
day28-python-spider
day28-python-spider
python
爬取小说实战
# BeautifulSoup使用
import re
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import requests
url='https://www.shicimingju.com/book/houhanyanyi.html'
ua=UserAgent()
headers={
"User-Agent":ua.firefox
}
resp=requests.get(url=url,headers=headers)
resp.encoding="utf-8"
html=resp.text
soup=BeautifulSoup(html,"html.parser")
itemList=soup.find_all("div",class_="book-mulu")
itemLinkList=soup.select('.book-mulu>ul>li>a')
# 获取标题对应的内容
def getTitleContent(url,title):
resp = requests.get(url=url, headers=headers)
resp.encoding = "utf-8"
html=resp.text
soup=BeautifulSoup(html,"lxml")
content=soup.find("div",class_="chapter_content").text
# findContent=re.compile('<div class="chapter_content">(.*?)</div>',re.S)
# content=re.findall(findContent,str(content))[0]
# content=str(content).replace("<br/>","\n")
print(content)
with open("小说.text","a",encoding="utf-8") as f:
f.write("\n"+title+"\n"+content)
for itemLink in itemLinkList:
title=itemLink.text
titleSrc="https://www.shicimingju.com"+itemLink["href"]
getTitleContent(titleSrc,title)

Selenium
Selenium是一个用于测试Web应用程序的自动化测试工具,它直接运行在浏览器中,实现了对浏览器的自动化操作,它支持所有主流的浏览器,包括IE、Firefos、Safari、Chrome。
Selenium提供了一个工具集,包括Selenium WebDriver(浏览器驱动)、Selenium IDE(录制测试脚本)、Selenium Grid(执行测试脚本)。
实现自动爬虫
安装:
pip install selenium
暂时跳过
Scrapy
scrapy是一个基于Twisted实现的一部处理爬虫框架,该框架使用纯Python语言编写。
Scrapy框架应用广泛,常用于数据采集、网络检测、以及自动化测试等。
Twisted是一个基于事件驱动的网络引擎框架,同样采用Python实现
下载安装Scrapy
pip install Scrapy
常用命令
| 命令 | 格式 | 说明 |
|---|---|---|
| startproject | scrapy startproject 项目 | 创建一个新项目 |
| genspider | scrapy genspider 爬虫文件名 域名 | 新建爬虫文件 |
| runspider | scrapy runspider 爬虫文件 | 运行一个爬虫文件,不需要创建项目 |
| crawl | scrapy crawl spidername | 运行一个爬虫项目,必须要创建项目 |
| list | scrapy list | 列出项目中所有爬虫文件 |
| view | scrapy view url地址 | 从浏览器中打开url地址 |
| shell | csrapy shell url地址 | 命令行交互模式 |
| settings | scrapy settings | 查看当前项目的配置信息 |
创建一个爬虫项目
通过命令:scrapy startproject Baidu
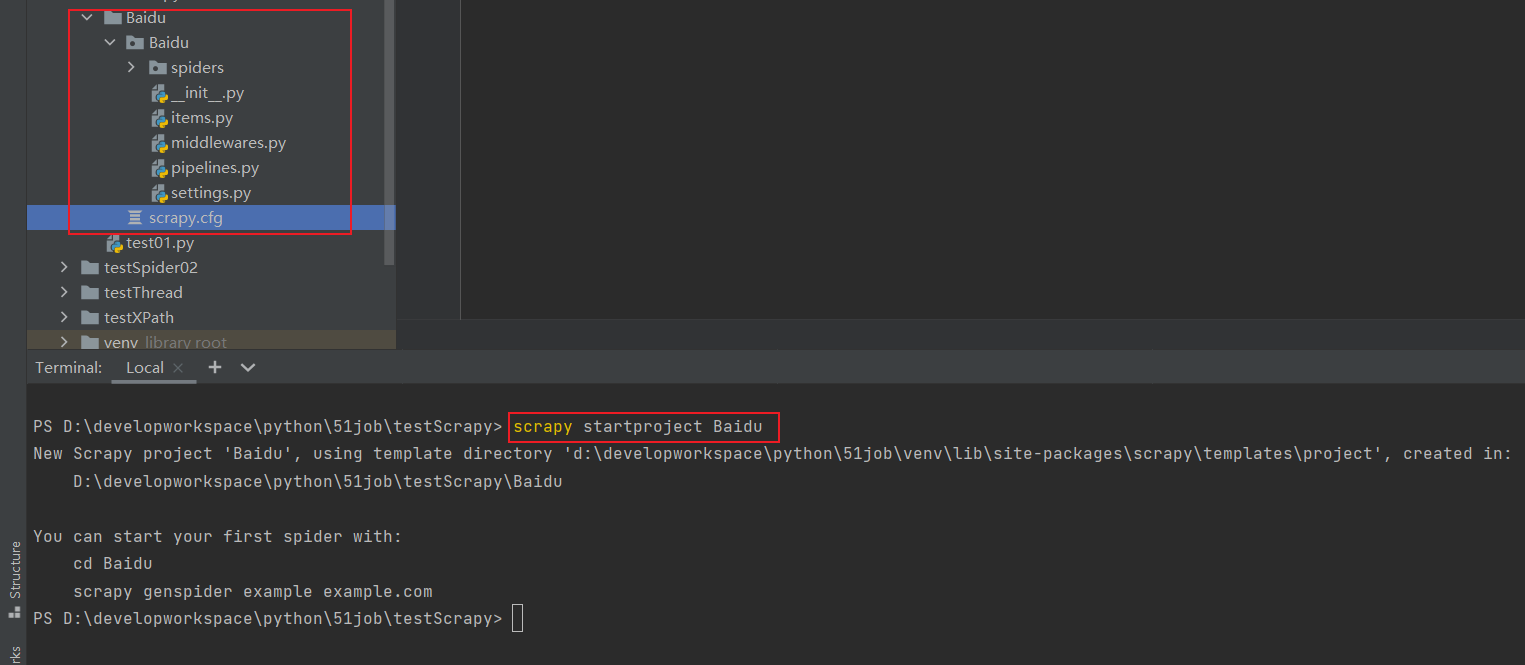
Baidu # 项目文件夹
├── Baidu # 用来装载项目文件的目录
│ ├── items.py # 定义要抓取的数据结构
│ ├── __init__.py # Python中package的标识,不能删除
│ ├── middlewares.py # 中间件,用来设置一些处理规则
│ ├── pipelines.py # 管道文件,处理抓取的数据
│ ├── settings.py # 全局配置文件
│ └── spiders # 用来装载爬虫文件的目录
│ ├── baidu.py # 具体的爬虫程序
└── scrapy.cfg # 项目基本配置文件
Scrapy爬虫工作流程
Scrapy框架由五大组件构成
| 名称 | 作用说明 |
|---|---|
| Engine(引擎) | 整个Scrapy框架的核心,主要负责数据和信号在不同模块间传递 |
| Scheduler(调度器) | 用来维护引擎发送过来的request请求队列 |
| Downloader(下载器) | 接受引擎发送过来的response请求,主要用来解析、提取数据和获取需要跟进的二级url,然后将这些数据交回个引擎 |
| Pipeline(项目管道) | 实现数据存储,对引擎发送过来的数据进一步处理,如如存MySQL数据库等 |
在整个执行过程中,还涉及到两个middlewares中间件,分别是下载器中间件(Downloader Middlewares)和蜘蛛中间件(Spider Middlewares)
- 下载中间件:位于引擎和下载器之间,主要用来包装request请求头,比如UserAgent、Cookies和代理IP
- 蜘蛛中间件,位于引擎与爬虫文件之间,它主要用来修改响应对象的属性
Scrapy工作流程示意图如下所示:
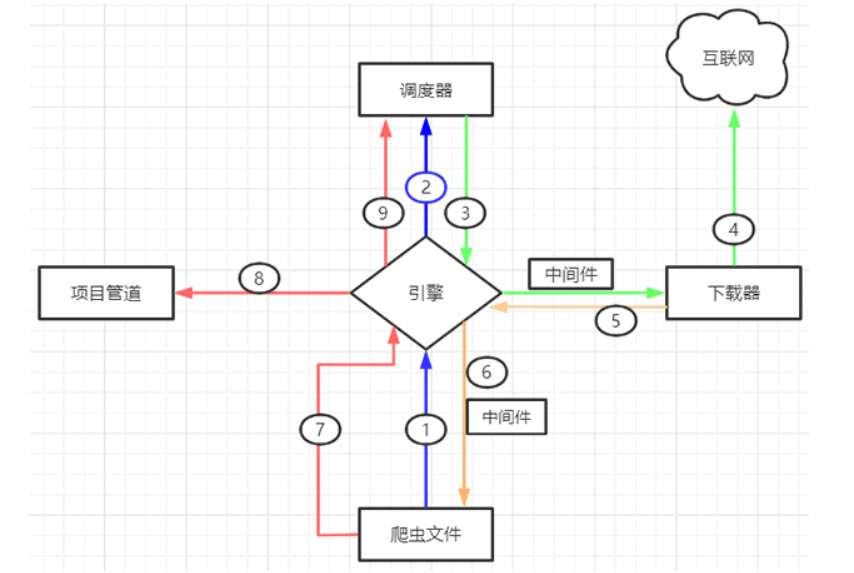
当启动一个爬虫项目启动后,Scrapy框架回进行以下工作:
- 由 引擎 向爬虫文件索要第一个带爬取的URL,并将其交给调度器加入URL队列中(1/2步骤)
- 调度器处理完请求后,将第一个URL出队列返回给引擎;引擎经由下载器中间件将该URL交给下载器去下载response对象(3/4步骤)
- 下载器得到响应结果进行处理、分析,并提取出所需要的数据
- 最后,提取的数据会交给管道文件去存数据库,同时将需要继续跟进的二级页面URL交给调度器去入队列(7/8/9)
- 上述过程会一直循环,直到没有要爬取的URL为止,也就是URL队列空时才会停止。
settings配置文件
# 定义User-Agent
USER_AGENT='Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)'
# 是否遵循robots协议,一般设置为False
ROBOTSTXT_OBEY=False
# 最大并发量,默认为16
CONCURRENT_REQUESTS=32
# 下载延迟时间
DOWNLOAD_DELAY=1
其余常用配置项介绍
# 设置日志级别,DEBUG<INFO<WARNING<ERROR<CRITICAL
LOG_LEVEL=''
#将日志信息保存日志文件中,而不在终端输出
LOG_FILE=''
# 设置导出数据的编码格式(主要针对于json文件)
FEED_EXPORT_ENCODING=''
# 非结构化数据的存储路径
IMAGES_STORE='路径'
# 请求头,此处可以添加User-Agent、cookies、referer等
DEFAULT_REQUEST_HEADERS={}
# 项目管道,300 代表激活的优先级,越小越优先,取值1到1000
ITEM_PIPELINES={
'Baidu.pipelines.BaiduPipeline':300
}
# 添加下载器中间件
DOWNLOADER_MIDDLEWARES={}
项目实战
在cmd命令行执行命令创建项目以及爬虫文件
# 创建项目
scrapy startproject Title
# 进入项目
cd Title
# 创建爬虫文件
scrapy genspider title c.biancheng.net
创建一个爬虫文件名字为 title 域名为 c.biancheng.net,会自动生成一个模板文件
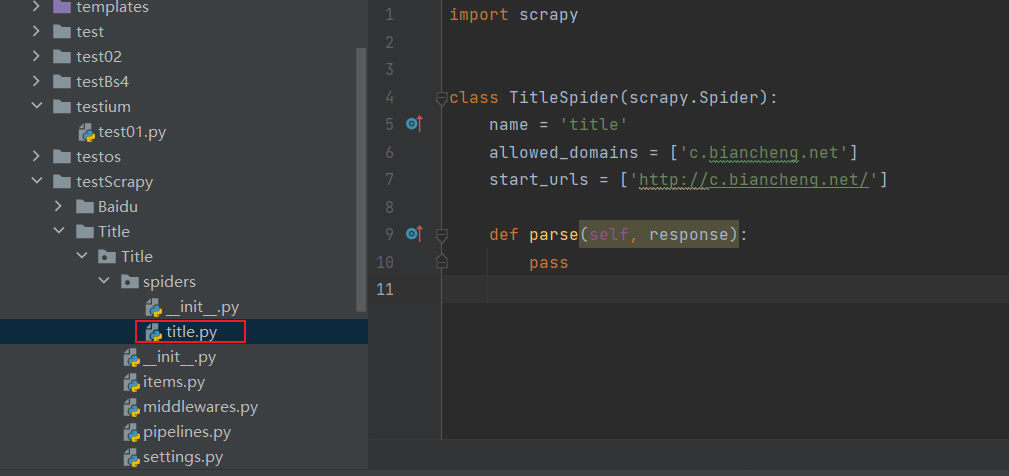
编辑title.py爬虫文件
import scrapy
class TitleSpider(scrapy.Spider):
name = 'title' # 爬虫的名字
allowed_domains = ['c.biancheng.net'] #要抓取网站的域名
start_urls = ['http://c.biancheng.net/'] # 第一个抓取的url,初始url,被当作队列来处处理
def parse(self, response):
result=response.xpath('/html/head/title/text()').extract_first()
print("华丽的分割线".center(30,"*"))
print(result)
print("华丽的分割线".center(30, "*"))
pass
编辑settings.py配置文件
# 用户代理
USER_AGENT='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'
# 是否遵守robot协议
ROBOTSTXT_OBEY=False
# 默认的请求头
DEFAULT_REQUEST_HEADERS={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language':'en'
}
编辑main.py运行爬虫的文件
from scrapy import cmdline
# 注意,cmdline.execute()是为了减少输入命令的操作,参数必须是列表
cmdline.execute('scrapy crawl title'.split())
执行的结果:
D:\developworkspace\python\51job\venv\Scripts\python.exe D:/developworkspace/python/51job/testScrapy/Title/Title/spiders/main.py
2022-04-15 19:39:30 [scrapy.utils.log] INFO: Scrapy 2.6.1 started (bot: Title)
2022-04-15 19:39:30 [scrapy.utils.log] INFO: Versions: lxml 4.8.0.0, libxml2 2.9.12, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 22.2.0, Python 3.10.3 (tags/v3.10.3:a342a49, Mar 16 2022, 13:07:40) [MSC v.1929 64 bit (AMD64)], pyOpenSSL 22.0.0 (OpenSSL 1.1.1n 15 Mar 2022), cryptography 36.0.2, Platform Windows-10-10.0.19044-SP0
2022-04-15 19:39:30 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'Title',
'NEWSPIDER_MODULE': 'Title.spiders',
'SPIDER_MODULES': ['Title.spiders'],
'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'}
2022-04-15 19:39:30 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2022-04-15 19:39:30 [scrapy.extensions.telnet] INFO: Telnet Password: 18e41bf49c842aaf
2022-04-15 19:39:30 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2022-04-15 19:39:31 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2022-04-15 19:39:31 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2022-04-15 19:39:31 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2022-04-15 19:39:31 [scrapy.core.engine] INFO: Spider opened
2022-04-15 19:39:33 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2022-04-15 19:39:33 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2022-04-15 19:39:33 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://c.biancheng.net/> (referer: None)
2022-04-15 19:39:33 [scrapy.core.engine] INFO: Closing spider (finished)
2022-04-15 19:39:33 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 369,
'downloader/request_count': 1,
'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 7476,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'elapsed_time_seconds': 0.311814,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2022, 4, 15, 11, 39, 33, 479578),
'httpcompression/response_bytes': 28389,
'httpcompression/response_count': 1,
'log_count/DEBUG': 2,
'log_count/INFO': 10,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2022, 4, 15, 11, 39, 33, 167764)}
2022-04-15 19:39:33 [scrapy.core.engine] INFO: Spider closed (finished)
************华丽的分割线************
C语言中文网:C语言程序设计门户网站(入门教程、编程软件)
************华丽的分割线************
Process finished with exit code 0
抓取豆瓣电影Top100
通过终端的方式使用scrapy架构创建项目doubantop100
# 创建项目
scrapy startproject douban
# 进入项目
cd douban
# 创建爬虫文件doubantop250
# 必须是网站的域名
scrapy genspider doubantop250 movie.douban.com
创建main.py爬虫执行入口
from scrapy import cmdline
# 执行名字为top100Spider爬虫 并把数据保存到文件中
cmdline.execute('scrapy crawl doubantop250 -o top250.csv'.split())
items.py 定义数据结构
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class Doubantop100Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name=scrapy.Field()
star=scrapy.Field()
rat=scrapy.Field()
pass
top100Spider.py 爬虫项目
import scrapy
from testScrapy.douban.douban.items import DoubanItem
class Doubantop250Spider(scrapy.Spider):
name = 'doubantop250'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250?start=25&filter=']
start=25
def parse(self, response):
itemList=response.xpath('//ol[@class="grid_view"]/li')
# DoubanItem 进行实例化
doubanItem=DoubanItem()
for item in itemList:
name=item.xpath('.//img/@alt').get()
inq=item.xpath('.//span[@class="inq"]/text()').get()
rat=item.xpath('.//span[@class="rating_num"]/text()').get()
doubanItem['name']=name
doubanItem['inq']=inq
doubanItem['rat']=rat
yield doubanItem
print(name,inq,rat)
# if self.start<90:
# self.start+=25
# url='https://movie.douban.com/top250?start={}&filter='.format(self.start)
# yield scrapy.Request(url=url,callback=self.parse)
pass
pipelines.py 实现数据存储
class DoubanPipeline:
def process_item(self, item, spider):
print("pipelines:",item['name'],item['inq'],item['rat'])
return item
settings.py 配置文件
BOT_NAME = 'doubantop100'
SPIDER_MODULES = ['doubantop100.spiders']
NEWSPIDER_MODULE = 'doubantop100.spiders'
# 设置robot.txt为False
ROBOTSTXT_OBEY = False
# 请求头信息
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'
}
运行结果:
D:\developworkspace\python\51job\venv\Scripts\python.exe D:/developworkspace/python/51job/testScrapy/douban/douban/spiders/main.py
2022-04-15 23:30:02 [scrapy.utils.log] INFO: Scrapy 2.6.1 started (bot: douban)
2022-04-15 23:30:02 [scrapy.utils.log] INFO: Versions: lxml 4.8.0.0, libxml2 2.9.12, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 22.2.0, Python 3.10.3 (tags/v3.10.3:a342a49, Mar 16 2022, 13:07:40) [MSC v.1929 64 bit (AMD64)], pyOpenSSL 22.0.0 (OpenSSL 1.1.1n 15 Mar 2022), cryptography 36.0.2, Platform Windows-10-10.0.19044-SP0
2022-04-15 23:30:02 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'douban',
'NEWSPIDER_MODULE': 'douban.spiders',
'SPIDER_MODULES': ['douban.spiders']}
2022-04-15 23:30:02 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2022-04-15 23:30:02 [scrapy.extensions.telnet] INFO: Telnet Password: 4b2a144971542f9c
2022-04-15 23:30:03 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.feedexport.FeedExporter',
'scrapy.extensions.logstats.LogStats']
2022-04-15 23:30:03 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2022-04-15 23:30:03 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2022-04-15 23:30:03 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2022-04-15 23:30:03 [scrapy.core.engine] INFO: Spider opened
2022-04-15 23:30:04 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2022-04-15 23:30:04 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2022-04-15 23:30:04 [filelock] DEBUG: Attempting to acquire lock 1663034880112 on D:\developworkspace\python\51job\venv\lib\site-packages\tldextract\.suffix_cache/publicsuffix.org-tlds\de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2022-04-15 23:30:04 [filelock] DEBUG: Lock 1663034880112 acquired on D:\developworkspace\python\51job\venv\lib\site-packages\tldextract\.suffix_cache/publicsuffix.org-tlds\de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2022-04-15 23:30:04 [filelock] DEBUG: Attempting to acquire lock 1663034881408 on D:\developworkspace\python\51job\venv\lib\site-packages\tldextract\.suffix_cache/urls\62bf135d1c2f3d4db4228b9ecaf507a2.tldextract.json.lock
2022-04-15 23:30:04 [filelock] DEBUG: Lock 1663034881408 acquired on D:\developworkspace\python\51job\venv\lib\site-packages\tldextract\.suffix_cache/urls\62bf135d1c2f3d4db4228b9ecaf507a2.tldextract.json.lock
2022-04-15 23:30:04 [filelock] DEBUG: Attempting to release lock 1663034881408 on D:\developworkspace\python\51job\venv\lib\site-packages\tldextract\.suffix_cache/urls\62bf135d1c2f3d4db4228b9ecaf507a2.tldextract.json.lock
2022-04-15 23:30:04 [filelock] DEBUG: Lock 1663034881408 released on D:\developworkspace\python\51job\venv\lib\site-packages\tldextract\.suffix_cache/urls\62bf135d1c2f3d4db4228b9ecaf507a2.tldextract.json.lock
2022-04-15 23:30:04 [filelock] DEBUG: Attempting to release lock 1663034880112 on D:\developworkspace\python\51job\venv\lib\site-packages\tldextract\.suffix_cache/publicsuffix.org-tlds\de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2022-04-15 23:30:04 [filelock] DEBUG: Lock 1663034880112 released on D:\developworkspace\python\51job\venv\lib\site-packages\tldextract\.suffix_cache/publicsuffix.org-tlds\de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2022-04-15 23:30:04 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://movie.douban.com/top250?start=25&filter=> (referer: None)
2022-04-15 23:30:04 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '人人心中都有个龙猫,童年就永远不会消失。', 'name': '龙猫', 'rat': '9.2'}
2022-04-15 23:30:04 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '“不要跟我比惨,我比你更惨”再适合这部电影不过了。', 'name': '末代皇帝', 'rat': '9.3'}
龙猫 人人心中都有个龙猫,童年就永远不会消失。 9.2
末代皇帝 “不要跟我比惨,我比你更惨”再适合这部电影不过了。 9.3
蝙蝠侠:黑暗骑士 无尽的黑暗。 9.2
寻梦环游记 死亡不是真的逝去,遗忘才是永恒的消亡。 9.1
活着 张艺谋最好的电影。 9.3
哈利·波特与魔法石 童话世界的开端。 9.1
指环王3:王者无敌 史诗的终章。 9.3
乱世佳人 Tomorrow is another day. 9.3
2022-04-15 23:30:04 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '无尽的黑暗。', 'name': '蝙蝠侠:黑暗骑士', 'rat': '9.2'}
2022-04-15 23:30:04 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '死亡不是真的逝去,遗忘才是永恒的消亡。', 'name': '寻梦环游记', 'rat': '9.1'}
2022-04-15 23:30:04 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '张艺谋最好的电影。', 'name': '活着', 'rat': '9.3'}
2022-04-15 23:30:04 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '童话世界的开端。', 'name': '哈利·波特与魔法石', 'rat': '9.1'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '史诗的终章。', 'name': '指环王3:王者无敌', 'rat': '9.3'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': 'Tomorrow is another day.', 'name': '乱世佳人', 'rat': '9.3'}
素媛 受过伤害的人总是笑得最开心,因为他们不愿意让身边的人承受一样的痛苦。 9.3
飞屋环游记 最后那些最无聊的事情,才是最值得怀念的。 9.1
摔跤吧!爸爸 你不是在为你一个人战斗,你要让千千万万的女性看到女生并不是只能相夫教子。 9.0
何以为家 凝视卑弱生命,用电影改变命运。 9.1
我不是药神 对我们国家而言,这样的电影多一部是一部。 9.0
十二怒汉 1957年的理想主义。 9.4
哈尔的移动城堡 带着心爱的人在天空飞翔。 9.1
少年派的奇幻漂流 瑰丽壮观、无人能及的冒险之旅。 9.1
鬼子来了 对敌人的仁慈,就是对自己残忍。 9.3
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '受过伤害的人总是笑得最开心,因为他们不愿意让身边的人承受一样的痛苦。', 'name': '素媛', 'rat': '9.3'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '最后那些最无聊的事情,才是最值得怀念的。 ', 'name': '飞屋环游记', 'rat': '9.1'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '你不是在为你一个人战斗,你要让千千万万的女性看到女生并不是只能相夫教子。', 'name': '摔跤吧!爸爸', 'rat': '9.0'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '凝视卑弱生命,用电影改变命运。', 'name': '何以为家', 'rat': '9.1'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '对我们国家而言,这样的电影多一部是一部。', 'name': '我不是药神', 'rat': '9.0'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '1957年的理想主义。 ', 'name': '十二怒汉', 'rat': '9.4'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '带着心爱的人在天空飞翔。', 'name': '哈尔的移动城堡', 'rat': '9.1'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '瑰丽壮观、无人能及的冒险之旅。', 'name': '少年派的奇幻漂流', 'rat': '9.1'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '对敌人的仁慈,就是对自己残忍。', 'name': '鬼子来了', 'rat': '9.3'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '旷古烁今。', 'name': '大话西游之月光宝盒', 'rat': '9.0'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '骗子大师和执著警探的你追我跑故事。 ', 'name': '猫鼠游戏', 'rat': '9.1'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '对天空的追逐,永不停止。 ', 'name': '天空之城', 'rat': '9.1'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '那些吻戏,那些青春,都在影院的黑暗里被泪水冲刷得无比清晰。', 'name': '天堂电影院', 'rat': '9.2'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '承前启后的史诗篇章。', 'name': '指环王2:双塔奇兵', 'rat': '9.2'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
大话西游之月光宝盒 旷古烁今。 9.0
猫鼠游戏 骗子大师和执著警探的你追我跑故事。 9.1
天空之城 对天空的追逐,永不停止。 9.1
天堂电影院 那些吻戏,那些青春,都在影院的黑暗里被泪水冲刷得无比清晰。 9.2
指环王2:双塔奇兵 承前启后的史诗篇章。 9.2
闻香识女人 史上最美的探戈。 9.1
钢琴家 音乐能化解仇恨。 9.2
罗马假日 爱情哪怕只有一天。 9.1
{'inq': '史上最美的探戈。', 'name': '闻香识女人', 'rat': '9.1'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '音乐能化解仇恨。', 'name': '钢琴家', 'rat': '9.2'}
2022-04-15 23:30:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=25&filter=>
{'inq': '爱情哪怕只有一天。', 'name': '罗马假日', 'rat': '9.1'}
2022-04-15 23:30:05 [scrapy.core.engine] INFO: Closing spider (finished)
2022-04-15 23:30:05 [scrapy.extensions.feedexport] INFO: Stored csv feed (25 items) in: douban.csv
2022-04-15 23:30:05 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 393,
'downloader/request_count': 1,
'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 12725,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'elapsed_time_seconds': 0.546681,
'feedexport/success_count/FileFeedStorage': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2022, 4, 15, 15, 30, 5, 54773),
'httpcompression/response_bytes': 67523,
'httpcompression/response_count': 1,
'item_scraped_count': 25,
'log_count/DEBUG': 35,
'log_count/INFO': 11,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2022, 4, 15, 15, 30, 4, 508092)}
2022-04-15 23:30:05 [scrapy.core.engine] INFO: Spider closed (finished)
Process finished with exit code 0
其他
__ init__ .py
在Python工程里,当python检测到一个目录下存在__init__.py文件时,python就会把它当成一个模块(module)
yield
返回 后面的结果,并且停止当前的运行
只能用在方法中,表示返回后面的结果对象,并且会停止当前的方法,如果想要继续运行,
方法相当于一个迭代器对象,可以通过next(方法)继续运行,也能通过方法.send(参数)给返回的那个变量赋值,然后继续运行
生成器(generator)函数用yield表达式将处理好的x发送给生成器(Generator)的调用者;然后生成器(generator)的调用者可以通过send函数,将外部信息替换生成器内部yield表达式的返回值,并赋值给y,并参与后续的迭代流程。
next()
返回迭代器的下一个项目
在python中方法是一个迭代器对象
D:\developworkspace\python\51job\venv\Scripts\python.exe D:/developworkspace/python/51job/testium/test02.py
<class 'generator'>
string......
4
********************
res None
4
Process finished with exit code 0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号