
day32-s-hadoop
day32-s-hadoop
hadoop
启动hadoop集群
hadoop提供的启动hdfs、yarn的脚本
hdfs-start.sh 启动namenode datanode secondarynode
yarn-start.sh 启动resourcemanager nodemanager
问题:这些节点分布在不同的机器上,怎么能够正确的启动对应机器的节点?
workers 可以决定在那个节点启动namenode datanode secondarynamenode
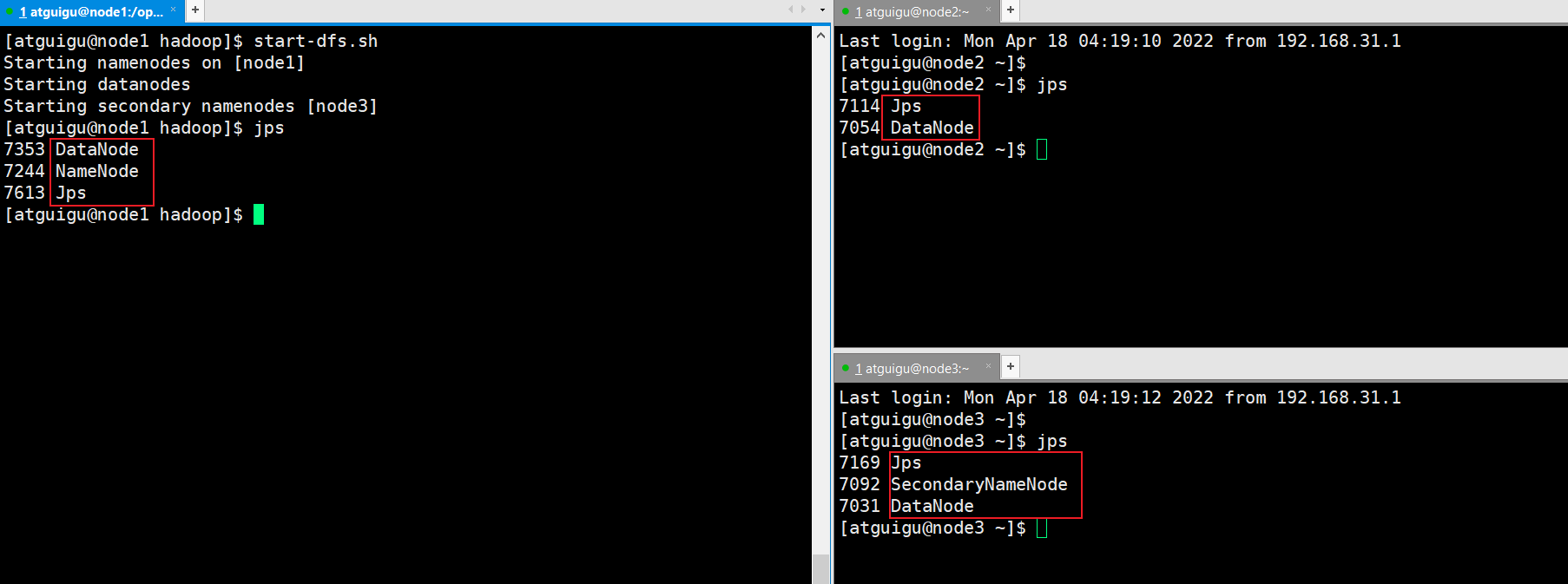
- 启动hdfs
start-dfs.sh
- 启动yarn
yarn的启动,必须在resourcemanager的节点上启动
start-yarn.sh
- 关闭集群
stop-yarn.sh 在resourcemanager所在的机器上关闭
stop-dfs.sh 在namenode所在的机器上关闭
总结:集群的启动/停止方式
单点启动/停止:
hdfs --daemon start/stop namenode secondarynamenode datanode
yarn --daemon start/stop resourcemanager nodemanager
群起/群停
前提:配置ssh免密登录,配置workers文件(hadoop2.x中是slaver文件)
在namdnode节点: start-dfs.sh / stop-dfs.sh
在resourcemanager节点: start-yarn.sh / stop-yarn.sh
编写集群的管理脚本
- 集群的启动和停止脚本
mycluster.sh start / stop
#!/bin/bash
if [ $# -lt 1 ]
then
echo "Input Arguments Error!!!"
exit
fi
case $1 in
start)
echo "====START HDFS===="
start-dfs.sh
ssh node1 start-dfs.sh
echo "====START YARN===="
ssh node2 start-yarn.sh
;;
stop)
echo "====STOP HDFS===="
start-dfs.sh
ssh node1 stop-dfs.sh
echo "====STOP YARN===="
ssh node2 stop-yarn.sh
;;
*)
echo "arguments error!!!"
echo "your input:$1"
;;
esac
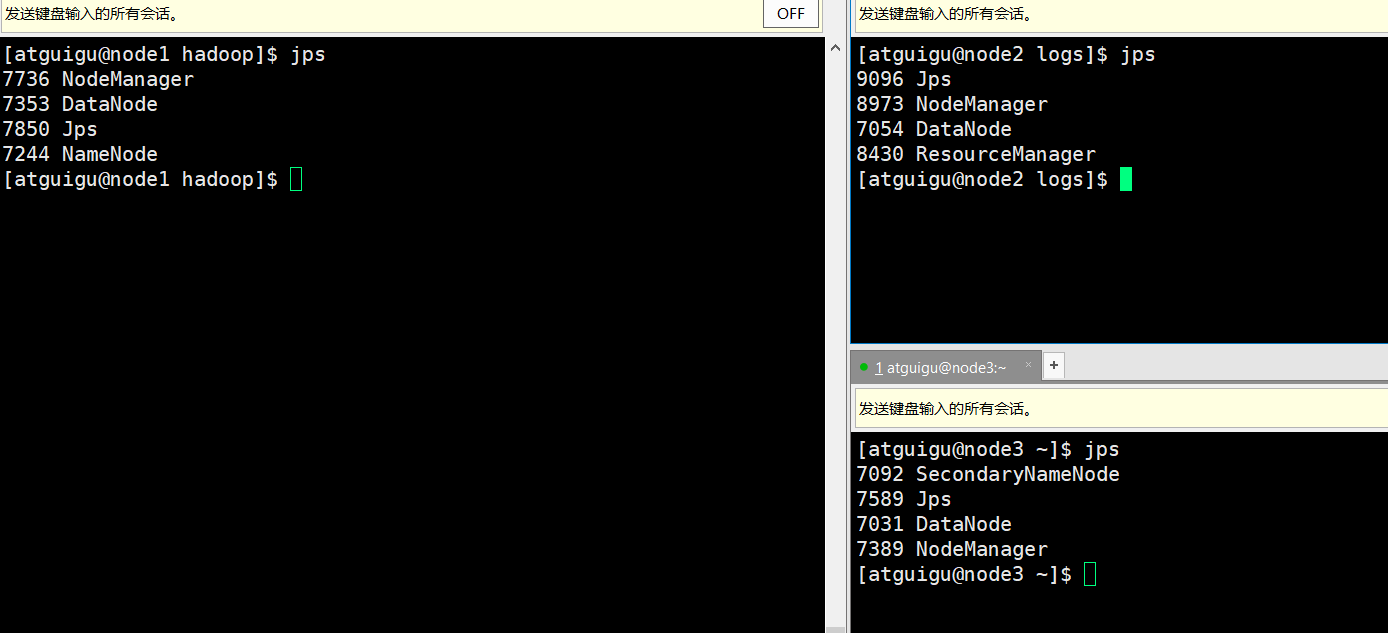
- 查看进程中各个机器进程的脚本 myjps.sh
#!/bin/bash
for node in node1 node2 node3
do
echo "==== $node JPS ===="
ssh $node jps
dnoe
HDFS是怎么存数据的
hdfs所管理的磁盘在哪里?
HDFS 以自己的方式对磁盘进行管理
数据存到了 每个节点配置的 节点保存文职
hadoop的命令使用
hadoop fs -mkdir -p /input/a/c
创建的文件可以从web页面找到,但不能从linux也就是磁盘中找到
没有在linux文件系统中创建这个目录,所以没有办法找到
可以理解为一个虚拟的目录,但对于hdfs来说是真实存在的
集群基本测试
上传文件到集群
- 上传小文件
hadoop fs -put README.txt /input
把本地的一个文件上传到hadoop的hdfs中

在web界面显示
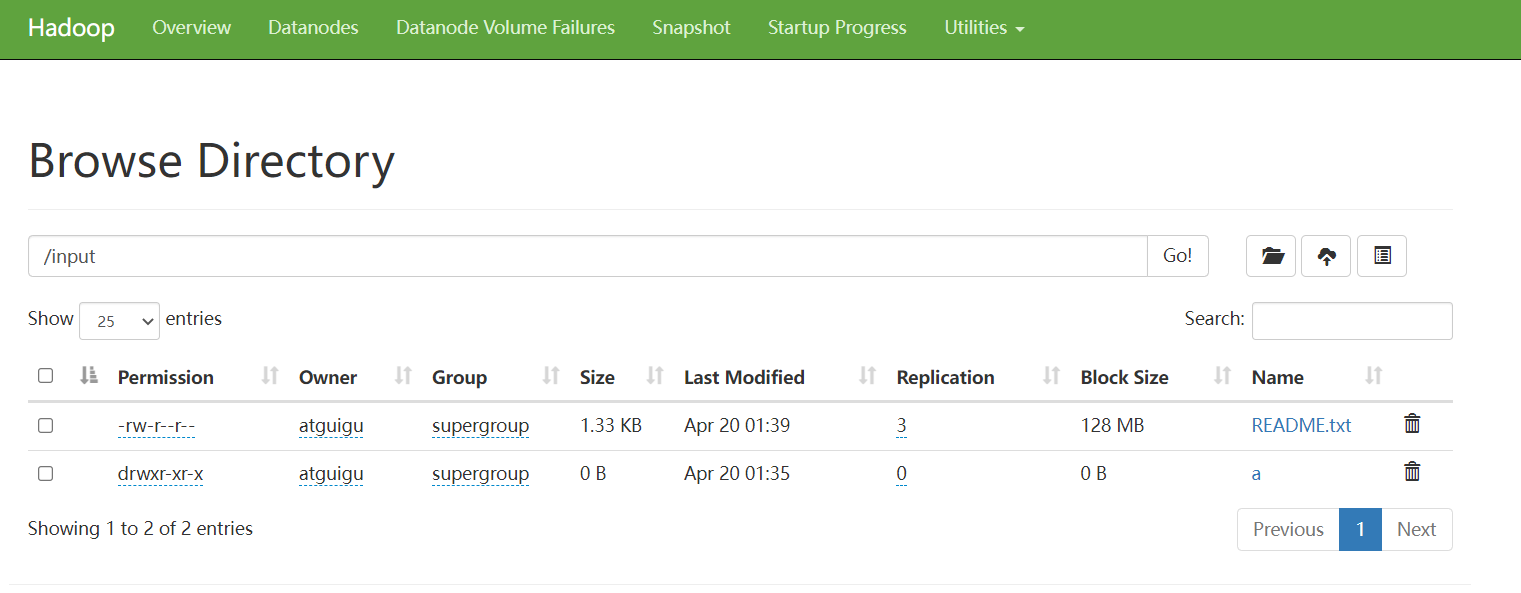
副本为3份,所以会存在不同的机器上
存在的位置:
/opt/module/hadoop-3.1.3/data/data/current/BP-669892929-192.168.31.51-1650233825
973/current/finalized/subdir0/subdir0
- 上传大文件
其他
启动yarn的时候,resourcemanager启动成功,nodemannager启动失败?
[atguigu@node2 logs]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
node1: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
node3: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
node2: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
原因:没有配置ssh免密登录
注意:自己也需要给自己配免密登录
hadoop2与hadoop3的workers有区别
名字不一样:
hadoop2.x:salvers
hadoop3.x:workers
shell 脚本中的switch-case
格式:
case 值 in
value1)
command1
;;
value2)
command2
;;
*) # 其他
command3
;;
esac
jps
[atguigu@node1 bin]$ jps
11458 Jps
10627 DataNode
10507 NameNode
11324 NodeManager
[atguigu@node1 bin]$ jps -l
10627 org.apache.hadoop.hdfs.server.datanode.DataNode
11447 sun.tools.jps.Jps
10507 org.apache.hadoop.hdfs.server.namenode.NameNode
11324 org.apache.hadoop.yarn.server.nodemanager.NodeManager
jps查询的名字是 程序的类名
hadoop提供的类,启动之后,程序就不会停止。
java double精度丢失问题?
double与float为啥为丢失精度?BigDecimal怎么解决精度问题的?
- 浮点数是什么?
浮点数是计算机用来表示小数的一种数据类型,采用科学技术法。
double:双精度,64位,浮点数,默认是0.0d。
float是单精度,32位,浮点数,默认是0.0df
- 在内存中存储?

float 符号位1bit 指数8bit 尾数23bit
double 符号位1bit 指数11bit 尾数52bit
- 科学计数法
十进制科学计数法要求有效数字的整数部分必须在[1,9]区间内
光速:300000000米/秒~3*10^8~3E8
全世界人口:61000000000~6.1*10^9~6.1E9
- 精度丢失
计算机在处理数据都涉及到数据的转换和各种复杂的运算。
比如:不同单位换算,不同进制换算。很多除法不能除尽,比如10÷3=3.33333...无穷无尽,而精度是有限的,3.3333...×3并不等于10,经过复杂的处理后得到的十进制数据并不精确,精度越高越精确。
float和double的精度是由尾数的位数来决定的,其整数部分始终是一个隐含着的 1 ,由于它是不变的,故不能对精度造成影响。
float: 2^23=8388608,一共七位,由于最左边为1的一位省略了,着意味着最多能表示8位数:28388608=16777216.
有8位有效数字,但绝对能保证的为7位,也即float的精度为7~8位有效数字;
double:2^52=4503599627370496,一共16位,同理,double的精度位16~17位
当到大一定值自动开始使用科学计数法,并保留相关精度的有效数字,所以结果是个近似数。在十进制中小数有些是无法完整用二进制表示的。所以只能用有限位来表示,从而在存储时可能就会有误差。
double类型 0.3-0.1的情况
0.3*2=0.6 => .0(.6) 取0剩0.6
0.6*2=1.2 => .01(.2) 取1剩0.2
0.2*2=0.4 => .010(.4) 取0剩0.4
0.4*2=0.8 => .0100(.8) 取0剩0.8
0.8*2=1.6 => .01001(.6) 取1剩0.6
......
double的问题是从小数点转换到二进制丢失精度,二进制丢失精度。
当浮点数达到一定的大数时自动使用科学技术法,这样表示只是近似真实数而不等于真实数。
- BigDecimal
BigDecimal是不可变的,可以用来表示任意精度的带符号十进制数。BigDecimal在处理的时候把十进制小数扩大N倍让它在整数上进行计算,并保留相应的精度信息。
- 总结
1 商业计算使用BigDecimal
2 BigDecimal都是不可变的(immutable)的,在进行每一步运算时,都会产生一个新的对象,所以在做加减乘除运算时千万要保留操作后的值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号