
day33-s-hadoop
day33-s-hadoop
hadoop
集群测试
- 上传小文件
创建目录
hadoop fs -mkdir -p /input/a/b
上传文件:把本地的文件上传到hadoop集群中
hadoop fs -put README.txt /input
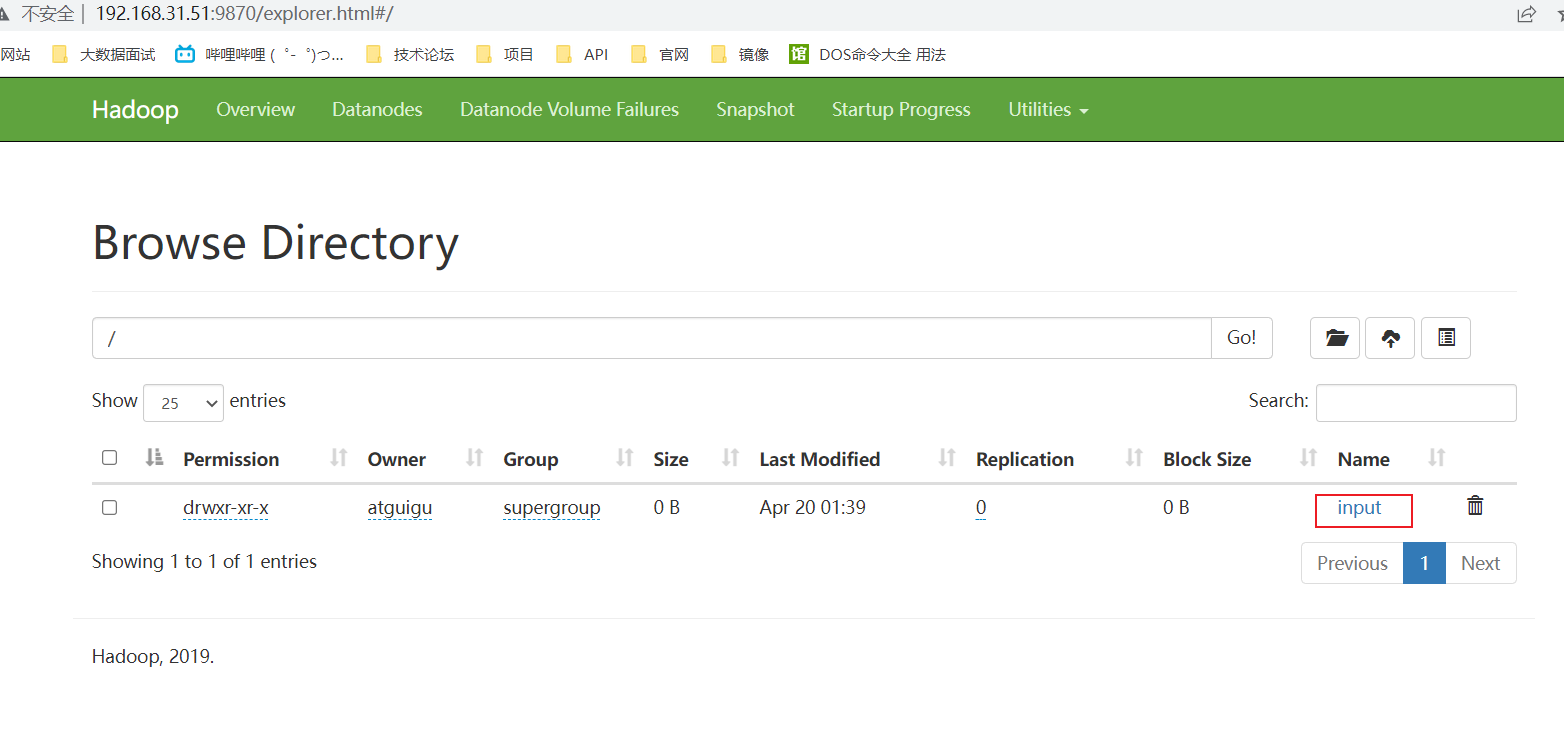
对于linux来说 input目录是一个虚拟的,不是真实存在的,在系统的硬盘中是找不到的,但对hdfs说是真实存在的,但从本质上来说,input保存在linux系统中
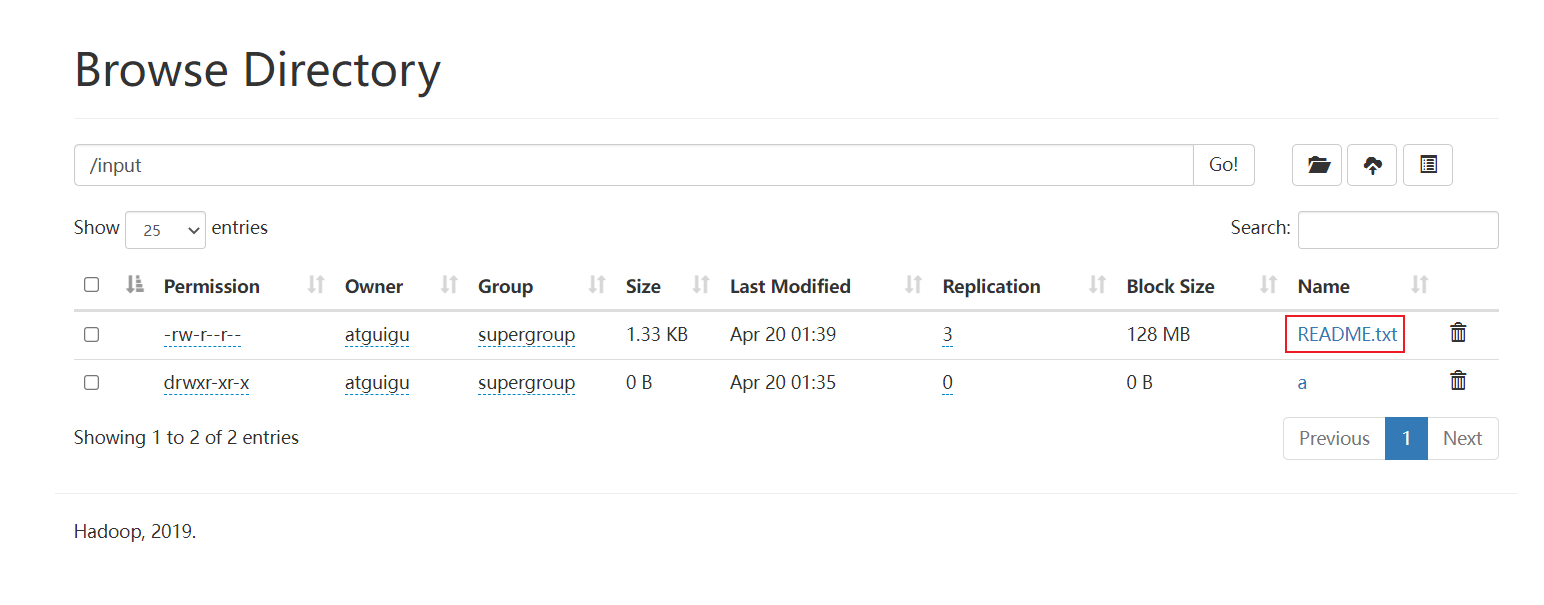
Permission: 文件的权限
Ownger: 所属用户
Group: 所属组
Size: 文件大小
Last Modified: 最后修改时间
Replication: 副本数
Block Size: 块大小,默认是128M
Name: 文件名字
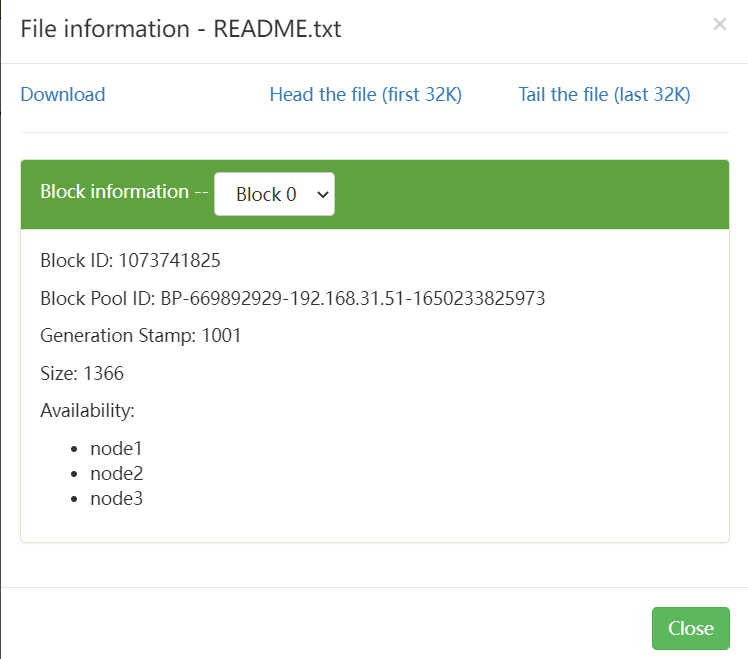
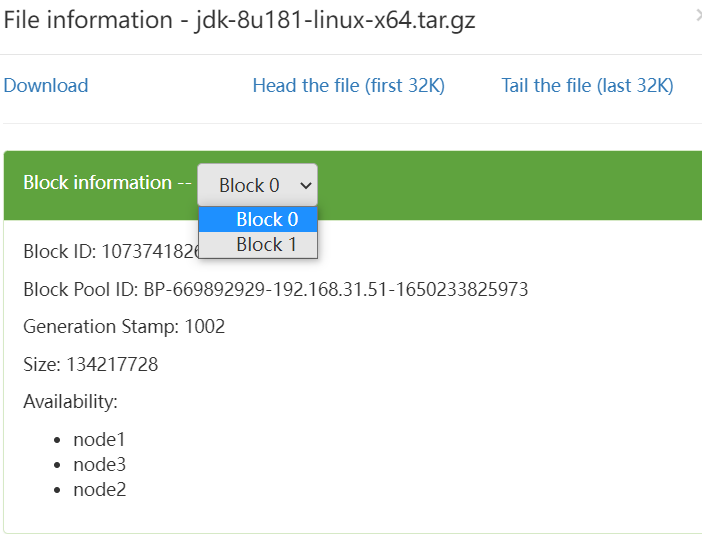
Block information: 块信息
Block ID: 块的编号
Block Pool ID: 块所在的池的id
Generation Stamp:
Size: 块
Availability: 文件被分成多份,保存的节点位置
- 在Linux上的具体位置
/opt/module/hadoop-3.1.3/data/data/current/BP-669892929-192.168.31.51-1650233825973/current/finalized/subdir0/subdir0

blk_1073741825: 文件所分成的块,保存的是真实的文件内容
blk_1073741825_1001.meta: 文件的校验和,保存的是一些校验信息
块的元数据都在namenode节点上维护
namenode通过元数据信息,能够找到指定的块
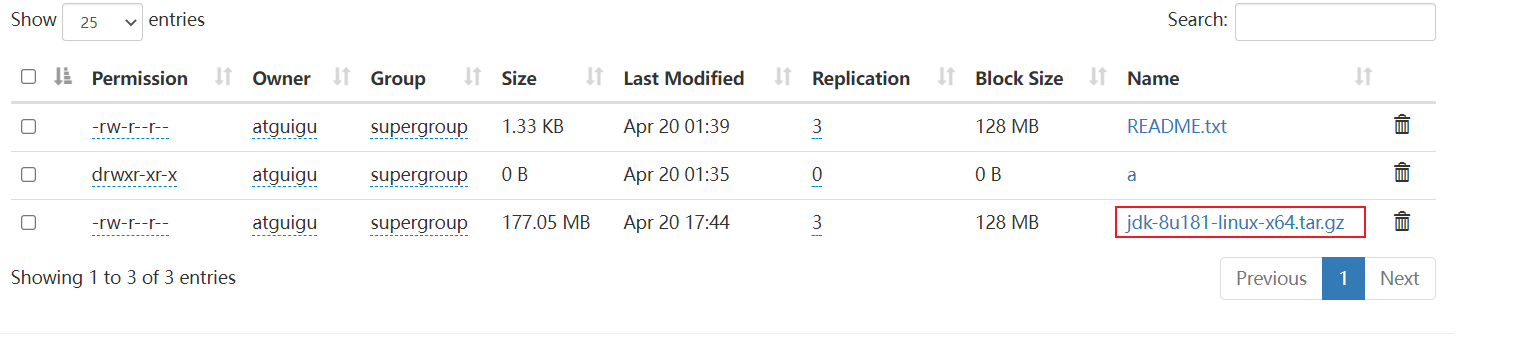
- 上传大文件
hadoop fs -put jdk-8u181-linux-x64.tar.gz /input
上传文件超过块的大小,文件被分成2个块,在三个节点上保存
为什么三台机器上都有?
因为设置的副本是3份,并且只有三台机器(application=3)
每台机器只能保存1个副本,文件在hdfs上以块的形式进行存储,块的多少取决于你的文件大小以及你设置的块的大小,默认块的大小为128M
- 总结
1. 在hdfs中创建目录
hadoop fs -mkdir -p /a/b
2. 上传文件到hadfs上
hadoop fs -put /a/aa.txt
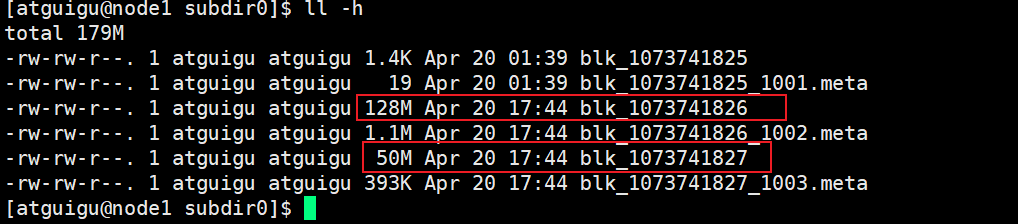
3. 查看DataNode存储的数据
路径:opt/module/hadoop-3.1.3/data/data/current/BP-669892929-192.168.31.51-1650233825973/curr
ent/finalized/subdir0/subdir0
查看内容:
-rw-rw-r--. 1 atguigu atguigu 1.4K Apr 20 01:39 blk_1073741825
-rw-rw-r--. 1 atguigu atguigu 19 Apr 20 01:39 blk_1073741825_1001.meta
-rw-rw-r--. 1 atguigu atguigu 128M Apr 20 17:44 blk_1073741826
-rw-rw-r--. 1 atguigu atguigu 1.1M Apr 20 17:44 blk_1073741826_1002.meta
-rw-rw-r--. 1 atguigu atguigu 50M Apr 20 17:44 blk_1073741827
-rw-rw-r--. 1 atguigu atguigu 393K Apr 20 17:44 blk_1073741827_1003.meta
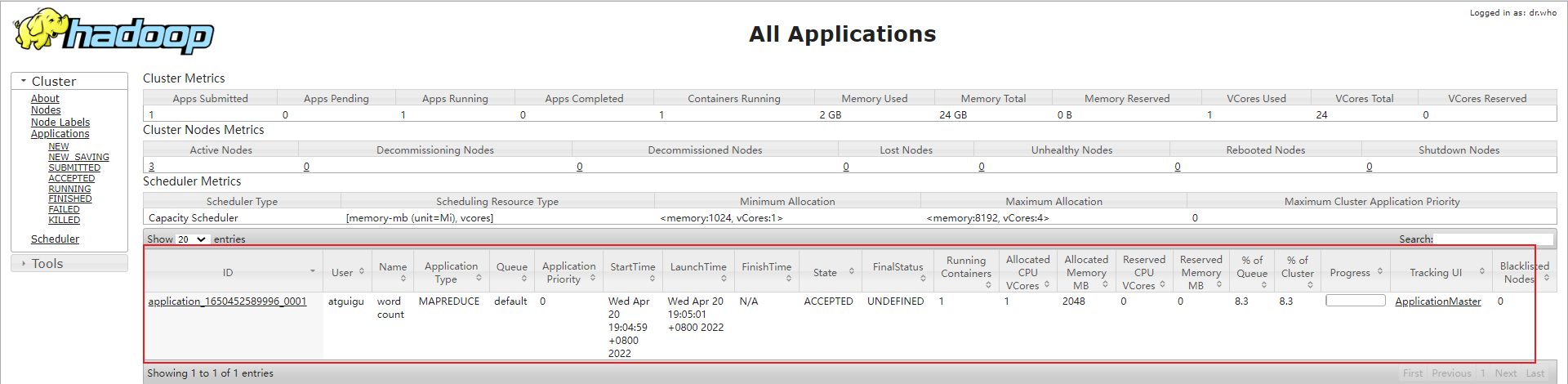
在yarn上执行wordcount程序
# 在hdfs上建立目录
hadoop fs -mkdir /wcinput
# 把本地的文件上传的hdfs
hadoop fs -put wcinput/test.input /wcinput
# 执行wordcount案例
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount hdfs://node1:8020/wcinput /wcoutput
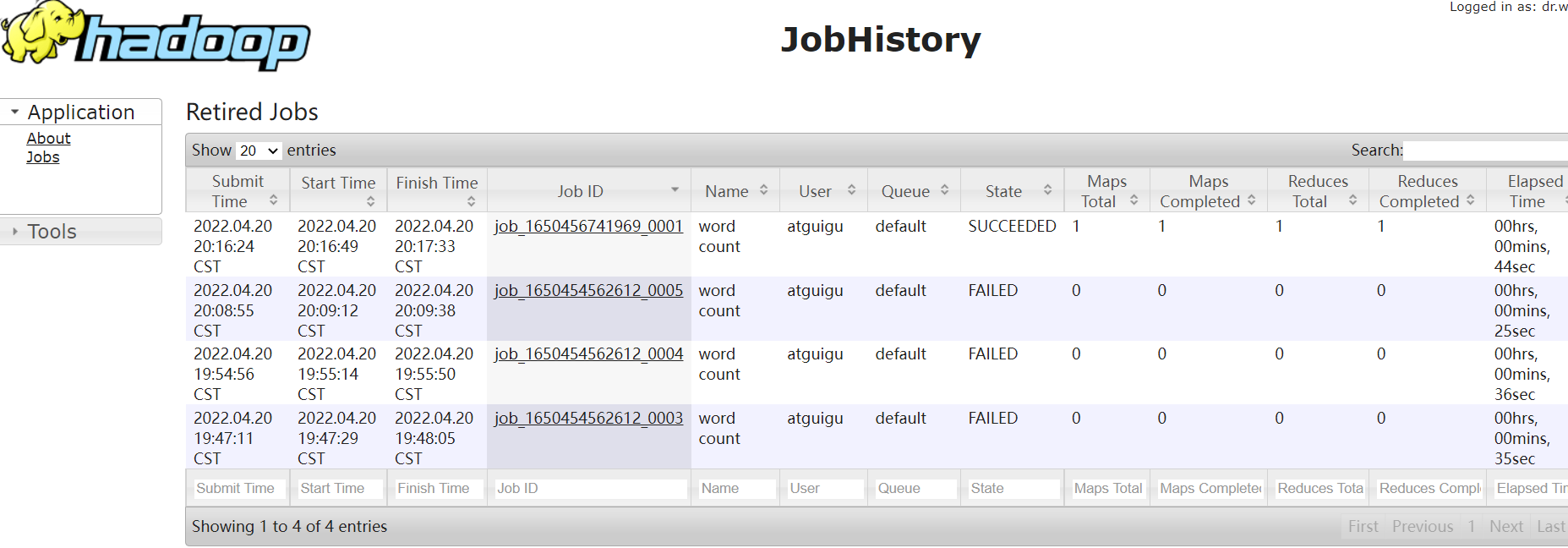
配置历史服务器
为了查看程序的历史运行情况,需要配置
把运行过的job保存到历史服务器上
- 配置mapred-site.xml
历史服务器端地址
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
历史服务器web端地址
<property>
<name>mapreduce.jobhistory.webapp.addres</name>
<value>node1:19888</value>
</property>
- 启动历史服务器
mapred --daemon start historyserver
- 通过web界面访问 192.168.31.51:19888
配置日志的聚集
日志聚集概念:应用运行完成以后,将程序的日志在web上面显示
- 配置yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- web查看日志的路径-->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 日志存储的时间,604800秒=7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800 </value>
</property>
- 打开历史服务器
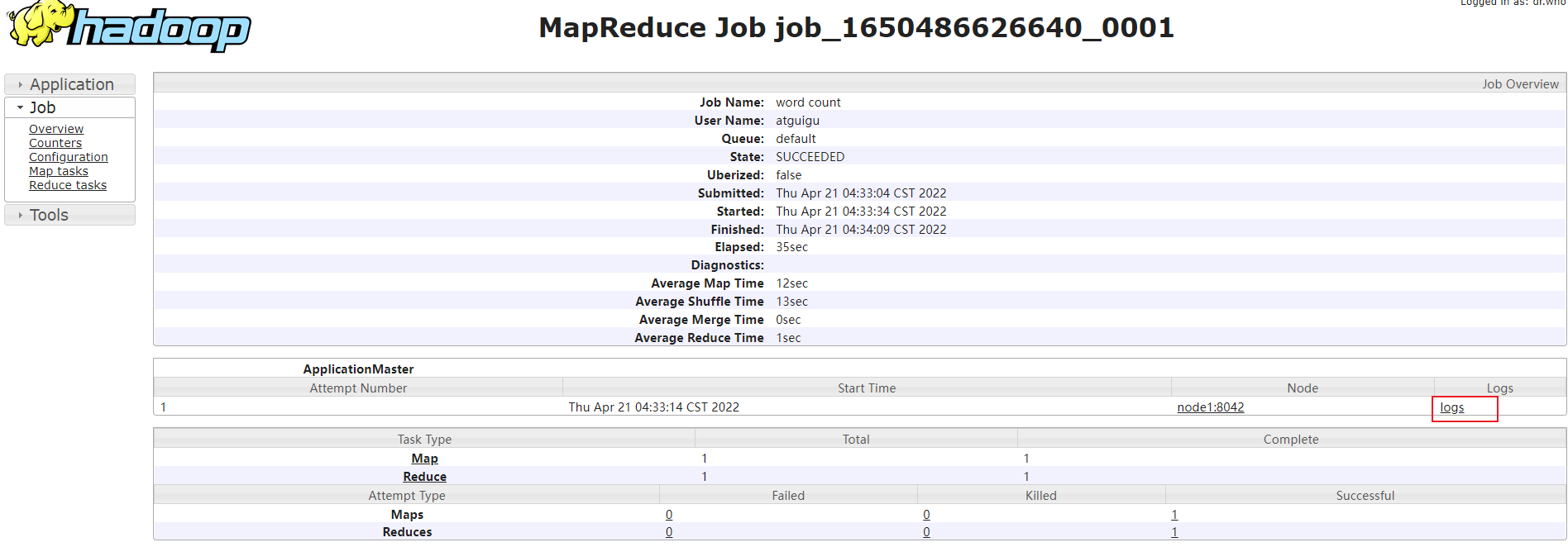
job的启动日志
集群的时间同步
时间同步的方式:找一台机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步。
为什么要做时间同步?
因为对应多台机器,在每台机器上做定时任务,如果时间不同步,可能有的机器在定时的时间不会去执行。
时间同步,要求时间正确码?
只要多台机器的时间保持一致,不要求时间必须是正确的。
HBASE约定每台机器的时间不能差30秒
- 安装ntp
- 修改ntp配置文件
在node1上修改ntp的配置文件(设置node1为时间服务器)
vim /etc/ntp.conf
修改内容:
1. 授权192.168.1.0~192.168.255.255网段上的所有机器可以从这台机器上查询和同步时间
17 #restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
把注释去掉
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
2. 21 server 0.centos.pool.ntp.org iburst
22 server 1.centos.pool.ntp.org iburst
23 server 2.centos.pool.ntp.org iburst
24 server 3.centos.pool.ntp.org iburst
全部注释掉
3. 添加以下内容
server 127.127.1.0
fudge 127.127.1.0 stratum 10
- 修改ntpd文件
vim /etc/sysconfig/ntpd
修改内容
添加内容:(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
硬件时间:bios所维护的一个时间
系统时间:操作系统的时间
- 重新启动ntp服务
sudo systenctl restart ntpd
- 设置为开机自启
sudo systemctl enable ntpd
- 创建时间同步脚本
sudo crontab -e
*/1 * * * * /usr/bin/ntpdate node1
hadoop相关端口号
1. NameNode内部通信端口: 8020
2. NameNode的web端端口: 9870
3. SecondaryNameNode端口号: 9868
4. Yarn(ResourceManager)的web端端口: 8088
5. 历史服务器web端端口: 19888
hadoop2.x与hadoop3.x的区别
1. java的最低支持从java7升到了java8
2. 引入纠删码(Erasure Coding)
3. 重写了Shell脚本
4. 支持超过两个NN,2版本支持2个,3版本可以支持n个
5. 默认端口的改变
......
hadoop原码编译
怎么编译hadoop原码?
为什么取编译hadoop原码?
当我们使用的hadoop框架时,框架与框架之间有兼容问题,hadoop、hive、flink..等框架兼容性不是很好,就自己进行编译,就把相应对应的原码加入进去,然后进行编译,可以更好的去使用hadoop框架。
其他
hdfs保存的文件放到在哪里?
hadoop保存的文件本质上还是在linux系统的磁盘上
hdfs会把磁盘按照自己的方式做一个规划,然后进行管理(如何规划?如何管理?)
如果有4台机器,设置副本为3个,怎么存?
对于现在来说,是随机存储的
在真实环境中会有个 机架,机架感知,通过这个进行文件的副本保存
报错:hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount hdfs://node1:8020/wcinput /wcoutput
[atguigu@node1 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinp
ut /wcoutput2022-04-20 19:37:55,809 INFO client.RMProxy: Connecting to ResourceManager at node2/192.168.31.52:8032
2022-04-20 19:37:58,059 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/stag
ing/atguigu/.staging/job_1650454562612_00012022-04-20 19:37:58,514 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, rem
oteHostTrusted = false2022-04-20 19:38:00,029 INFO input.FileInputFormat: Total input files to process : 1
2022-04-20 19:38:00,160 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, rem
oteHostTrusted = false2022-04-20 19:38:00,310 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, rem
oteHostTrusted = false2022-04-20 19:38:00,404 INFO mapreduce.JobSubmitter: number of splits:1
2022-04-20 19:38:00,912 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, rem
oteHostTrusted = false2022-04-20 19:38:01,069 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1650454562612_0001
2022-04-20 19:38:01,070 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-04-20 19:38:01,665 INFO conf.Configuration: resource-types.xml not found
2022-04-20 19:38:01,665 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-04-20 19:38:02,640 INFO impl.YarnClientImpl: Submitted application application_1650454562612_0001
2022-04-20 19:38:02,747 INFO mapreduce.Job: The url to track the job: http://node2:8088/proxy/application_1650454562
612_0001/2022-04-20 19:38:02,748 INFO mapreduce.Job: Running job: job_1650454562612_0001
2022-04-20 19:38:13,093 INFO mapreduce.Job: Job job_1650454562612_0001 running in uber mode : false
2022-04-20 19:38:13,095 INFO mapreduce.Job: map 0% reduce 0%
2022-04-20 19:38:13,148 INFO mapreduce.Job: Job job_1650454562612_0001 failed with state FAILED due to: Application
application_1650454562612_0001 failed 2 times due to AM Container for appattempt_1650454562612_0001_000002 exited with exitCode: 1Failing this attempt.Diagnostics: [2022-04-20 19:38:12.559]Exception from container-launch.
Container id: container_1650454562612_0001_02_000001
Exit code: 1
[2022-04-20 19:38:12.788]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
[2022-04-20 19:38:12.789]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
For more detailed output, check the application tracking page: http://node2:8088/cluster/app/application_16504545626
12_0001 Then click on links to logs of each attempt.. Failing the application.
2022-04-20 19:38:13,196 INFO mapreduce.Job: Counters: 0
[atguigu@node1 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount hdfs:/
/node1:8020/wcinput /wcoutput2022-04-20 19:40:18,962 INFO client.RMProxy: Connecting to ResourceManager at node2/192.168.31.52:8032
2022-04-20 19:40:21,771 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/stag
ing/atguigu/.staging/job_1650454562612_00022022-04-20 19:40:22,213 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, rem
oteHostTrusted = false2022-04-20 19:40:22,717 INFO input.FileInputFormat: Total input files to process : 1
2022-04-20 19:40:22,819 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, rem
oteHostTrusted = false2022-04-20 19:40:22,915 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, rem
oteHostTrusted = false2022-04-20 19:40:23,006 INFO mapreduce.JobSubmitter: number of splits:1
2022-04-20 19:40:23,582 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, rem
oteHostTrusted = false2022-04-20 19:40:23,755 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1650454562612_0002
2022-04-20 19:40:23,755 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-04-20 19:40:24,679 INFO conf.Configuration: resource-types.xml not found
2022-04-20 19:40:24,680 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-04-20 19:40:24,962 INFO impl.YarnClientImpl: Submitted application application_1650454562612_0002
2022-04-20 19:40:25,268 INFO mapreduce.Job: The url to track the job: http://node2:8088/proxy/application_1650454562
612_0002/2022-04-20 19:40:25,271 INFO mapreduce.Job: Running job: job_1650454562612_0002
2022-04-20 19:40:32,578 INFO mapreduce.Job: Job job_1650454562612_0002 running in uber mode : false
2022-04-20 19:40:32,580 INFO mapreduce.Job: map 0% reduce 0%
2022-04-20 19:40:32,608 INFO mapreduce.Job: Job job_1650454562612_0002 failed with state FAILED due to: Application
application_1650454562612_0002 failed 2 times due to AM Container for appattempt_1650454562612_0002_000002 exited with exitCode: 1Failing this attempt.Diagnostics: [2022-04-20 19:40:32.362]Exception from container-launch.
Container id: container_1650454562612_0002_02_000001
Exit code: 1
[2022-04-20 19:40:32.368]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
[2022-04-20 19:40:32.368]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
For more detailed output, check the application tracking page: http://node2:8088/cluster/app/application_16504545626
12_0002 Then click on links to logs of each attempt.. Failing the application.
- 原因
不知道
- 解决方法
在mapred-site.xml添加以下
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
报错:hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount hdfs://node1:8020/wcinput /wcoutput
2022-04-20 19:54:52,158 INFO client.RMProxy: Connecting to ResourceManager at node2/192.168.31.52:8032
2022-04-20 19:54:54,306 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/atguigu/.staging
/job_1650454562612_00042022-04-20 19:54:54,688 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = fal
se2022-04-20 19:54:55,086 INFO input.FileInputFormat: Total input files to process : 1
2022-04-20 19:54:55,164 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = fal
se2022-04-20 19:54:55,244 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = fal
se2022-04-20 19:54:55,296 INFO mapreduce.JobSubmitter: number of splits:1
2022-04-20 19:54:55,759 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = fal
se2022-04-20 19:54:55,898 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1650454562612_0004
2022-04-20 19:54:55,899 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-04-20 19:54:56,531 INFO conf.Configuration: resource-types.xml not found
2022-04-20 19:54:56,532 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-04-20 19:54:56,717 INFO impl.YarnClientImpl: Submitted application application_1650454562612_0004
2022-04-20 19:54:56,827 INFO mapreduce.Job: The url to track the job: http://node2:8088/proxy/application_1650454562612_0004/
2022-04-20 19:54:56,828 INFO mapreduce.Job: Running job: job_1650454562612_0004
2022-04-20 19:55:15,551 INFO mapreduce.Job: Job job_1650454562612_0004 running in uber mode : false
2022-04-20 19:55:15,553 INFO mapreduce.Job: map 0% reduce 0%
2022-04-20 19:55:24,178 INFO mapreduce.Job: Task Id : attempt_1650454562612_0004_m_000000_0, Status : FAILED
[2022-04-20 19:55:23.030]Container [pid=13759,containerID=container_1650454562612_0004_01_000002] is running 462010880B beyond the 'VIRT
UAL' memory limit. Current usage: 77.8 MB of 1 GB physical memory used; 2.5 GB of 2.1 GB virtual memory used. Killing container.Dump of the process-tree for container_1650454562612_0004_01_000002 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LIN
E |- 13769 13759 13759 13759 (java) 419 89 2600972288 19603 /opt/module/jdk1.8.0_181/bin/java -Djava.net.preferIPv4Stack=true -Dha
doop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/tmp/hadoop-atguigu/nm-local-dir/usercache/atguigu/appcache/application_1650454562612_0004/container_1650454562612_0004_01_000002/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/module/hadoop-3.1.3/logs/userlogs/application_1650454562612_0004/container_1650454562612_0004_01_000002 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.31.52 37853 attempt_1650454562612_0004_m_000000_0 2 |- 13759 13758 13759 13759 (bash) 0 0 115896320 305 /bin/bash -c /opt/module/jdk1.8.0_181/bin/java -Djava.net.preferIPv4Stack=tr
ue -Dhadoop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/tmp/hadoop-atguigu/nm-local-dir/usercache/atguigu/appcache/application_1650454562612_0004/container_1650454562612_0004_01_000002/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/module/hadoop-3.1.3/logs/userlogs/application_1650454562612_0004/container_1650454562612_0004_01_000002 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.31.52 37853 attempt_1650454562612_0004_m_000000_0 2 1>/opt/module/hadoop-3.1.3/logs/userlogs/application_1650454562612_0004/container_1650454562612_0004_01_000002/stdout 2>/opt/module/hadoop-3.1.3/logs/userlogs/application_1650454562612_0004/container_1650454562612_0004_01_000002/stderr
[2022-04-20 19:55:23.253]Container killed on request. Exit code is 143
[2022-04-20 19:55:23.278]Container exited with a non-zero exit code 143.
2022-04-20 19:55:33,342 INFO mapreduce.Job: Task Id : attempt_1650454562612_0004_m_000000_1, Status : FAILED
[2022-04-20 19:55:31.060]Container [pid=9869,containerID=container_1650454562612_0004_01_000003] is running 462010880B beyond the 'VIRTU
AL' memory limit. Current usage: 79.4 MB of 1 GB physical memory used; 2.5 GB of 2.1 GB virtual memory used. Killing container.Dump of the process-tree for container_1650454562612_0004_01_000003 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LIN
E |- 9869 9868 9869 9869 (bash) 3 1 115896320 306 /bin/bash -c /opt/module/jdk1.8.0_181/bin/java -Djava.net.preferIPv4Stack=true -
Dhadoop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/tmp/hadoop-atguigu/nm-local-dir/usercache/atguigu/appcache/application_1650454562612_0004/container_1650454562612_0004_01_000003/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/module/hadoop-3.1.3/logs/userlogs/application_1650454562612_0004/container_1650454562612_0004_01_000003 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.31.52 37853 attempt_1650454562612_0004_m_000000_1 3 1>/opt/module/hadoop-3.1.3/logs/userlogs/application_1650454562612_0004/container_1650454562612_0004_01_000003/stdout 2>/opt/module/hadoop-3.1.3/logs/userlogs/application_1650454562612_0004/container_1650454562612_0004_01_000003/stderr |- 9879 9869 9869 9869 (java) 434 78 2600972288 20012 /opt/module/jdk1.8.0_181/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop
.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/tmp/hadoop-atguigu/nm-local-dir/usercache/atguigu/appcache/application_1650454562612_0004/container_1650454562612_0004_01_000003/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/module/hadoop-3.1.3/logs/userlogs/application_1650454562612_0004/container_1650454562612_0004_01_000003 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.31.52 37853 attempt_1650454562612_0004_m_000000_1 3
[2022-04-20 19:55:31.246]Container killed on request. Exit code is 143
[2022-04-20 19:55:31.258]Container exited with a non-zero exit code 143.
2022-04-20 19:55:42,459 INFO mapreduce.Job: Task Id : attempt_1650454562612_0004_m_000000_2, Status : FAILED
[2022-04-20 19:55:40.188]Container [pid=9911,containerID=container_1650454562612_0004_01_000004] is running 465160704B beyond the 'VIRTU
AL' memory limit. Current usage: 86.2 MB of 1 GB physical memory used; 2.5 GB of 2.1 GB virtual memory used. Killing container.Dump of the process-tree for container_1650454562612_0004_01_000004 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LIN
E |- 9921 9911 9911 9911 (java) 559 37 2604122112 21767 /opt/module/jdk1.8.0_181/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop
.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/tmp/hadoop-atguigu/nm-local-dir/usercache/atguigu/appcache/application_1650454562612_0004/container_1650454562612_0004_01_000004/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/module/hadoop-3.1.3/logs/userlogs/application_1650454562612_0004/container_1650454562612_0004_01_000004 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.31.52 37853 attempt_1650454562612_0004_m_000000_2 4 |- 9911 9910 9911 9911 (bash) 0 0 115896320 306 /bin/bash -c /opt/module/jdk1.8.0_181/bin/java -Djava.net.preferIPv4Stack=true -
Dhadoop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/tmp/hadoop-atguigu/nm-local-dir/usercache/atguigu/appcache/application_1650454562612_0004/container_1650454562612_0004_01_000004/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/module/hadoop-3.1.3/logs/userlogs/application_1650454562612_0004/container_1650454562612_0004_01_000004 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.31.52 37853 attempt_1650454562612_0004_m_000000_2 4 1>/opt/module/hadoop-3.1.3/logs/userlogs/application_1650454562612_0004/container_1650454562612_0004_01_000004/stdout 2>/opt/module/hadoop-3.1.3/logs/userlogs/application_1650454562612_0004/container_1650454562612_0004_01_000004/stderr
[2022-04-20 19:55:40.465]Container killed on request. Exit code is 143
[2022-04-20 19:55:40.471]Container exited with a non-zero exit code 143.
2022-04-20 19:55:52,761 INFO mapreduce.Job: map 100% reduce 100%
2022-04-20 19:55:52,789 INFO mapreduce.Job: Job job_1650454562612_0004 failed with state FAILED due to: Task failed task_1650454562612_0
004_m_000000Job failed as tasks failed. failedMaps:1 failedReduces:0 killedMaps:0 killedReduces: 0
2022-04-20 19:55:53,015 INFO mapreduce.Job: Counters: 13
Job Counters
Failed map tasks=4
Killed reduce tasks=1
Launched map tasks=4
Other local map tasks=3
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=27220
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=27220
Total vcore-milliseconds taken by all map tasks=27220
Total megabyte-milliseconds taken by all map tasks=27873280
Map-Reduce Framework
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
- 原因:
Container [pid=13759,containerID=container_1650454562612_0004_01_000002] is running 462010880B beyond the 'VIRTUAL' memory limit. Current usage: 77.8 MB of 1 GB physical memory used; 2.5 GB of 2.1 GB virtual memory used. Killing container.Dump of the process-tree for container_1650454562612_0004_01_000002 :
Container[pid=13759,containerID=Container_1650454562612_0004_01_000002]正在超出“虚拟”内存限制运行462010880B。当前使用情况:使用77.8 MB的1 GB物理内存;使用2.5 GB的2.1 GB虚拟内存。正在为了 container_1650454562612_0004_01_000002 杀死 进程树 中的 container.Dump
mapreduce 进行计算所需要的内存不足
- 解决方法
在 mapred-site.xml文件中,配置下面的配置项
取消虚拟内存的限制
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号