
02_Hadoop集群部署+HA(2.9版本)
0. 安装说明
0.1 部署准备
linux(centos7+jdk1.8+ssh免密登入+关闭防火墙)+hadoop-2.9.2.tar.gz
0.2 安装模式
1.单机模式:不能使用HDFS,只能使用MapReduce,所以单机模式最主要的目的是在本机调试mapreduce代码
2.伪分布式模式:用多个线程模拟多台真实机器,即模拟真实的分布式环境
3.完全分布式模式:用多台机器(或启动多个虚拟机)来完成部署集群
0.3 安装包目录说明
bin目录:命令脚本
etc/hadoop:存放hadoop的配置文件
lib目录:hadoop运行的依赖jar包
sbin目录:启动和关闭hadoop等命令都在这里
libexec目录:存放的也是hadoop命令,但一般不常用
share目录:存放的用户指南、部署手册,建议多看(官方部署手册路径:hadoop-3.1.3\share\doc\hadoop\index.html)
0.4 节点部署配置
1. hadoop安装包下载
apache下载地址:http://www.apache.org/dyn/closer.cgi/hadoop/common/
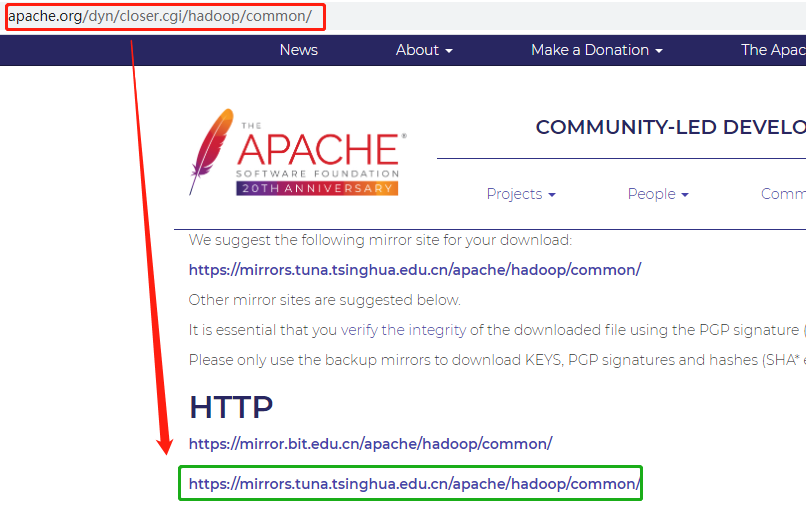
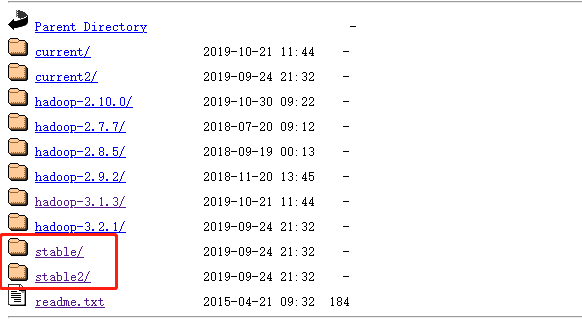
下载注意:下载是记得要现在稳定版本
2. 准备安装环境
2.1 支撑平台(linux-centos7)
2.2 环境设置
1.配置免密登入 #可以去看这里
2.关闭防火墙 #可以去看这里
2.3 所需软件
2.4.1 安装jdk
1.版本兼容性 请查看:https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions
2.解压jdk+配置环境变量 #可以去看这里
2.4.2 安装ssh、pdsh
$ sudo apt-get install ssh
$ sudo apt-get install pdsh
3.上传、解压hadoop安装包
tar -xvf hadoop-2.9.2.tar.gz
4.修改相关配置文件
4.1 配置 etc/hadoop/hadoop-env.sh
#指定jdk路径
export JAVA_HOME=/home/software/jdk1.8
source /etc/hadoop/hadoop-env.sh
4.2 配置 etc/hadoop/core-site.xml
<configuration>
<!-- 配置文件说明:配置数据上传和下载所用的端口,rpc协议+指定namenode所在主机和端口 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://app2:9000</value>
</property>
<!-- 指定临时目录:默认为/tmp/hadoop-${user.name},风险是机器重启或关机后会清空 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.9</value>
</property>
</configuration>
参数配置及说明:hadoop-2.9.2/share/doc/hadoop/hadoop-project-dist/hadoop-common/core-default.html
4.3 配置 etc/hadoop/hdfs-site.xml
<!--指定secondary namenode http、https 的ip和端口 --> <configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>app3:50090</value> <description> The secondary namenode http server address and port. </description> </property> <property> <name>dfs.namenode.secondary.https-address</name> <value>app3:50091</value> <description> The secondary namenode HTTPS server address and port. </description> </property>
</configuration>
参数配置及说明:hadoop-2.9.2\share\doc\hadoop\hadoop-project-dist\hadoop-hdfs\hdfs-default.xml
4.4 配置 etc/hadoop/slaves(指定datanode所在机器)
app3
app4
app5
4.4 配置 etc/hadoop/masters(指定namenode所在机器)
5. 格式化namenode
$ bin/hdfs namenode -format
6. 启动hdfs
6.1 启动命令
$ sbin/start-dfs.sh
6.2 测试hdfs命令
1.创建目录
bin/hdfs dfs -mkdir /user
2.上传文件
bin/hdfs dfs -put 文件名称 /user
6.3 登入Namenode管理界面
默认地址与端口:http://app2:50070 (确保防火墙关闭或端口开放+端口可在hdfs-default.xml中修改)
6.4 查看hdfs相关进程

7.停止hdfs
$ sbin/stop-dfs.sh
8. 为什么我的mr程序会在本地运行
因为没有开启yarn(resourcemanager、NodeManager)进程
9. 开启yarn(如果不开启,mr在本地运行)
9.1 配置 etc/hadoop/mapred-site.xml
<!--指定mr运行在yarn上,如果不配置此项mr将运行在本地 -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
参数配置及说明:hadoop-2.9.2\share\doc\hadoop\hadoop-mapreduce-client\hadoop-mapreduce-client-core\mapred-default.xml
9.2 配置 etc/hadoop/yarn-site.xml
<configuration>
<!--指定yarn的resoucemanager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>app2</value>
</property>
<!--指定resoucemanager的web的ip和端口-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>app2:8088</value>
</property>
<!--NodeManager获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.hostname</name>
<value>app3</value>
</property>
</configuration>
参数配置及说明:hadoop-2.9.2\share\doc\hadoop\hadoop-yarn\hadoop-yarn-common\yarn-default.xml
9.3 启动yarn
$ sbin/start-yarn.sh
9.4 查看yarn相关进程
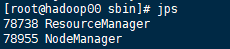
9.5 登入yarn管理界面
默认地址与端口:http://app2:8088/(确保防火墙关闭或端口开放+端口可在yarn-site.xml中修改)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号