1. Spark 是什么

##### 1. Spark 是什么
`
Apache Spark is a unified analytics engine for large-scale data processing
1. spark 是一个 统一的 用来分析大规模数据的 分析引擎
2. 它提供了 各种语言的API(Java、Scala、Python 和 R) 来操作spark
3. 它提供了 高级工具 SparkSQL、MLlib、GraphX、SparkStreaming
`
2. 开发 Spark 的目的是什么
##### 2. 开发 Spark 的目的是什么?
`
1. 用来 替换 Hadoop中的 MapReduce
`
3. Spark 优于 Mr 之处
##### 3. Spark 优于 Mr 之处
`
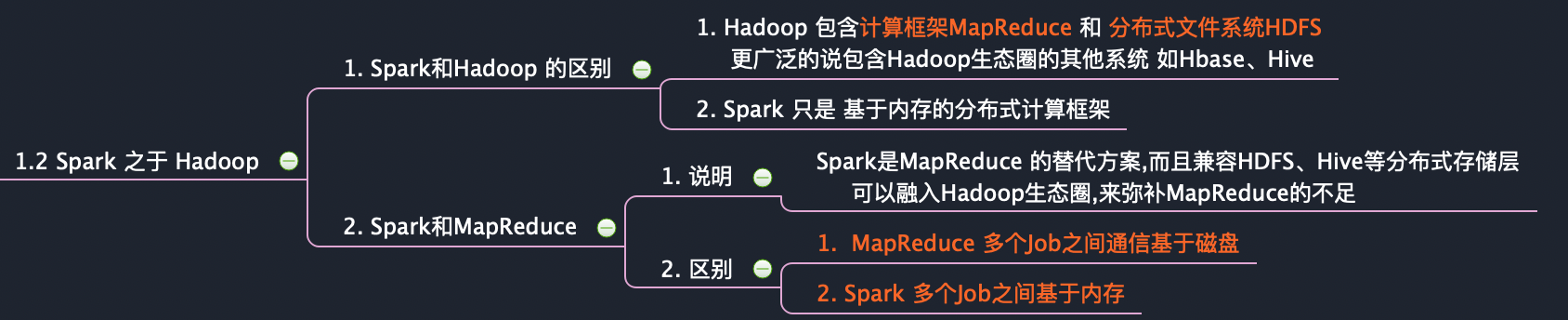
1. 多个Job之间的 数据通信
Spark 多个Job之间的 数据通信 是基于内存的
Spark 只有在 shuffle 的时候 会将数据写入磁盘
MR 多个Job之间的 数据通信 是基于磁盘的
Mr 中 多个Mr 任务时,数据交互 也要依赖磁盘
2. 处理数据的算子
Spark 基于RDD 提供了丰富的算子
可以 在内存中对数据集 进行多次迭代,用来支持复杂的计算
3. 启动任务时间
Spark Task 的启动时间快 => Spark 采用fork线程的方式
Mr Task 的启动时间慢 => Mr 采用创建进程的方式
4. 缓存机制
Spark 的缓存机制 比 Mr的缓存机制 高效
`
4. Spark 核心模块

##### 4. Spark 核心模块
`
底层支持 => Spark Core
上层应用 => SparkSQL、SparkStreaming、Spark MLilib、Spark Graphx
`



 浙公网安备 33010602011771号
浙公网安备 33010602011771号