
day40-hadoop-mapreduce
day40-hadoop-mapreduce
hadoop-mapreduce
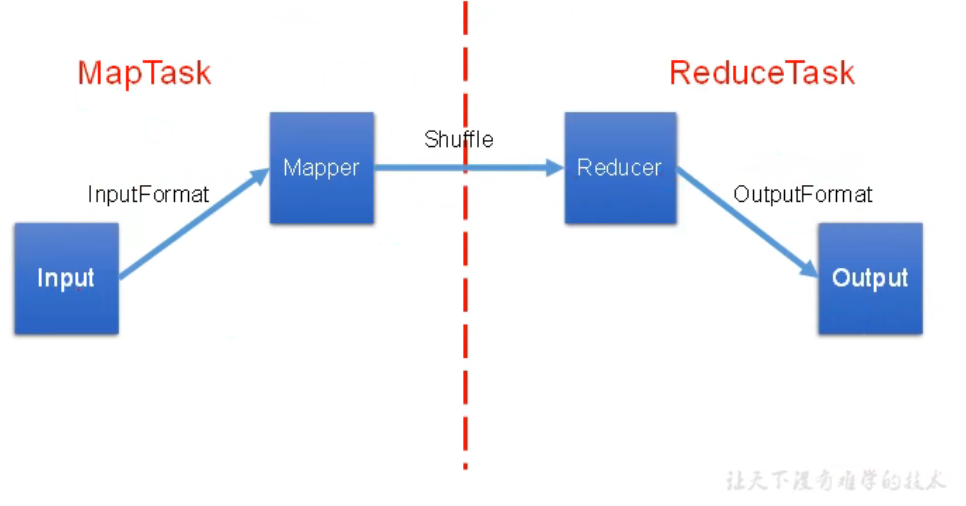
MapReduce框架原理
MapReduce的流程
粗略过程:数据输入 -> map处理 -> shuffle -> reduce处理 -> 数据的输出
InputFormat数据输入
切片与MapTask并行度决定机制
- 问题的引入
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
思考:1G的数据,启动8个MapTask,可以提高集群的并发处理额能力。那么1K的数据,也启动8个MapTask,会提高集群性能吗?MapTask并行任务是否越多越好呢?那些因素影响了MapTask并行度?
-
MapTask并行度决定机制
- 数据块:Block是HDFS物理上把数据分成一块一块
- 数据切片:只是逻辑上对输入进行分片,并不会再磁盘上将其切分成片进行存储
数据块:描述的是数据存储到HDFS时,从物理上将文件切分成一个一个的块 数据切片:描述的是数据计算时,从逻辑上将文件切分成一个一个的片,实际上每个切片就是记录一下我要读取文件的那一部分数据 问题:如果固定大小进行切片,最后一块的数据能保证数据的完整性吗? hadoop内部会保证数据的完整性,避免这种事发生 切片与MapTask的关系 有多少个切片,就需要启动多少个MapTask来处理 1个mapTask处理一个切片的数据 切片的大小 切片的大小默认情况下等于块的大小
默认的切片规则的源码解读
FileInputFormat 类
// 获取待处理的切片信息
public List<InputSplit> getSplits(JobContext job) throws IOException {
// 获取最小的切片大小,默认为0
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
getMinSplitSize(job):通过配置文件获取切片大小,"mapreduce.input.fileinputformat.split.minsize"
如果没获取到 job.getConfiguration().getLong(SPLIT_MINSIZE, 1L); 默认为 1
// 获取切片的最大值
long maxSize = getMaxSplitSize(job);
context.getConfiguration().getLong(SPLIT_MAXSIZE,
Long.MAX_VALUE)
SPLIT_MAXSIZE:"mapreduce.input.fileinputformat.split.maxsize" 此配置项没有配置过
所以获取到的是Long.MAX_VALUE
// 获取块的大小
long blockSize = file.getBlockSize();
// 计算切片的大小
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
Math.max(minSize, Math.min(maxSize, blockSize));// 决定了默认的切片大小等于块大小
思考:如何调大或调小切片的大小?
调小的话:maxSize 调小
调大的话:minSize 调大
// 剩余文件大小 / 切片大小 大于 1.1 才会继续切片,目的:防止出现过小的切片
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP)
- InputFormat原码解析
InputFormat:负责数据输入
getSplits(): 生成切片
createRecordReader(): 创建RecordReader对象,负责数据的读取
子抽象类:FileInputFormat
1) getSplits():默认切片方法的实现
// 对文件进行切片的时候,会判断这个文件是否可切分
2) isSplitable():// 判断文件是否可切片,统一的实现,返回true
具体的实现类:
1) TextInputFormat: 是默认使用的InputFromat类
createRecordReader():创建LineRecordReader对象
siSplitable():重写了该方法,对各种压缩文件进行了判断,是否可切片
切片的规则用的是FileInputFormat中的实现
2) CombineTextInputFormat 解决小文件场景生成过多切片的问题
FileInputFormat切片机制
- 切片机制
1. 简单地按照文件的内容长度进行切片
2. 切片大小,默认等于Block大小
3. 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
TextInputFormat
- FileInputFormat实现类
思考:在运行MapReduce程序时,输入的文件格式包括:基于行的日志文件、二进制格式文件、数据库表等。那么,针对不同的数据类型,MapReduce是如何读取这些数据的呢?
FileInputFormat常见的接口实现类包括:TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat等
CombineTextInputFormat 切片机制
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率及其低下。
- 应用场景:
CombineTextInputFormat 用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件可以交给一个MapTask处理。
- 虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job,419304)
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值
- 切片机制
生成切片过程包括:虚拟存储过程和切片过程二部分。

1. 虚拟存储过程:
将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果步大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)
例如:setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所有将剩余的4.02M文件切人成(2.01M和2.01M)两个文件
2. 切片过程:
MapReduce工作流程
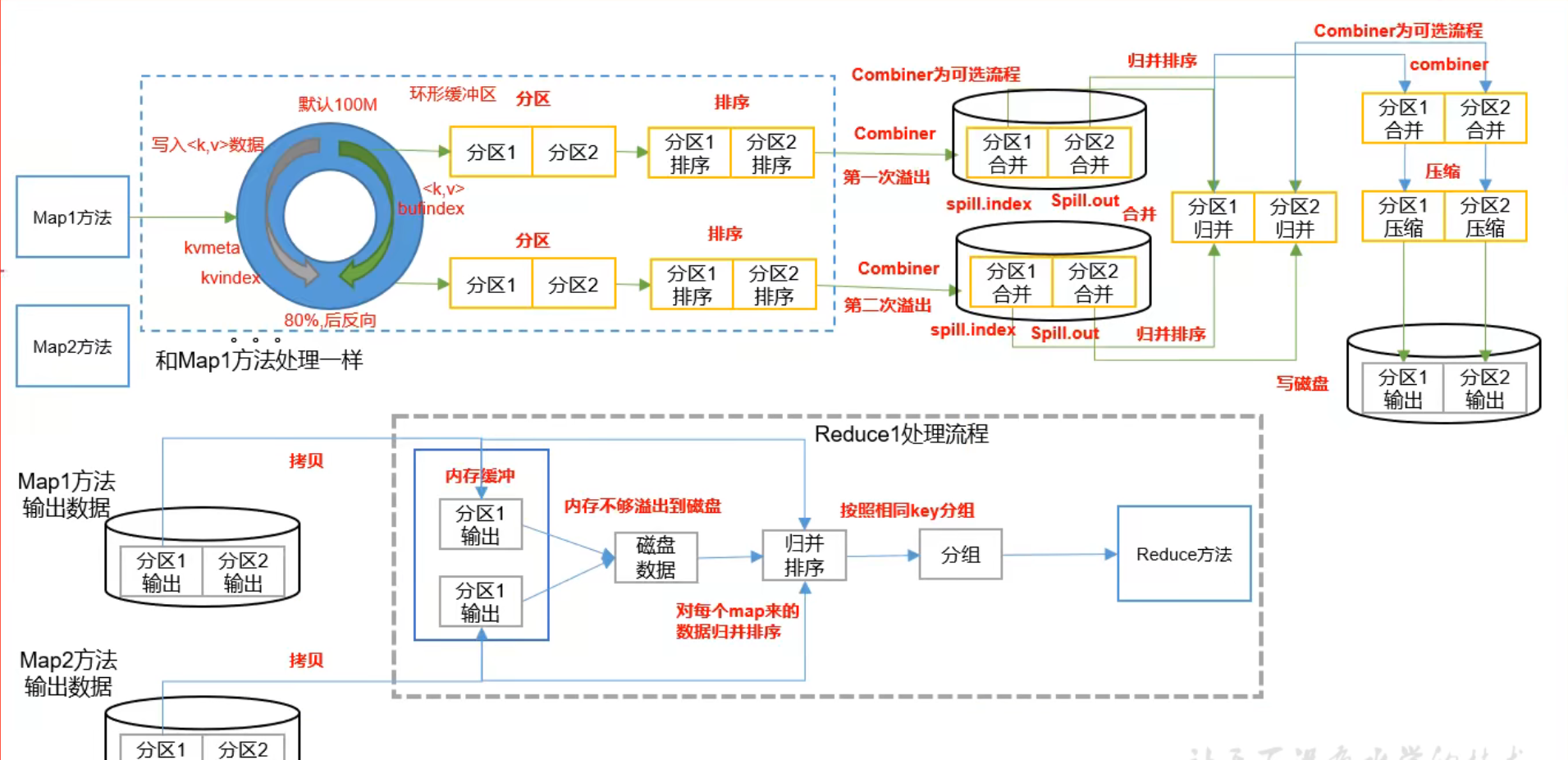
Shuffle机制
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。
Shuffle:洗牌,按照一定的规则,对数据进行清洗,把杂乱无章的数据进行整理,形成有规律的数据
Shuffle具体的划分:
map -> sort(map阶段) -> copy(reduce阶段) -> sort(reduce阶段) -> reduce
Partition分区
- 问题引出
要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照手机归属地不同省份输出到不同文件中(分区)
- 默认分区
HashPartition 默认分区器
分区计算:根据key的hashcode值对reduce的个数取余操作得到分区号
分区与reduce个数的关系
NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext,
JobConf job,
TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException {
collector = createSortingCollector(job, reporter);
partitions = jobContext.getNumReduceTasks(); // 获取reduce的个数
if (partitions > 1) {
// 如果reduce的个数大于1,会获取分区器对象,获取的过程是读取mapreduce.job.partitioner.class配置的值,如果配置有值,就使用该值指定的分区器,如果配置没值,就是用默认的分区器对象HashPartition
partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>)
ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job);
} else {
// 如果reduce的个数不大于1,也就意味着reduce的个数是默认的1,此种情况不需要进行分区计算,所以直接返回的分区号是固定的0
partitioner = new org.apache.hadoop.mapreduce.Partitioner<K,V>() {
@Override
public int getPartition(K key, V value, int numPartitions) {
return partitions - 1;
}
};
}
}
自定义分区
- 问题
输入数据 phone.txt
期望输出数据
手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中
- 步骤
1. 自定义分区类,继承Partition类
2. 在driver中设置自定义的分区类
3. 设置reduce的个数
- 代码(与writableflow一样,只需要添加一个分区类,并注册,最后根据分区数量设置reduce的数量)
package lc.mapreduce.mapper.partitioner2;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* 泛型指定 mapper 输出的k v的数据类型
*/
public class PhonePartitioner extends Partitioner<Text, FlowBean> {
/**
* 需求:按照手机号的前三位进行分区
* 136 --> 0
* 137 --> 1
* 138 --> 2
* 139 --> 3
* 其他 --> 4
*
* @param text key
* @param flowBean value
* @param numPartitions 分区数,reduce的个数
* @return
*/
@Override
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
// 1. 获取手机号
String phone = text.toString();
// 2. 开始分区
int partition = 4;
if (phone.startsWith("136")) {
partition = 0;
} else if (phone.startsWith("137")) {
partition = 1;
} else if (phone.startsWith("138")) {
partition = 2;
} else if (phone.startsWith("139")) {
partition = 3;
}
return partition;
}
}
public class FlowDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 创建配置对象
Configuration conf=new Configuration();
// 创建Job对象
Job job=Job.getInstance(conf);
// 注册驱动
job.setJarByClass(FlowDriver.class);
// 与mapper和reduce关联
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
// 设置map输出数据的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 设置最终输出的数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 设置文件输入和输出的路径
FileInputFormat.setInputPaths(job,new Path("D:\\a测试文件\\input\\writableflow"));
FileOutputFormat.setOutputPath(job,new Path("D:\\a测试文件\\output\\writableflow4"));
// 设置分区器
job.setPartitionerClass(PhonePartitioner.class);
// 设置reduce的个数
job.setNumReduceTasks(5);
//提交job
job.waitForCompletion(true);
}
}
- 注意事项
1. 如果ReduceTask的数量 > getPartition的结果数,则会多产生几个空的输出文件 part-r-000xx;
2. 如果 1<ReduceTask的数量 <getPartition的结果数,则有一部分分区数据无处安放,会Exception
3. 如果ReduceTask的数量=1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件part-t-00000
4. 分区号必须从0开始,逐1累加
WritableCompareable 排序
- 排序概述
排序是MapReduce框架中最重要的操作之一
MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
对于MapTask,他会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行依次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,他会对磁盘上所有文件进行归并排序
对于ReduceTask,他从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写磁盘上,否则存储在内存中。如果磁盘文件数据达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内存中文件大小或者数据超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。
排序
排序的本质是什么?比较
比较相关的类和接口
Comparable : 比较接口,通过compareTo 定义比较规则
Comparator: 比较器,通过compara 定义比较规则
hadoop使用的排序类和接口:
WritableComparable:支持序列化和比较
WritableComparator:比较器
hadoop如何实现排序比较?
-
排序的分类
- 部分排序
MapReduce根据输入记录的键对数据集排序。保证输出的每个文件内部有序。- 全排序
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因为一台及其处理所有文件,丧失了MapReduce所提供的并行架构。- 辅助排序
在Reduce端对key进行分组。应用于:在接受的key为bean对象时,想让一个或几个字段相同(全部字段比较不同)的key进入到同一个reduce方法时,可以采用分组排序- 二次排序
在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序
其他
idea快捷键
ctrl+f 本页查找 相当于eclipse的ctrl+h
ctrl+shift+r 全局查找
ctrl+shift+n 按文件名搜索文件
ctrl+h 查看类的继承关系
alt+F7 查找类或方法在哪被使用
shift+shift 搜索任何东西
crtl+n 按名字搜索

 浙公网安备 33010602011771号
浙公网安备 33010602011771号