
day30-s-hadoop
day30-s-hadoop
hadoop
hadoop运行模式
本机模式(单机模式)、伪分布式模式、完全分布式模式
本机模式
官方 wordcount 案例
统计输入文件中每个单词出现的次数
- 创建一个wcinput的文件
cd hadoop
mkdir wcinput
- 创建数据
cd wcinput
vim test.input
- 运行hadoop案例
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput
hadoop: 命令
jar: 运行jar包
share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar: jar包所在路径
wordcount: 案例名称
wcinput: 数据输入文件
wcoutput: 结果输出文件
- 查看结果
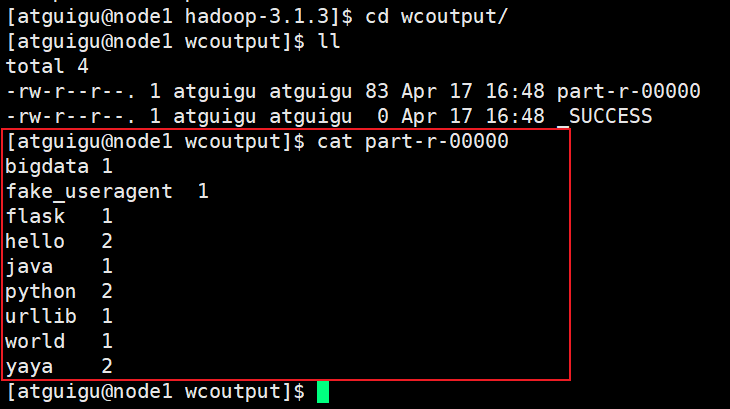
伪分布式模式
在一台机器里面搭建hadoop
完全分布式模式
- 准备
0. 准备3台客户机(关闭防火墙、静态ip、主机名称)
1. 安装jdk
2. 配置环境变量
3. 安装hadoop
4. 配置环境变量
5. 配置集群
6. 单点启动
7. 配置ssh
8. 群起并测试集群
- 编写集群分发脚本xsync
scp(secure copy)安全拷贝
scp定义:
scp可以实现服务器与服务器之间的数据拷贝
基本语法
scp -r $pdir$fname $user@hadoop$host:$pdir/$fname
命令 递归 要拷贝的文件 用户 @主机:目的路径/文件
rsync远程同步工具
rsync定义(差异性复制)
主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号连接的优点。
基本语法:
rsync -av $dir/$filename $user@$host:$dir/filename
-a 归档拷贝
-v 显示复制过程
需要安装:
yum install rsync -y
编写发送文件的脚本
#!/bin/bash
# 判断参数的格式
if [ $# -lt 1 ]
then
echo "not enough argument"
exit
fi
# 遍历集群中所有的机器
for host in node1 node2 node3
do
# 遍历所有的目录,挨个发送
for file in $@
do
# 判断文件是否村子
if [ -e $file ]
then
# 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
# 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo "$file does not exists!"
fi
done
done
集群配置
集群规划
- 理论规划
1. HDFS: Namenode Datanode SecondaryNamenode
2. Yarn: ResourceManager NodeManager
3. Namenode secondaryNamenode ResourceManger 对资源的需求比较大,因该把它们三个分布到不同的机器中
4. 按照hadoop官方默认的3个副本来说,最少需要3个DataNode节点,也就是3台机器
5. NodeManager主要管理的是DataNode机器的资源,因此NodeManager和DataNode搭建到一起(有dn的地方就有nm)
- 实际规划(实际上只有三台机器)
有三台机器:
node1: DataNode NodeManager NameNode
node2: DataNode NodeManager ResourceManager
node3: DataNode NodeManager SecondaryNamenode
普通集群:只有一个NameNode
| node1 | node2 | node3 | |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager |
NodeManger |
- 配置文件说明
Hadoop配置文件分为两类:默认配置文件和自定义配置文件,只有用户想修改配置文件,就修改自定义文件
默认配置文件
core-default.xml
hdfs-default.xml
yarn-default.xml
mapred-default.xml
自定义文件
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
hadoop在运行的时候会先加载xxx-default.xml,然后再加载xxx-site.xml配置文件,相同的配置xxx-site.xml会覆盖xxx-default.xml
开始配置集群
- 配置hadoop-env.sh
配置jdk的路径
export JAVA_HOME=/opt/module/jdk1.8.0_181
- core-site.sh 核心配置文件
把配置加到<configuration></configuration>之间
指定NameNode的地址
指定NameNode的内部地址,NameNode--DataNode--NodeManger 之间进行通信
hdfs://node:8020 协议://主机:端口 端口可以改变,但需要统一与
<property>
<name>fs.defaultFS</name>
<value>hdfs://node:8020</value>
</property>
指定hadoop数据的存储目录
官方配置文件中的配置项是hadoop.tmp.dir,用来指定hadoop数据的存储目录,次吃配置用的hadoop.data.dir是自己定义的变量,因为再hdfs-site.xml中会引用此配置的值来具体指定namenode和datanode存储数据的目录
再core-site.xml中用不上,作为一个临时变量,被其他的配置文件引用
<property>
<name>hadoop.data.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
兼容性的配置,目前不需要配置,学习hive的时候,需要配置这些
配置该atguigu(superUser)允许通过代理访问的主机节点
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
配置该atguigu(superuser)允许代理的用户所属组
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
配置atguigu(superuser)允许代理的用户
<property>
<name>hadoop.proxyuser.atguigu.userr</name>
<value>*</value>
</property>
- hdfs-site.xml
指定副本数,保存的数据的copy的副本的数量
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
指定NameNode数据的存储目录
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.data.dir}/name</value>
</property>
指定DataNode数据的存储目录
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.data.dir}/data</value>
</property>
指定SecondaryNameNode数据的存储目录
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file://${hadoop.dta.dir}/secondaryname</value>
</property>
兼容性配置。先跳过
<property>
<name>dfs.client.datanode-restart.timeout</name>
<value>30s</value>
</property>
namenode web端访问地址
<property>
<name>dfs.namenode.http-address</name>
<value>node1:9870</value>
</property>
secondarynamenode web端访问地址
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node3:9868</value>
</property>
- yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
指定ResourceManager的地址
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node2</value> 不需要写端口号,有默认的端口号
</property>
环境变量的继承,如果不配置,可能会出现很多错误
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ</value>
</property>
取消虚拟内存的限制
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
- mapred-site.xml
指定MapReduce程序运行再Yarn上
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 把配置文件分发到其他节点上
xsync hadoop
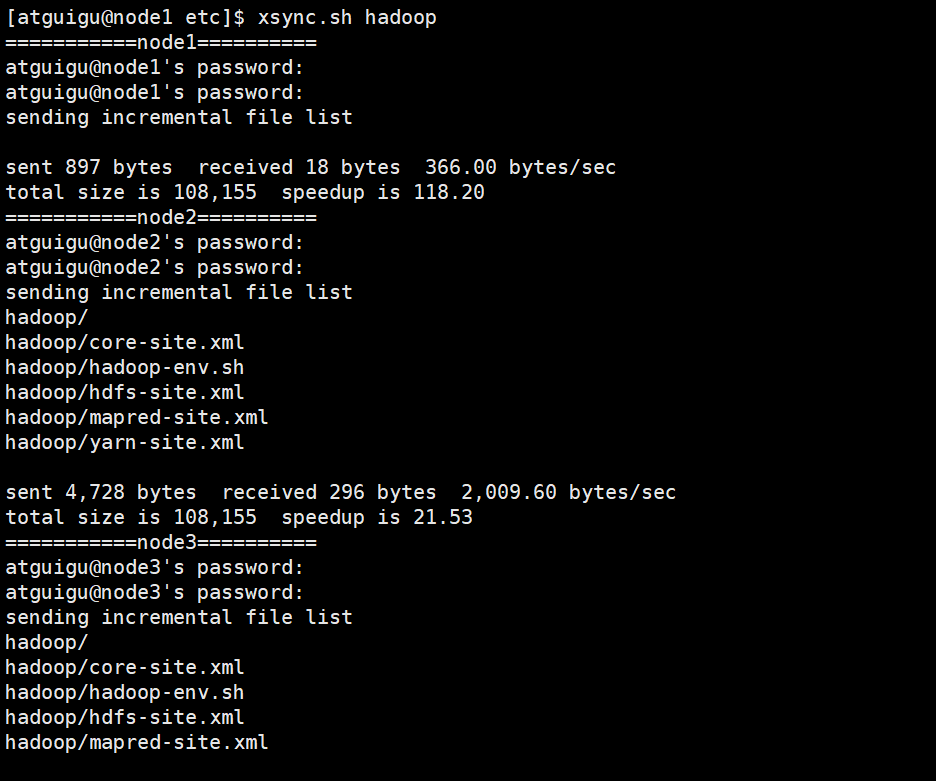
集权单点启动
- 如果集群是第一次启动,需要格式化NameNode
生成一些数据存储的目录,以及NameNode中数据的元文件
hdfs namenode -format
- 启动
node1
hdfs --daemon start namenode
hdfs --daemon start datanode
yarn --daemon start nodemanager
node2
hdfs --daemon start datanode
yarn --daemon start resourcemanager
yarn --daemon start nodemanager
node3
hdfs --daemon start datanode
hdfs --daemon start secondarynamenode
yarn --daemon start nodemanager
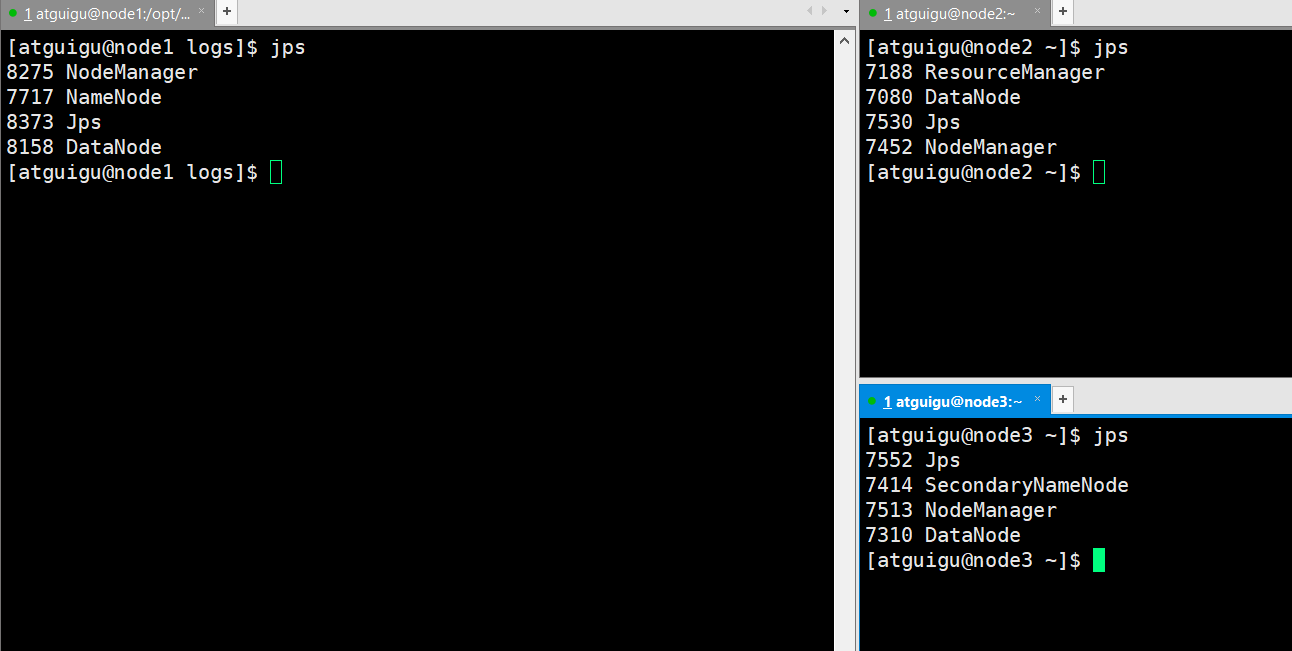
- 通过web访问
namenode
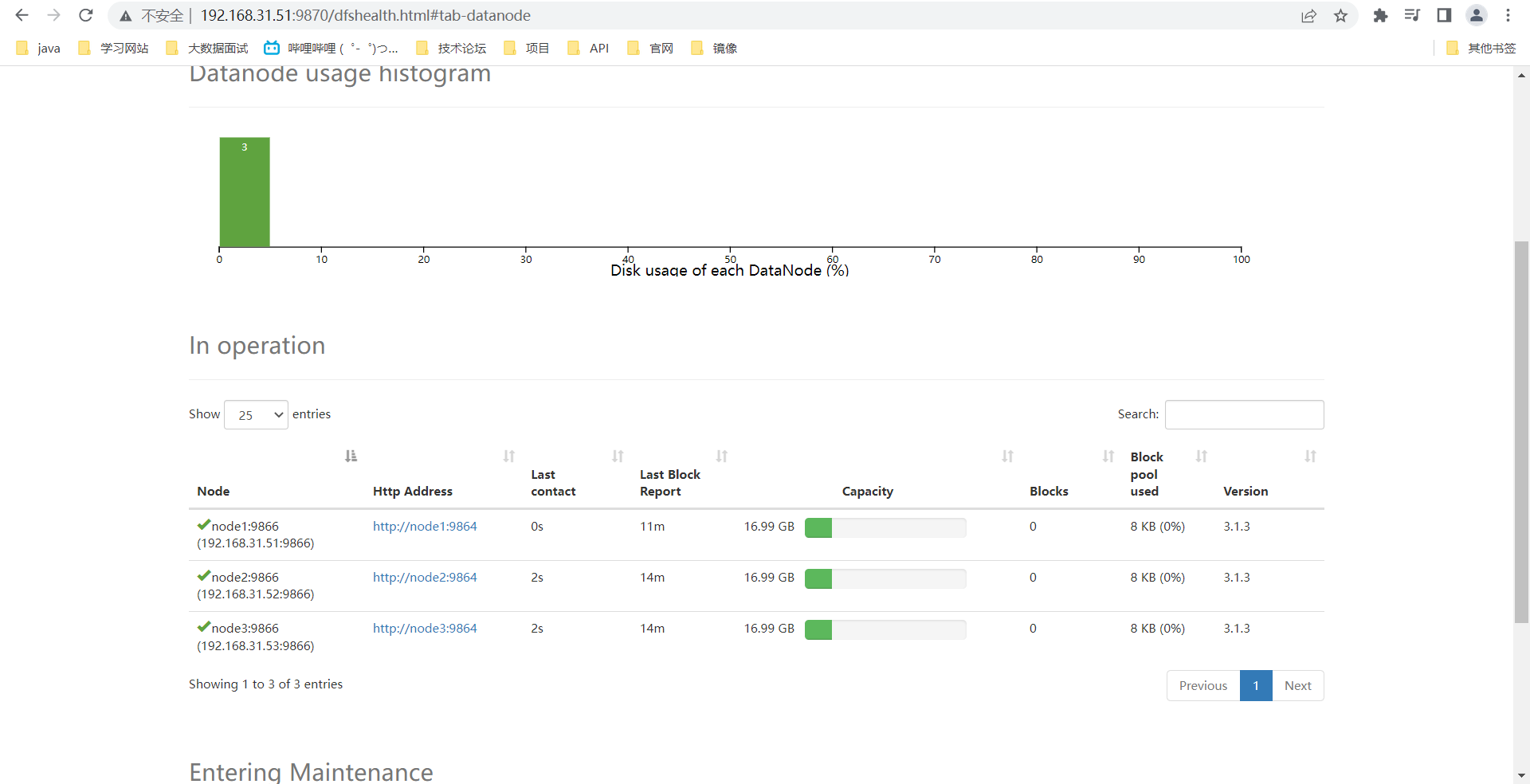
secondaynamenode
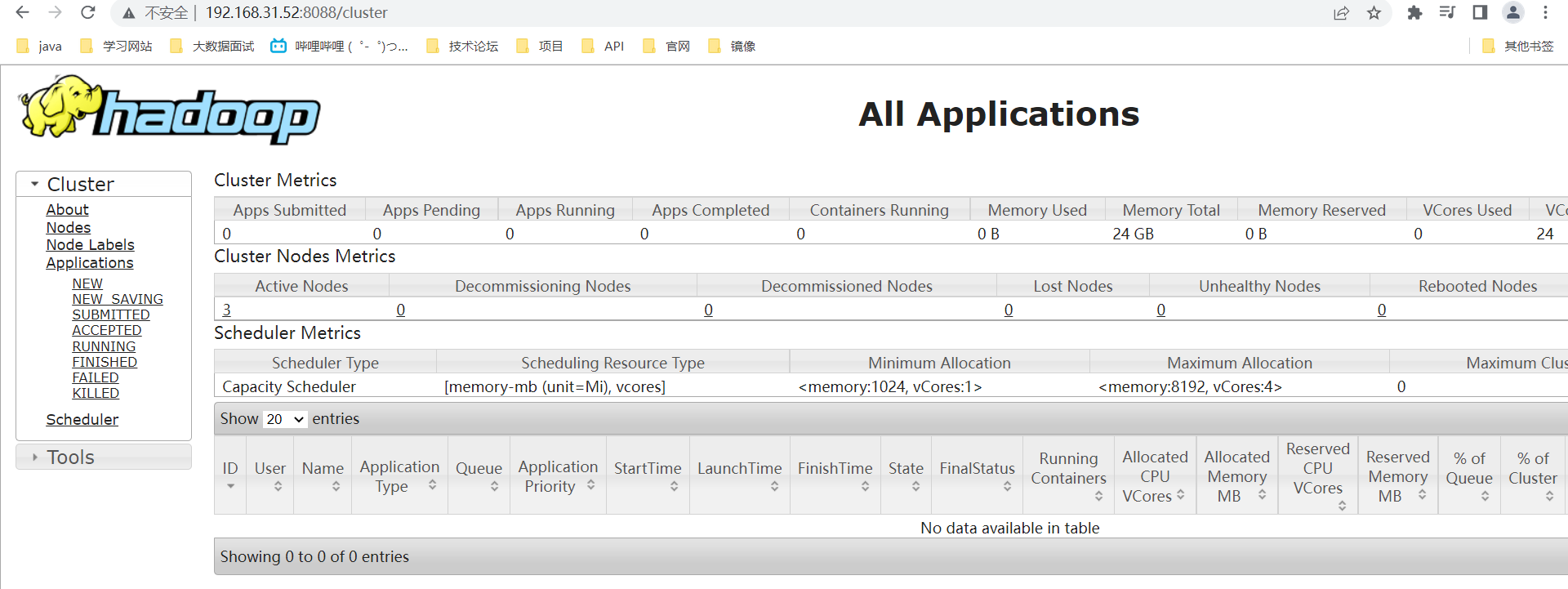
yarn
总结:
集群启动:
1. 如果集群是新集群,第一次启动需要格式化namenode
在namenode的节点执行:hdfs namenode -format
2. 启动namenode
在namenode节点执行:hdfs --daemon start namenode
3. 启动datanode
在所有的节点执行:hdfs --daemon start datanode
4. 启动secondarynamenode
在2nn节点执行:hdfs --daemon start secondarynamenode
5. 启动resourcemanager
在resourcemanager节点启动:yarn --daemon start resourcemanager
6. 启动nodemanager
在所有的节点执行:yarn --daemon start nodemanager
7. 验证:
通过jps命令查看所有的进程是否存在
或
通过web端访问
namenode: 192.168.31.51:9870
yarn: 192.168.31.52:8088
secondarynamenode:192.168.31.53:9868
8. 关闭
start 改为 stop
从小弟开始关
hdfs:先关datanode secondarynamenode namenode
yarn:先关nodemanager resourcemanager
日志
出问题看日志
免密登录
ssh-keygen -t rsa 生成公钥和私钥
ssh-copy-id 主机 把公钥复制到指定的主机
其他
linux图形化界面系统安装jdk需要注意的问题:
默认自带openjdk,安装自己的jdk之前,需要卸载openjdk
步骤:
查询openjdk的rpm
rpm -qa | grep -i java
卸载
rpm -e --nodeps查询到的rpm包
组合实现
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
解释:
xargs -n1
把前面查询的结果作为参数,传到后面的命令中
-n1 表示每次传一个参数
linux的命令
cd -P
basename
dirname
下游
基于hadoop扩展出来的一些框架
错误:hdfs --daemon start namenode 启动hadoop报错
2022-04-18 04:53:08,496 INFO org.apache.hadoop.metrics2.impl.MetricsSystemImpl: NameNode metrics system started
2022-04-18 04:53:08,637 INFO org.apache.hadoop.hdfs.server.namenode.NameNodeUtils: fs.defaultFS is file:///
2022-04-18 04:53:09,543 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
java.lang.IllegalArgumentException: Invalid URI for NameNode address (check fs.defaultFS): file:/// has no authority.
at org.apache.hadoop.hdfs.DFSUtilClient.getNNAddress(DFSUtilClient.java:780)
at org.apache.hadoop.hdfs.DFSUtilClient.getNNAddressCheckLogical(DFSUtilClient.java:809)
at org.apache.hadoop.hdfs.DFSUtilClient.getNNAddress(DFSUtilClient.java:771)
at org.apache.hadoop.hdfs.server.namenode.NameNode.getRpcServerAddress(NameNode.java:541)
at org.apache.hadoop.hdfs.server.namenode.NameNode.loginAsNameNodeUser(NameNode.java:672)
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:692)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:949)
at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:922)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1688)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1755)
2022-04-18 04:53:09,566 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1: java.lang.IllegalArgumentException: Invalid URI for Nam
eNode address (check fs.defaultFS): file:/// has no authority.2022-04-18 04:53:09,608 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node1/192.168.31.51
************************************************************/
错误原因:
Invalid URI for NameNode address (check fs.defaultFS): file:/// has no authority.
NameNode地址的URI无效(请检查fs.defaultFS):文件:///没有权限
fs-defatulFS:官方解释
默认文件系统的名称。一种URI,其方案和权限决定文件系统的实现。uri的方案确定命名文件系统实现类的配置属性(fs.scheme.impl)。uri的权限用于确定文件系统的主机、端口等。
fs.default.name:官方解释
不赞成。改为使用(fs.defaultFS)属性
原因:
不知道
解决方法:
修改core-site.xml配置文件
原来
<property>
<name>fs-defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
修改后
<property>
<name>fs.default.name</name>
<value>hdfs://node1:8020</value>
</property>
jps
java提供的一个 查看所有的进程
重新执行hdfs namenode -format
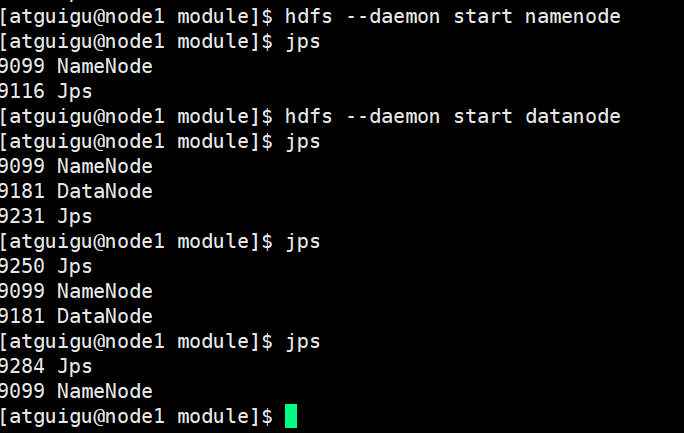
发现namenode可以启动,datanode启动失败
- 原因
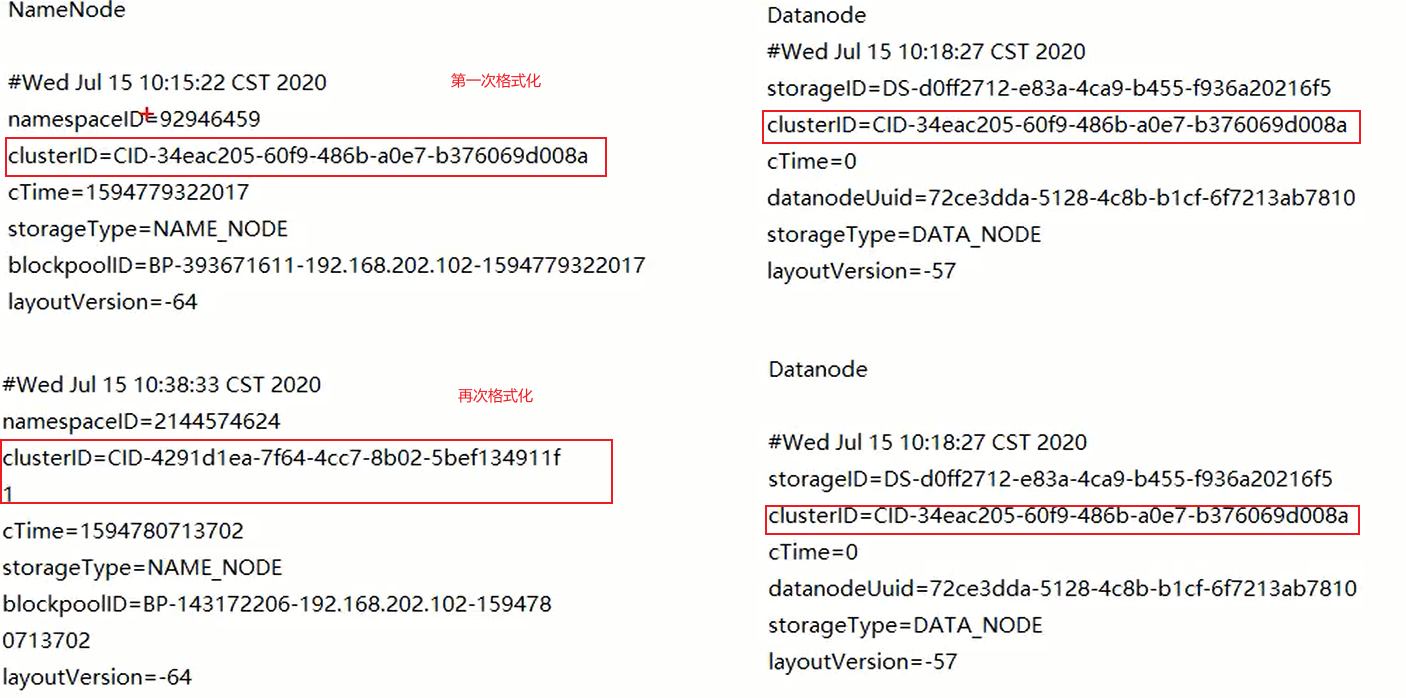
格式化后的clusterID不同
当集群进行第一次的namenode格式化的时候会生成一个clusterID,当启动datanode节点,就会通过我们配置的namenode的内部地址,向namenode询问信息,得到集群的clusterID,就相当于datanode找到了自己的集群。clusterID不同,说明属于不同的集群。
- 解决方法
删除三个节点上的data文件夹,就是当你进行namenode格式化的时候自动生成的目录
然后重新进行namenode格式化:hdfs namenode -format
问题:把clusterID改成一样的,是否能解决这个问题?
不行
原因:
namenode保存的是datanode的元数据,元数据都被清除了,无法通过元素据找到真实的数据,也就没有颁发和datanode建立关系,所以不能通过更改clusterID的方式,解决这个问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号