



day36-s-hadoop-hdfs
day36-s-hadoop-hdfs
hadoop-hdfs
练习:输出文件和目录
package com.liuchao.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.File;
import java.io.IOException;
import java.net.URI;
public class Test01 {
private FileSystem fs; // hdfs 文件系统对象
private URI uri; // 统一资源标识符
private Configuration conf; // hdfs 的配置文件对象
private String user; // 用户
// 获取连接
@Before
public void getConnect() {
try {
uri = new URI("hdfs://192.168.31.51:8020");
conf = new Configuration();
user = "atguigu";
fs = FileSystem.get(uri, conf, user);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
// 关闭连接
@After
public void close() {
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 输出文件和文件夹
// file:
// directory:
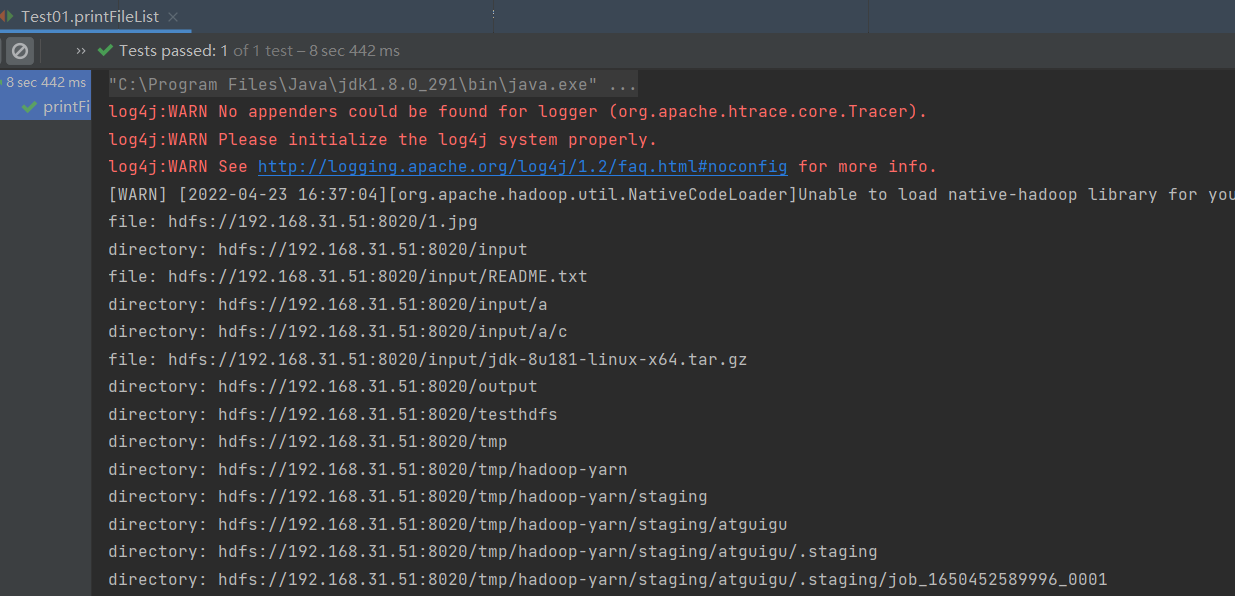
@Test
public void printFileList() throws Exception {
String dstPath="/";
listAllFileAndDirectory(dstPath,fs);
}
public void listAllFileAndDirectory(String path, FileSystem fs) throws IOException {
// 获取指定目录下的文件和文件夹
FileStatus[] listStatus = fs.listStatus(new Path(path));
// 迭代listStatus 是文件或数组
for (FileStatus status : listStatus) {
if(status.isFile()){
// 是文件
System.out.println("file: "+status.getPath().toString());
}else{
// 是目录
String directory=status.getPath().toString();
System.out.println("directory: "+directory);
listAllFileAndDirectory(directory,fs);
}
}
}
}
HDFS的数据流
HDFS写数据流程
- 剖析文件写入
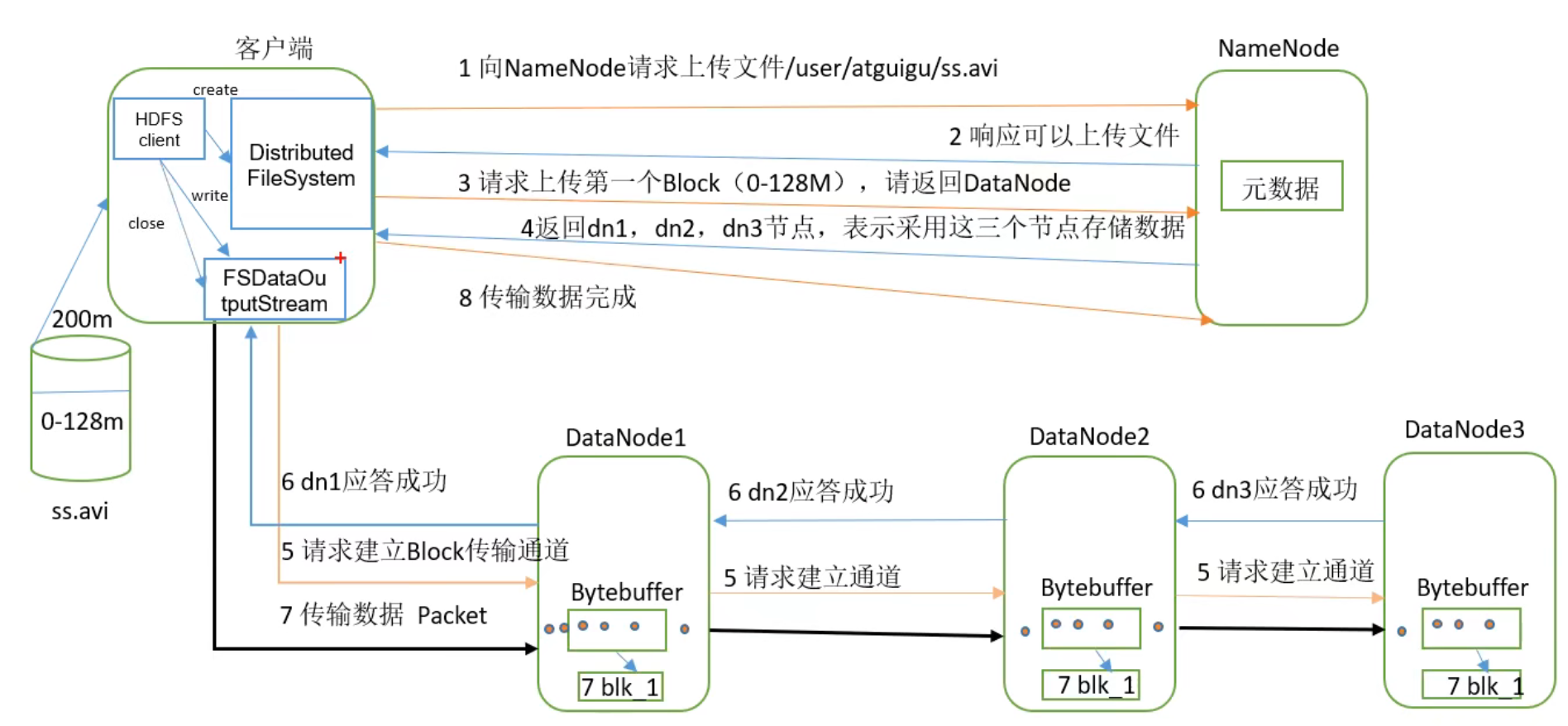
1. 客户端通过Distributed FileSystem 模块向NameNodw请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在
2. NameNode返回是否可以上传
3. 客户端请求第一个 Block上传到哪几个DataNode服务器上
4. NameNode 返回3个DataNode节点,分别为dn1、dn2、dn3
5、客户端通过FSDataOutputStream模块请求dn1 上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成
6、dn1、dn2、dn3逐级应答客户端
7、客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
8. 当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器(重复执行3-7步)
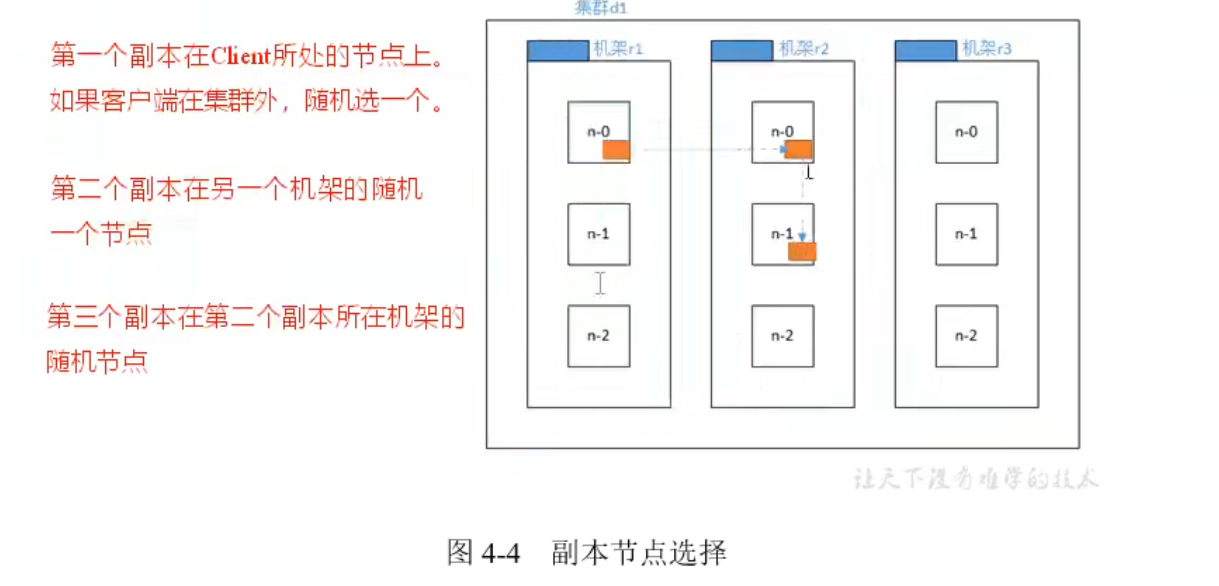
网络拓扑-节点距离计算
机架感知(副本存储节点的选择)
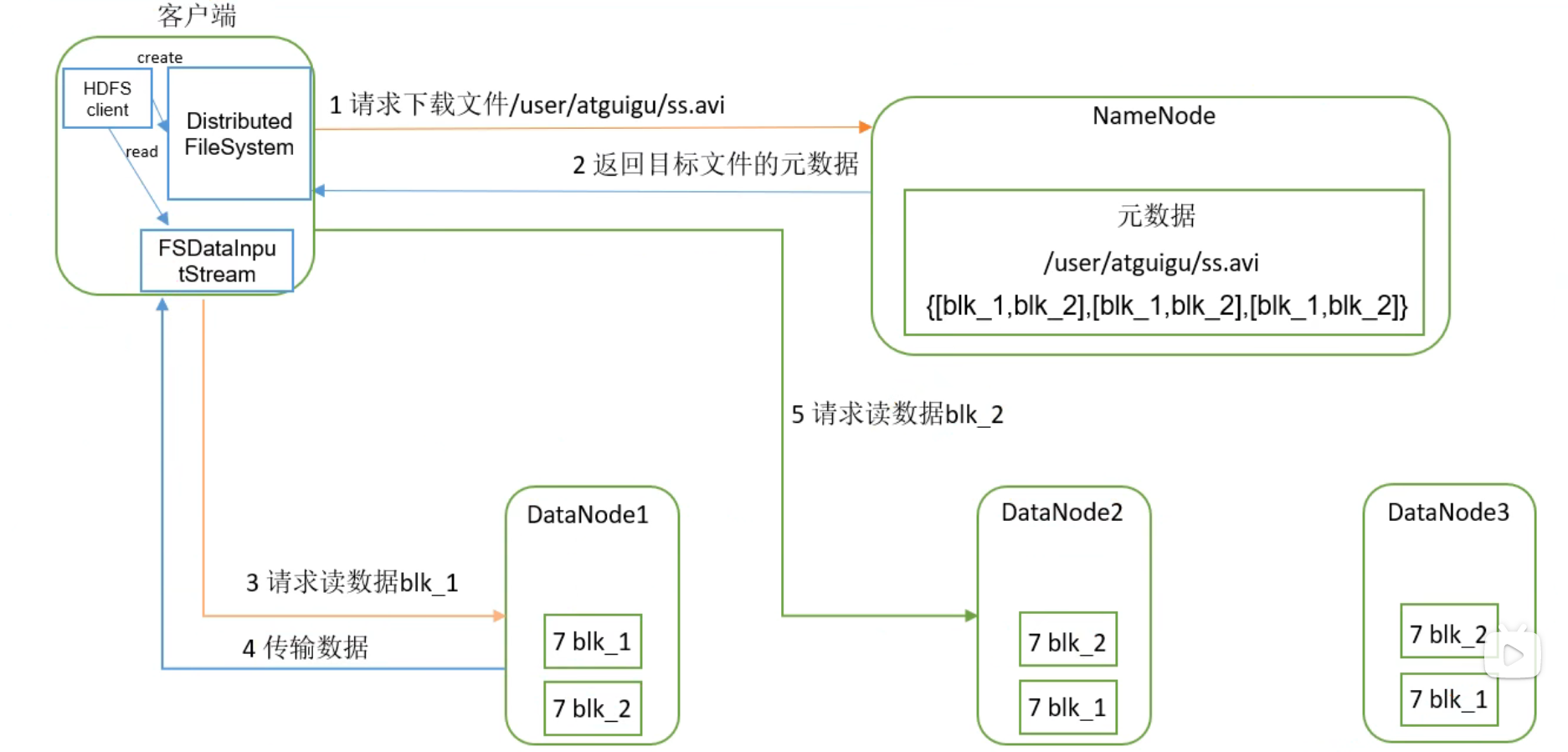
HDFS的读数据流程
NameNode和SecondaryNameNode的工作机制
NameNode
1. NameNode元数据信息维护到哪里?内存?磁盘?
内存和磁盘都有。
如果考虑数据的可靠性(数据不能随便就丢了),需要将元数据维护到磁盘。带来的问题是对磁盘的数据修改效率低。
如果考虑数据访问和修改的效率,需要将元数据维护到内存中。带来的问题是数据不可靠。
综合考虑:磁盘+内存,
2·磁盘 或 内存带来的问题?
如何保证内内存和磁盘数据的同步?
改内存的时候,会去该磁盘
方案:在内存中维护元数据,且在磁盘中通过fsimage(镜像文件)来维护元数据,并且通过edits(编辑日志),文件记录对数据的修改操作,记录的方式为文件末尾追加操作。
3. edits文件中记录的操作越来越多怎么办?
定时的将 fsImage文件和editis文件进行合并
4. 谁来做合并的是?
通过SecondaryNameNode来帮助NameNode完成合并的事
过程:当满足要合并的条件后以后,SecondaryNameNode会将NameNode中fsimage和当前正在使用的edits文件拉去过来,将fsimage和edits在SecondaryNameNode的内存中进行合并,合并完成生成一个新的fsImage文件,再将新的fsimage文件推送给NameNode替换NameNode的Fsimage文件。
其他
hdfs的路径问题:
路径问题:
fs.copyFromLocalFile() 从本地复制文件到hdfs
hdfs路径:new Path("/input/abc.txt")
"/input/abc.txt"不是完整的路径,完整的路径:hdfs://node1:8020/input/abc.txt
Linux网络问题:
前提:网络配置都正确,但是网路服务启动失败,导致xshell等连接失败
可能的原因是因为:NetworkManager服务冲突。因此将NetworkManager服务关掉并禁用。
通道正常运行,数据写入时,怎么保证数据在每台机器上的数据一致
ack 应答
如果 a 与 b 进行通信,怎么保证b接受到了a的信息?
b 返回给 a 一个应答


 浙公网安备 33010602011771号
浙公网安备 33010602011771号