day24-python-spider
day24-python-spider
python
XPath
基准表达式
能够匹配一个列表的表达式就叫做基准表达式
案例:
from lxml import etree
import requests
from fake_useragent import UserAgent
url = "https://movie.douban.com/top250"
# 伪造请求头
ua = UserAgent()
headers = {
"User-Agent":ua.firefox
}
# 接受请求的响应对象
resp = requests.get(url=url, headers=headers)
print(resp.status_code)
html = resp.text
# 对html进行一个解析,生成一个树结构
parseHtml=etree.HTML(html)
# 基准表达式,能过匹配一个列表
xpathBds='//div[@class="item"]'
itemList=parseHtml.xpath(xpathBds)
xpathMovieName='.//span[@class="title"]/text()'
# print(itemList)
for item in itemList:
movieNameList=item.xpath(xpathMovieName)
print(movieNameList)
爬取链家案例
# 爬取链家
import requests
from fake_useragent import UserAgent
from lxml import etree
# 要爬取的url地址 pag{} 代表当前是第几页
url = 'https://bj.lianjia.com/ershoufang/pag{}/'
# 伪造headers
ua = UserAgent()
headers = {
"User-Agent": ua.firefox
}
# 当前页
pageNum = 1;
url = url.format(pageNum)
# 获取响应
resp = requests.get(url=url, headers=headers)
# 获取页面
html = resp.text
# 对html进行解析
html=etree.HTML(html)
# 构建基准表达式
xpathItemList='//ul[@class="sellListContent"]/li'
# 获取列表
itemList=html.xpath(xpathItemList)
# 遍历列表
# 构建查询的xpth规则
# 图片链接
xpathImgLink='.//img[@class="lj-lazy"]/@src'
# 地点
xpathAdress='.//div[@class="positionInfo"]/a/text()'
# 详细楼层
xpathDetailAddr='.//div[@class="houseInfo"]/text()'
for item in itemList:
# 图片链接
imgLink=item.xpath(xpathImgLink)
# 地址
address=item.xpath(xpathAdress)
add=""
for a in address:
add+=a
# 详细楼层
detailAddr=item.xpath(xpathDetailAddr)[0]
# print(type(detailAddr))
# detailAddr=detailAddr.split('|')
print(detailAddr)
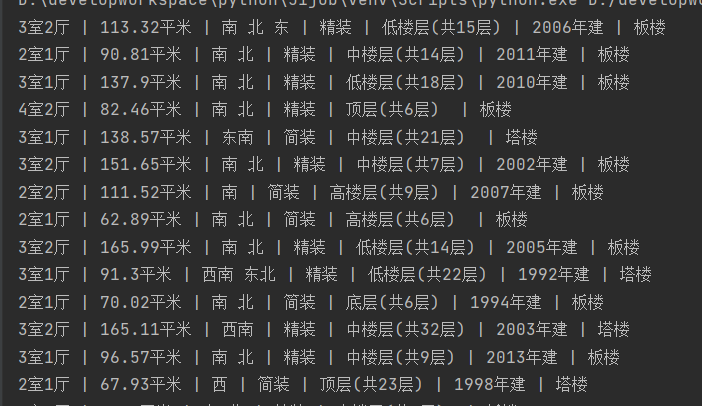
只显示爬到的部分结果,没有对数据进行处理
爬取有道词典
- 注意:前期需要做大量的分析工作,通过浏览器自带的抓包工具,实现对代码的分析,得到正确的请求参数
# 有道翻译软件
from fake_useragent import UserAgent
import requests
# https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule
# 发现上述的地址有个 _o 这是有道词典 做的一个反爬机制
url = "https://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
ua=UserAgent()
headers={
"User-Agent":ua.ie
}
word=input("请输入你要查询的单词:")
import time
import random
from hashlib import md5
# 时间戳
lts=str(int(time.time()*1000))
print(lts)
#salt 根据时间戳生成的字符串
salt=lts+str(random.randint(0,9))
# 加密后的字符串
sign="fanyideskweb" + word + salt + "Ygy_4c=r#e#4EX^NUGUc5"
# 进行md5加密
s=md5()
s.update(sign.encode()) # md5加密必须是字节码
# 16进制加密
sign=s.hexdigest()
print(lts,salt,sign)
data = {
"i": word,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": salt,
"sign": sign,
"lts": lts,
"bv": "e8502234d005987c9adf93179232356e",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME"
}
resp = requests.post(url=url, data=data,headers=headers)
dataJson=resp.json()
print(dataJson)

其他
读取u盘的时候,显示磁盘结构损坏,且无法读取
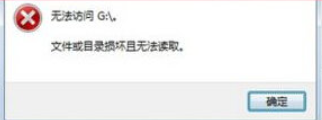
解决方法:
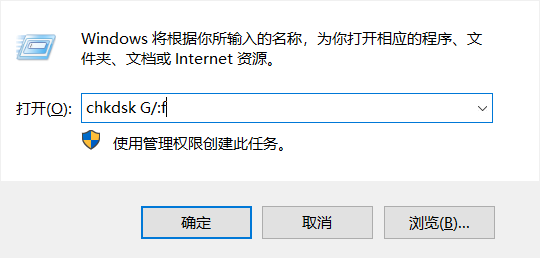
菜单+r 进入上面的界面:输入 chkdsk G/:F
G 是你的u盘的盘符
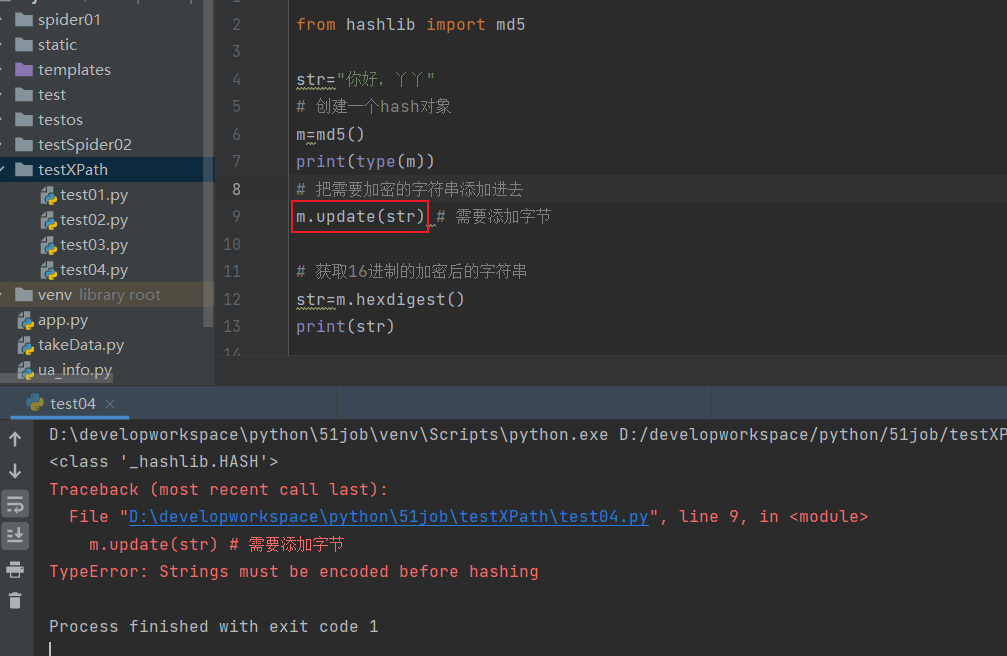
hashlib包
- 进行mad5加密
from hashlib import md5
str="你好,丫丫"
# 创建一个hash对象
m=md5()
print(type(m))
# 把需要加密的字符串添加进去
m.update(str.encode()) # 需要添加字节
# 获取16进制的加密后的字符串
str=m.hexdigest()
print(str)
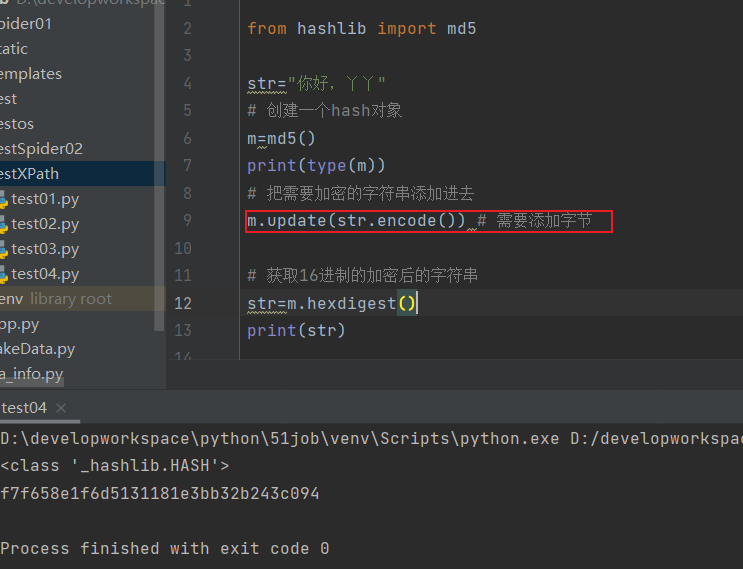
- 注意:在update(str) 添加的字符串必须转换成字节类型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号