化:Java标准二进制序列化
适用范围:传入传出参数数据包大小混合,消费者与提供者个数差不多,可传文件。
适用场景:常规远程服务方法调用,与原生RMI服务互操作
RMI协议采用JDK标准的java.rmi.*实现,采用阻塞式短连接和JDK标准序列化方式 。
3. hessian协议
基于Hessian的远程调用协议。
连接个数:多连接
连接方式:短连接
传输协议:HTTP
传输方式:同步传输
序列化:表单序列化
适用范围:传入传出参数数据包大小混合,提供者比消费者个数多,可用浏览器查看,可用表单或URL传入参数,暂不支持传文件。
适用场景:需同时给应用程序和浏览器JS使用的服务。
1、Hessian协议用于集成Hessian的服务,Hessian底层采用Http通讯,采用Servlet暴露服务,Dubbo缺省内嵌Jetty作为服务器实现。
2、Hessian是Caucho开源的一个RPC框架:http://hessian.caucho.com,其通讯效率高于WebService和Java自带的序列化。
4. http协议
基于http表单的远程调用协议。参见:[HTTP协议使用说明]
连接个数:多连接
连接方式:短连接
传输协议:HTTP
传输方式:同步传输
序列化:表单序列化
适用范围:传入传出参数数据包大小混合,提供者比消费者个数多,可用浏览器查看,可用表单或URL传入参数,暂不支持传文件。
适用场景:需同时给应用程序和浏览器JS使用的服务。
5. webservice协议
基于WebService的远程调用协议。
连接个数:多连接
连接方式:短连接
传输协议:HTTP
传输方式:同步传输
序列化:SOAP文本序列化
适用场景:系统集成,跨语言调用
三 dubbo序列化
dubbo支持hession、rmi(Java二进制序列化)、json、SOAP文本序列化多种序列化协议。但是 hessian 是其默认的序列化协议。
序列化是将一个对象变成一个二进制流就是序列化, 反序列化是将二进制流转换成对象。
为什么要序列化?
1. 减小内存空间和网络传输的带宽
2. 分布式的可扩展性
3. 通用性,接口可共用。
dubbo序列化:阿里尚未开发成熟的高效java序列化实现,阿里不建议在生产环境使用它
hessian2序列化:hessian是一种跨语言的高效二进制序列化方式。但这里实际不是原生的hessian2序列化,而是阿里修改过的hessian lite,它是dubbo RPC默认启用的序列化方式
json序列化:目前有两种实现,一种是采用的阿里的fastjson库,另一种是采用dubbo中自己实现的简单json库,但其实现都不是特别成熟,而且json这种文本序列化性能一般不如上面两种二进制序列化。
java序列化:主要是采用JDK自带的Java序列化实现,性能很不理想。
这四种主要序列化方式的性能从上到下依次递减。对于dubbo RPC这种追求高性能的远程调用方式来说,实际上只有1、2两种高效序列化方式比较般配,而第1个 dubbo 序列化由于还不成熟,所以实际只剩下2可用,所以dubbo RPC默认采用 hessian2 序列化。
但 hessian 是一个比较老的序列化实现了,而且它是跨语言的,所以不是单独针对java进行优化的。而dubbo RPC实际上完全是一种Java to Java的远程调用,其实没有必要采用跨语言的序列化方式(当然肯定也不排斥跨语言的序列化)。
最近几年,各种新的高效序列化方式层出不穷,不断刷新序列化性能的上限,最典型的包括:
专门针对Java语言的:Kryo,FST等等
跨语言的:ProtoBuf,Thrift等
这些序列化方式的性能多数都显著优于 hessian2。所以我们可以为dubbo引入Kryo和FST这两种高效 Java 来优化 dubbo 的序列化。
使用Kryo和FST非常简单,只需要在dubbo RPC的XML配置中添加一个属性即可:
<dubbo:protocol name="dubbo" serialization="kryo"/>
四 pb了解么,为什么性能高
可能大家比较习惯于 JSON or XML 数据存储格式,对于 Protocol Buffer 还比较陌生。Protocol Buffer 其实是 Google 出品的一种轻量并且高效的结构化数据存储格式,性能比 JSON、XML要高很多。
其实 PB 之所以性能如此好,主要得益于两个:第一,它使用 proto 编译器,自动进行序列化和反序列化,速度非常快,应该比 XML 和 JSON 快上了 20~100 倍;第二,它的数据压缩效果好,就是说它序列化后的数据量体积小。因为体积小,传输起来带宽和速度上会有优化。
五 路由机制
https://blog.csdn.net/prestigeding/article/details/80848594
六 谈谈dubbo的超时重试
dubbo 启动时默认有重试机制和超时机制。如果在一定的时间内,provider没有返回,则认为本次调用失败。重试机制出现在调用失败时,会再次调用,如果在配置的调用次数内都失败,则认为此次请求异常,消费端出现RpcException提示retry了多少次还是失败。
如果出现超时,通常是业务处理太慢,可在服务提供方执行 jstack PID > jstack.log 分析线程都卡在哪个方法调用上。如果不能调优性能,请将timeout设大。
dubbo消费端设置的超时时间需要根据业务实际情况来设定,如果设置的过短,一些复杂业务需要很长时间完成,导致在设定的超时时间内无法完成正常的业务处理。这样消费端达到超时时间,那么dubbo会进行重试,不合理的重试在一些特殊的业务场景下可能会引发很多问题。比如发送邮件,可能会发出多份重复邮件等。
dubbo调用服务不成功时,默认会重试两次。dubbo的路由机制,会把超时的请求路由到其他机器上,而不是本机尝试,所以dubbo的重试机制也能得到一定程度的保证。但是不合理地配置重试次数,当失败时会进行重试多次,这样在某个时间点出现性能问题,调用方继续重试请求为正常retries倍,容易引起服务雪崩。
最佳实践:
1.对于核心的服务中心,去除dubbo超时重试机制,并重新评估设置超时时间。
2.业务处理代码必须放在服务端,客户端只做参数验证和服务调用,不涉及业务流程处理
七 关于dubbo的配置上,你有什么经验
(1) 在Provider上尽量多地配置Consumer的属性
原因:
a. 作为服务的提供者,比服务使用方更清楚服务性能参数,如调用的超时时间,合理的重试次数等
b. 在provider配置后,consumer不配置则自动使用provider的配置,即作为了consumer端的缺省值。否则,consumer会使用consumer端的全局配置,这对于provider端往往是不可控的。
ps: 配置的优先级:
1. 方法级配置别优于接口级别,即小Scope优先
2. Consumer端配置优于Provider配置,优于全局配置
3. Dubbo Hard Code的配置值(默认)
根据规则2, 纵使消费端配置优于服务器配置,但消费端配置超时时间不能随心所欲,需要根据业务实际情况来设定。如果设置的太短,复杂业务本来就需要很长时间完成,服务端无法在设定的超时时间内完成业务处理; 如果设置太长,会由于服务端或者网络问题导致客户端大量线程挂起。
配置示例
<dubbo:service interface="com.alibaba.hello.api.HelloService" version="1.0.0" ref="helloService"
timeout="300" retry="2" loadbalance="random" actives="0"/>
<dubbo:service interface="com.alibaba.hello.api.WorldService" version="1.0.0" ref="helloService"
timeout="300" retry="2" loadbalance="random" actives="0" >
<dubbo:method name="findAllPerson" timeout="10000" retries="9" loadbalance="leastactive" actives="5" />
<dubbo:service/>
在provider端可以配置的consumer属性有:
1 timeout 方法调用超时时间
2 retry 失败重试次数,缺省是2(加上第一次调用,共调用三次)
3 loadbalance 负责均衡算法(即多个provider如何挑选provider调用),缺省是随机(random),还可以有轮训(roundrobin),最不活跃优先(leastactive, 指从consumer端并发调用效果最好的provider,这样可以相对减少并发的堆积)
4 actives 消费端最大并发调用限制,即当consumer对一个服务的并发调用达到上限后,新调用会wait直到超时。粒度上,在方法上配置(dubbo: method)则并发针对方法,在接口上配置(dubbo:service)则并发限制针对服务
(2) 在Provider上配置合理的provider属性
<dubbo:protocol threads="200" />
<dubbo:service interface="com.alibaba.hello.api.HelloService" version="1.0.0" ref="helloService" executes="200" >
<dubbo:method name="findAllPerson" executes="50" />
</dubbo:service>
Provider上可以配置的Provider端属性有:
- threads,服务线程池大小
- executes,一个服务提供者并行执行请求上限,即当Provider对一个服务的并发调用到上限后,新调用会wait(Consumer可能到超时)。在方法上配置(dubbo:method )则并发限制针对方法,在接口上配置(dubbo:service),则并发限制针对服务。
八 Dubbo 序列化协议
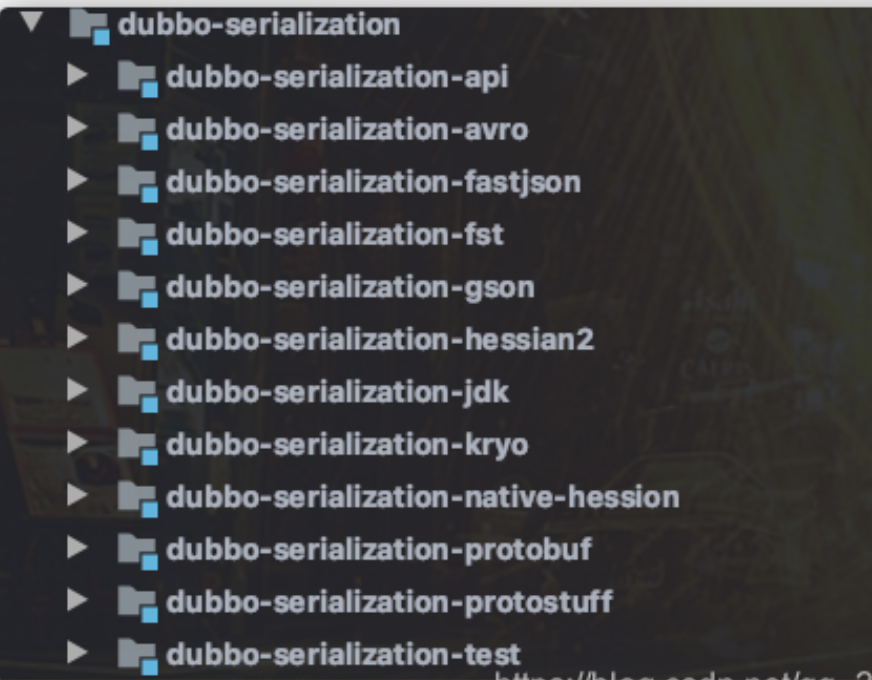
Dubbo 支持多种序列化方式:JDK 自带的序列化、hessian2、JSON、Kryo、FST、Protostuff,ProtoBuf 等等。
Dubbo 默认使用的序列化方式是 hessian2。
一般我们不会直接使用 JDK 自带的序列化方式。主要原因有两个:
- 不支持跨语言调用 : 如果调用的是其他语言开发的服务的时候就不支持了。
- 性能差:相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
JSON 序列化由于性能问题,我们一般也不会考虑使用。
像 Protostuff,ProtoBuf、hessian2 这些都是跨语言的序列化方式,如果有跨语言需求的话可以考虑使用。
Kryo 和 FST 这两种序列化方式是 Dubbo 后来才引入的,性能非常好。不过,这两者都是专门针对 Java 语言的。Dubbo 官网的一篇文章中提到说推荐使用 Kryo 作为生产环境的序列化方式。
九 Dubbo 中的 Invoker 概念了解么?
Invoker 是 Dubbo 领域模型中非常重要的一个概念,你如果阅读过 Dubbo 源码的话,你会无数次看到这玩意。就比如下面我要说的负载均衡这块的源码中就有大量 Invoker 的身影。
简单来说,Invoker 就是 Dubbo 对远程调用的抽象。
按照 Dubbo 官方的话来说,Invoker 分为
- 服务提供
Invoker - 服务消费
Invoker
假如我们需要调用一个远程方法,我们需要动态代理来屏蔽远程调用的细节吧!我们屏蔽掉的这些细节就依赖对应的 Invoker 实现, Invoker 实现了真正的远程服务调用。
十 Dubbo 的工作原理了解么?
下图是 Dubbo 的整体设计,从下至上分为十层,各层均为单向依赖。
左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口。

- config 配置层:Dubbo 相关的配置。支持代码配置,同时也支持基于 Spring 来做配置,以
ServiceConfig,ReferenceConfig为中心 - proxy 服务代理层:调用远程方法像调用本地的方法一样简单的一个关键,真实调用过程依赖代理类,以
ServiceProxy为中心。 - registry 注册中心层:封装服务地址的注册与发现。
- cluster 路由层:封装多个提供者的路由及负载均衡,并桥接注册中心,以
Invoker为中心。 - monitor 监控层:RPC 调用次数和调用时间监控,以
Statistics为中心。 - protocol 远程调用层:封装 RPC 调用,以
Invocation,Result为中心。 - exchange 信息交换层:封装请求响应模式,同步转异步,以
Request,Response为中心。 - transport 网络传输层:抽象 mina 和 netty 为统一接口,以
Message为中心。 - serialize 数据序列化层:对需要在网络传输的数据进行序列化。
十一 Dubbo 的 SPI 机制了解么? 如何扩展 Dubbo 中的默认实现?
SPI(Service Provider Interface) 机制被大量用在开源项目中,它可以帮助我们动态寻找服务/功能(比如负载均衡策略)的实现。
SPI 的具体原理是这样的:我们将接口的实现类放在配置文件中,我们在程序运行过程中读取配置文件,通过反射加载实现类。这样,我们可以在运行的时候,动态替换接口的实现类。和 IoC 的解耦思想是类似的。
Java 本身就提供了 SPI 机制的实现。不过,Dubbo 没有直接用,而是对 Java 原生的 SPI 机制进行了增强,以便更好满足自己的需求。
十二 注册中心的几个小问题
注册中心的作用了解么?
注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互。
服务提供者宕机后,注册中心会做什么?
注册中心会立即推送事件通知消费者。
监控中心的作用呢?
监控中心负责统计各服务调用次数,调用时间等。
注册中心和监控中心都宕机的话,服务都会挂掉吗?
不会。两者都宕机也不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表。注册中心和监控中心都是可选的,服务消费者可以直连服务提供者。
十三 Dubbo 提供的负载均衡策略有哪些?
在集群负载均衡时,Dubbo 提供了多种均衡策略,默认为 random 随机调用。我们还可以自行扩展负载均衡策略(参考 Dubbo SPI 机制)。
在 Dubbo 中,所有负载均衡实现类均继承自 AbstractLoadBalance,该类实现了 LoadBalance 接口,并封装了一些公共的逻辑。
RandomLoadBalance
根据权重随机选择(对加权随机算法的实现)。这是 Dubbo 默认采用的一种负载均衡策略。
RandomLoadBalance 具体的实现原理非常简单,假如有两个提供相同服务的服务器 S1,S2,S1 的权重为 7,S2 的权重为 3。
我们把这些权重值分布在坐标区间会得到:S1->[0, 7) ,S2->[7, 10)。我们生成[0, 10) 之间的随机数,随机数落到对应的区间,我们就选择对应的服务器来处理请求
LeastActiveLoadBalance
LeastActiveLoadBalance 直译过来就是最小活跃数负载均衡。
这个名字起得有点不直观,不仔细看官方对活跃数的定义,你压根不知道这玩意是干嘛的。
我这么说吧!初始状态下所有服务提供者的活跃数均为 0(每个服务提供者的中特定方法都对应一个活跃数,我在后面的源码中会提到),每收到一个请求后,对应的服务提供者的活跃数 +1,当这个请求处理完之后,活跃数 -1。
因此,Dubbo 就认为谁的活跃数越少,谁的处理速度就越快,性能也越好,这样的话,我就优先把请求给活跃数少的服务提供者处理。
如果有多个服务提供者的活跃数相等怎么办?
很简单,那就再走一遍 RandomLoadBalance 。
ConsistentHashLoadBalance
ConsistentHashLoadBalance 小伙伴们应该也不会陌生,在分库分表、各种集群中就经常使用这个负载均衡策略。
ConsistentHashLoadBalance 即一致性 Hash 负载均衡策略。 ConsistentHashLoadBalance 中没有权重的概念,具体是哪个服务提供者处理请求是由你的请求的参数决定的,也就是说相同参数的请求总是发到同一个服务提供者。
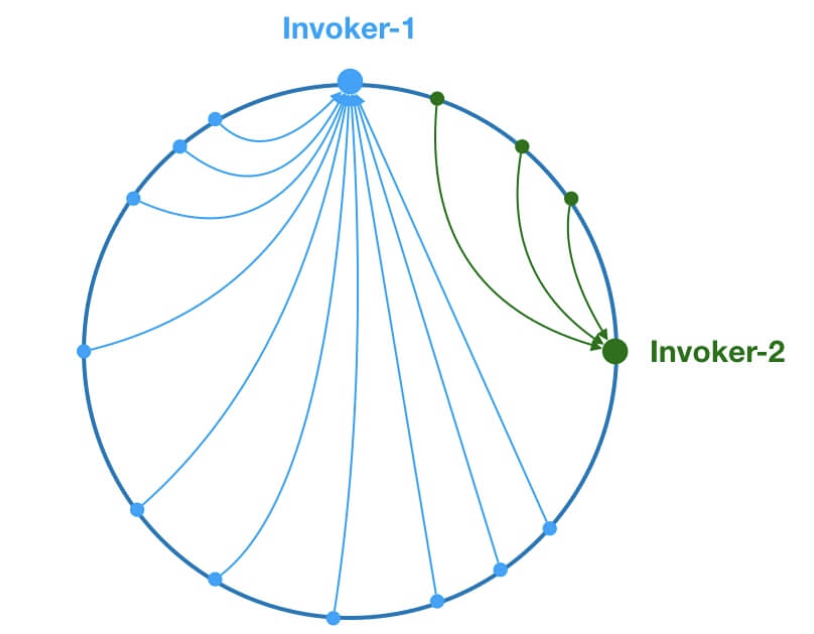
另外,Dubbo 为了避免数据倾斜问题(节点不够分散,大量请求落到同一节点),还引入了虚拟节点的概念。通过虚拟节点可以让节点更加分散,有效均衡各个节点的请求量。
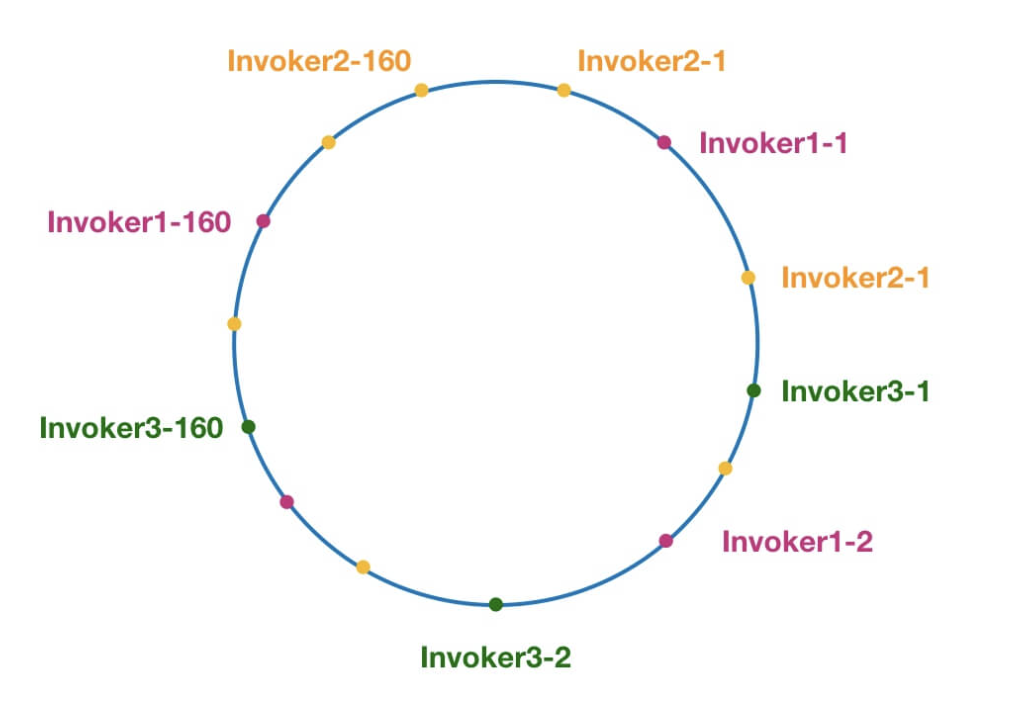
RoundRobinLoadBalance
加权轮询负载均衡。
轮询就是把请求依次分配给每个服务提供者。加权轮询就是在轮询的基础上,让更多的请求落到权重更大的服务提供者上。比如假如有两个提供相同服务的服务器 S1,S2,S1 的权重为 7,S2 的权重为 3。
如果我们有 10 次请求,那么 7 次会被 S1 处理,3 次被 S2 处理。
但是,如果是 RandomLoadBalance 的话,很可能存在 10 次请求有 9 次都被 S1 处理的情况(概率性问题)。
Dubbo 中的 RoundRobinLoadBalance 的代码实现被修改重建了好几次,Dubbo-2.6.5 版本的 RoundRobinLoadBalance 为平滑加权轮询算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号