
day35-s-hadoop
day35-s-hadoop
hadoop-hdfs
HDFS客户端
下载hadoop的包
配置环境变量
创建Maven项目
添加依赖pom.xml
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
log4j2.xml log4j文件的编写
<?xml version="1.0" encoding="utf-8" ?>
<configuration status="error" strict="true" name="XMLConfig">
<Appenders>
<!-- 类型为Console,名称为必须属性-->
<Appender type="Console" name="STDOUT">
<!--布局为PatternLayout方式
输出样式为[INFO] [2018-14-23 18:2:21][org.test.Console]-->
<layout type="PatternLayout"
pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n"/>
</Appender>
</Appenders>
<Loggers>
<!--可加性为false-->
<Logger name="test" level="info" additivity="false">
<AppenderRef ref="STDOUT"/>
</Logger>
<!--root loggerConfig配置-->
<Root level="info">
<AppenderRef ref="STDOUT"/>
</Root>
</Loggers>
</configuration>
TestHdfs.java 测试
package com.liuchao.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
/**
* 客户端性质的开发:
* 1. 获取客户端对象
* 2. 调用相关方法
* 3. 关闭
*/
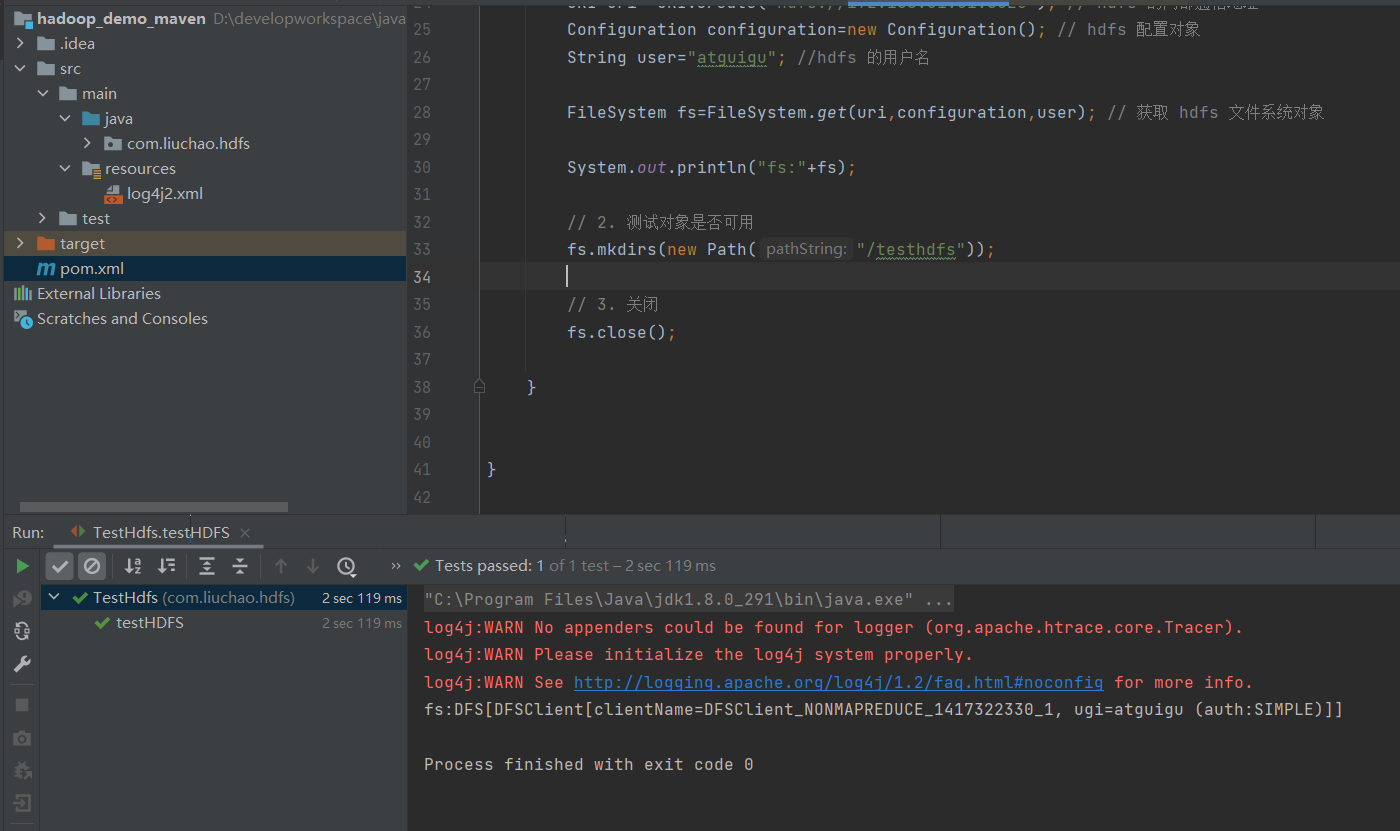
public class TestHdfs {
@Test
public void testHDFS() throws IOException, InterruptedException {
// 1. 创建文件系统对象
URI uri= URI.create("hdfs://192.168.31.51:8020"); // hdfs 的内部通信地址
Configuration configuration=new Configuration(); // hdfs 配置对象
String user="atguigu"; //hdfs 的用户名
FileSystem fs=FileSystem.get(uri,configuration,user); // 获取 hdfs 文件系统对象
System.out.println("fs:"+fs);
// 2. 测试对象是否可用
fs.mkdirs(new Path("/testhdfs"));
// 3. 关闭
fs.close();
}
}
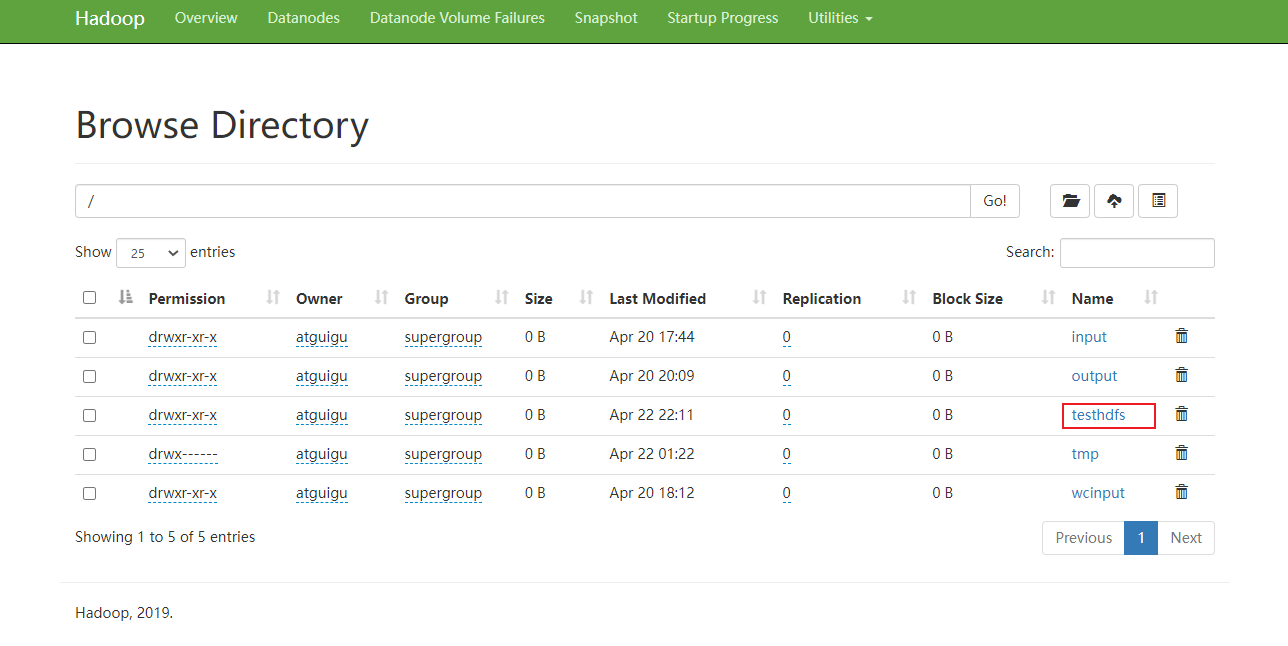
文件上传
fs.copyFromLocalFile(delSrc,overWrite,src,dst)
从本地复制文件到hdfs
参数:是否删除源文件、是否覆盖、源文件地址、目标文件地址
文件下载
fs.copuToLocalFile(delSrc,src,dst,useRawLocalSystem)
参数:
delSrc: 是否删除源文件
src: 源文件
dst: 目的文件
useRawLocalSystem: 是否使用crc验证,false: 使用 ture: 不使用
文件的改名和移动
文件改名
fs.rename(new Path("/wcinput/test.input"),new Path("/wcinput/wordcont.input"));
把 test.input 改为 wordcont.input
文件移动
fs.rename(new Path("/wcinput/test.input"),new Path("/"));
把 test.input 移动到 / 目录
文件详情的查看
@Test
public void listFile() {
try {
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while(listFiles.hasNext()){
LocatedFileStatus fileStaus=listFiles.next();
// 获取文件的详情
System.out.println("文件路径:"+fileStaus.getPath());
System.out.println("文件权限:"+fileStaus.getPermission());
System.out.println("文件所有者:"+fileStaus.getOwner());
System.out.println("文件属组:"+fileStaus.getGroup());
System.out.println("文件大小:"+fileStaus.getLen());
System.out.println("文件最后修改时间:"+fileStaus.getModificationTime());
System.out.println("文件副本数:"+fileStaus.getBlockSize());
System.out.println("文件的块位置:"+ Arrays.toString(fileStaus.getBlockLocations()));
BlockLocation[] blockLocations = fileStaus.getBlockLocations();
System.out.println("=========================");
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
文件和文件夹判断
@Test
public void listStatus() {
try {
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
for (FileStatus file : fileStatuses) {
if (file.isFile()) {
System.out.println(file.getPath()+":是文件");
}else {
System.out.println(file.getPath()+"是文件夹");
}
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
文件的删除
fs.delete(path,recursive)
path:文件路径
recursive:是否递归删除,文件,true和false都能删除,目录,必须是true,否则会抛出异常
如果目录非空,recursive:true
如果目录为空或是文件:recursive为true和false都可以
文件的上传和下载是怎么实现的?
文件的上传:基于IO流,把数据从本地写到HDFS
文件的下载:基于IO流,把数据从HDFS写到本地
- 文件上传
@Test
public void transformFile(){
// 待上传的文件
String sourceFile="D:/元气壁纸缓存/img/002.jpg";
//目的文件
String destFile="/1.jpg";
try {
// 输入流
FileInputStream fio=new FileInputStream(sourceFile);
// 输出流
FSDataOutputStream fout=fs.create(new Path(destFile));
// 流的拷贝
// byte[] buffer=new byte[1024];
// int i;
// while((i=fio.read(buffer))!=-1){
// fout.write(buffer,0,i);
// }
IOUtils.copyBytes(fio,fout,configuration);
IOUtils.closeStream(fio);
IOUtils.closeStream(fout);
} catch (Exception e) {
e.printStackTrace();
}
}
- 文件下载
@Test
public void downloadFile(){
// hdfs文件路径
String sourceFile="/1.jpg";
// dst文件目录
String dstFile=("d:/1.jpg");
try{
// 获取hdfs的输入流
FSDataInputStream fin = fs.open(new Path(sourceFile));
// 获取本地的输出流
FileOutputStream fout = new FileOutputStream(dstFile);
// 流的拷贝
// int i;
// while((i=fin.read())!=-1){
// fout.write(i);
// }
IOUtils.copyBytes(fin,fout,configuration);
IOUtils.closeStream(fin);
IOUtils.closeStream(fout);
}catch (Exception e){
e.printStackTrace();
}
// 获取本地的输出流
}
其他
hadoop在window环境搭建的可能出现的问题?
1 将windows依赖的hadoop.dll文件复制到 c:\windows\system32目录下
2 可能xindows缺少微软常用的运行库
3 重启电脑
权限问题

权限不足,当前user=dr.who
修改权限:
1. 把文件的所属用户改为dr.who
chown dr.who 文件
2. 修改配置文件是user=atguigu
3. hadoop的权限验证关闭
- 修改配置文件core-site.xml
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
- 关闭权限验证
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
URI
统一资源标识符(Uniform Resource Identify)用于标识某一互联网资源名称的字符串。
crc
校验算法
在传输数据的时候,数据可能会丢包,这样拿到数据后是不一样的。
所以使用crc校验
在刚开始文件传输的时候,对数据进行crc进行校验,得到一个结果
传输之后再对数据进行crc进行校验,得到一个结果,如果两次的结果一样,说明文件没有遭到破坏

 浙公网安备 33010602011771号
浙公网安备 33010602011771号