
day27-python-spider
day27-python-spider
python
Bs4解析库
Beautiful Soup简称BS4,它可以从HTML或XML文档中快速地提取指定的数据。
由于BS4解析页面时需要依赖文档解析器,所以还需要按照lxml作为解析库:
Python自带了一个文档解析库html.parser,但是其解析速度稍慢于lxml。
还可以使用html5lib解析器
BS4解析对象
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import requests
# 需要请求的url地址
url = 'https://movie.douban.com/chart'
ua=UserAgent()
headers={
"User-Agent":ua.ie
}
resp=requests.get(url=url,headers=headers)
html=resp.text
soup=BeautifulSoup(html,"html.parser")
# 格式化输出 html/xml
print(soup.prettify())
BS4常用语法
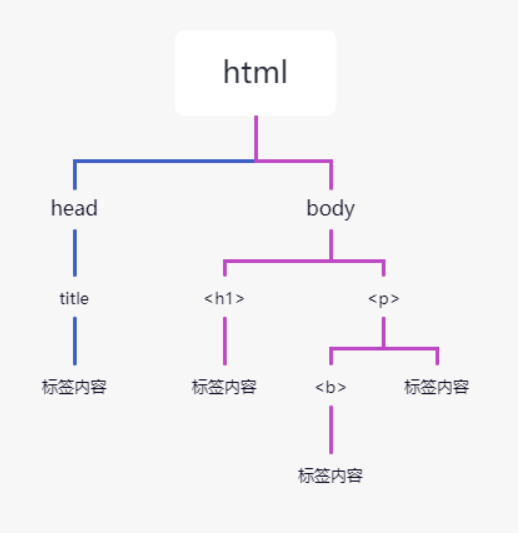
文档树种的每个节点都是Python对象,这些对象大致分为四类:Tag,NavigableString,BeautifulSoup,Comment。
- Tag:标签类,html文档种所有的标签都可以看作Tag对象
- NavigableString:字符串类,指的时标签种的文本内容,使用text、string、strings来获取文本内容
- BeautifulSoup:表示一个Html文档的全部内容,可以把它当作一个特殊的Tag对象
- Comment:表示HTML文档种的注释内容以及特殊字符串,他是一个特殊的NavigableString
Tag节点
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import requests
# 需要请求的url地址
url = 'https://movie.douban.com/chart'
ua=UserAgent()
headers={
"User-Agent":ua.ie
}
resp=requests.get(url=url,headers=headers)
html=resp.text
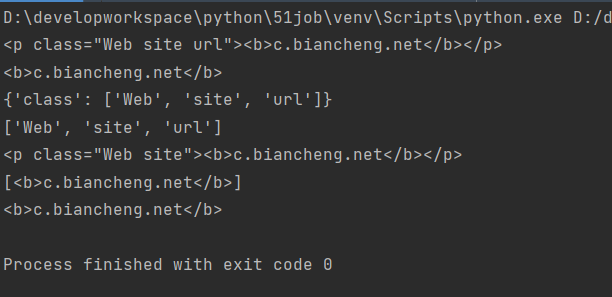
soup=BeautifulSoup('<p class="Web site url"><b>c.biancheng.net</b></p><p class="aaaa"><b>other.cn</b></p>',"html.parser")
# 格式化输出 html/xml
html=soup.prettify()
# 获取tr标签
trList=soup.p
print(trList)
# 获取b标签
print(soup.p.b)
# 返回一个标签的属性和值组成的字典
print(soup.p.attrs)
# 获取属性的值
print(soup.p['class'])
# 给属性复制
soup.p["class"]="Web site"
print(soup.p)
# 以列表形式输出所有子节点
pTag=soup.p
print(pTag.contents)
# 遍历有子节点
for children in pTag.children:
print(children)
find()和find_all()
- find_all()
find_all()方法用来搜索当前tag的所有子节点,并判断这些节点是否符合过滤条件,最后以列表形式将符合条件的内容返回
find_all(name,attrs,recursive,text,limit)
参数说明:
name:查找所有名字为name的tag标签,字符串对象会被自动忽略
attrs:按照属性名和属性值搜索tag标签,注意由于class是python的关键字,所以要使用clss_
recursive:fian_all() 会搜索tag的所有子孙节点,设置recursive=False可以只搜索tag的直接节点
text:用来搜索文档种的字符串内容,该参数可以接受字符串、正则表达式、列表、True
limit:由于find_all()会返回所有的搜索结果,这样会影响执行效率,通过limit参数可以限制返回结果的数量
import requests
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
url="https://movie.douban.com/chart"
ua=UserAgent()
headers={
"User-Agent":ua.ie
}
resp=requests.get(url=url,headers=headers)
html=resp.text
soup=BeautifulSoup(html,"html.parser")
# print(soup.prettify())
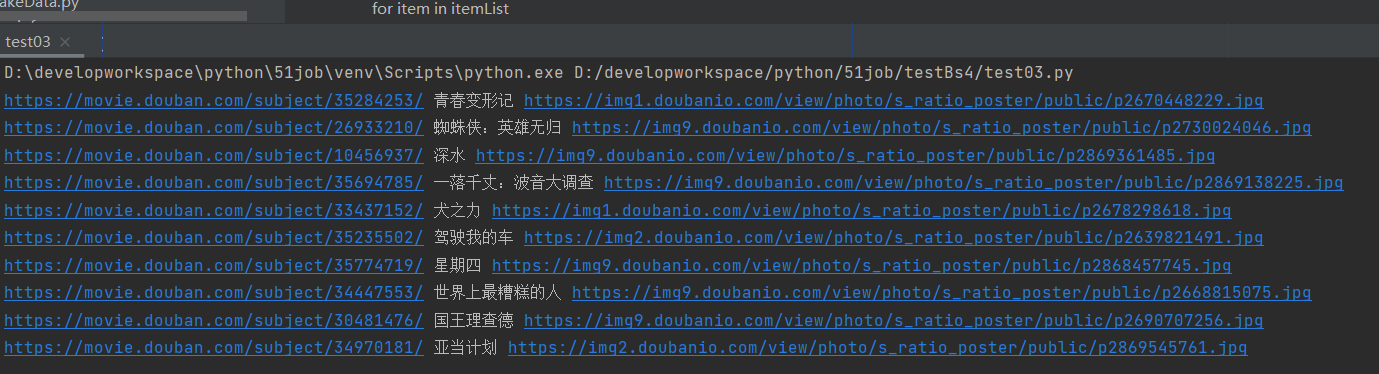
itemList=soup.find_all("tr",class_="item")
for item in itemList:
# print(item)
movieUrl=item.a["href"]
movieName=item.a["title"]
movieImgUrl=item.img["src"]
print(movieUrl,movieName,movieImgUrl)
find()
find()方法与find_all()类似,find_all()返回所有符合条件的,find()仅返回一个符合条件的结果
注:
find() 如果没有找到标签会返回None
find_all() 如果没有找到标签会返回空列表
CSS选择器
BS4支持大部分的CSS选择器,比如常见的标签选择器、类选择器、id选择器、层级选择器
BeautifulSoup提供了一个select()方法,通过向该方法种添加选择器,就可以在HTML文档种搜索到与之对应的内容。
import requests
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
url="https://movie.douban.com/chart"
ua=UserAgent()
headers={
"User-Agent":ua.ie
}
resp=requests.get(url=url,headers=headers)
html=resp.text
soup=BeautifulSoup(html,"html.parser")
# print(soup.prettify())
itemList=soup.find_all("tr",class_="item")
for item in itemList:
# print(item)
movieUrl=item.select('a[href]')
print(movieUrl)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号