
day23-python-spider
day23-python-spider
python
Requests库
简介
这个库的宗旨就是:让HTTP服务于人类
Requests库是再urllib的基础上开发而来的,它使用Python语言编写,并且采用了Apache2 Licensed(一种开源协议)的HTTP库。
于urllib相比,Requests更加方便、快捷,因此在编写爬虫程序时Requests库使用更多。
安装
pip install requests
常用的请求方法
requests.get()
res=requests.get(url,headers,params,timeout)
参数说明:
url:要爬取的url地址
headers:用于包装请求头信息
params:请求时携带的查询字符串参数
timeout:超出时间,超过请求时间就会抛出异常
params: 参数是一个字典
举例:
import requests
url="http://httpbin.org/get"
params={
'name':'编程帮',
'url':'www.bianchengbang.com'
}
resp=requests.get(url=url,params=params)
print(resp)
print(resp.text)

resp=requests.post(url,data={})
参数说明:
url:请求的url地址
data:请求的参数
例:
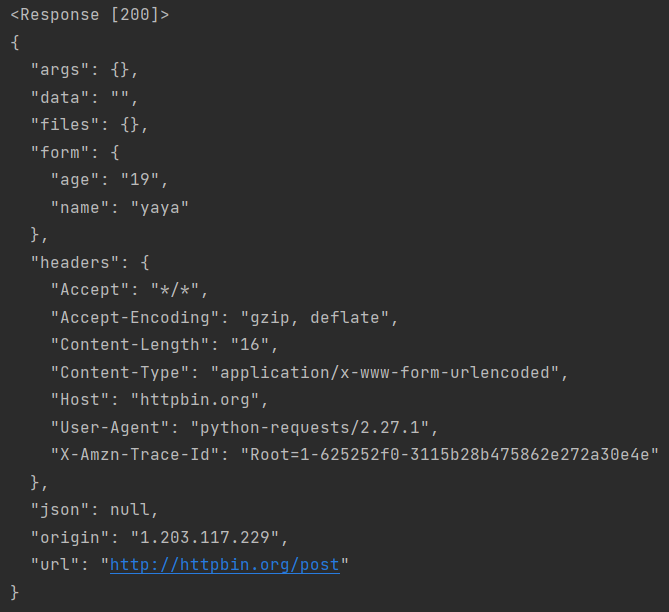
url="http://httpbin.org/post"
resp=requests.post(url,data={'name':'yaya','age':'19'})
print(resp)
print(resp.text)
Response对象属性
当我们使用Request模块向一个url发起一个请求后会返回一个HttpResponse响应对象,该对象具有的属性
| 常用属性 | 说明 |
|---|---|
| encoding | 查看或者指定响应字符的编码 |
| status_code | 返回HTTP响应码 |
| url | 查看请求的url |
| headers | 查看请求头信息 |
| cookies | 查看cookies信息 |
| text | 以字符串形式输出 |
| content | 以字节流形式输出,若要保存下载图片需使用该属性 |
代码
url="http://httpbin.org/post"
resp=requests.post(url,data={'name':'丫丫','age':'19'})
# print(resp)
# print(resp.text)
print(type(resp.encoding))
resp.encoding='utf-8' # 指定编码
print(resp.status_code) # 状态码
print(resp.url) # url
print(resp.cookies) # cookies
print(resp.content) # 流
Requests库的应用
使用Request库下载百度图片
代码:
import requests
from fake_useragent import UserAgent
ua=UserAgent()
headers={
"User-Agent":ua.firefox
}
imgurl='https://img2.baidu.com/it/u=2054474362,2445727683&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=500'
resp=requests.get(url=imgurl,headers=headers)
# 获取图片的信息
html=resp.content
print(type(html))
# print(html)
# 以二进制的方式写如文件中
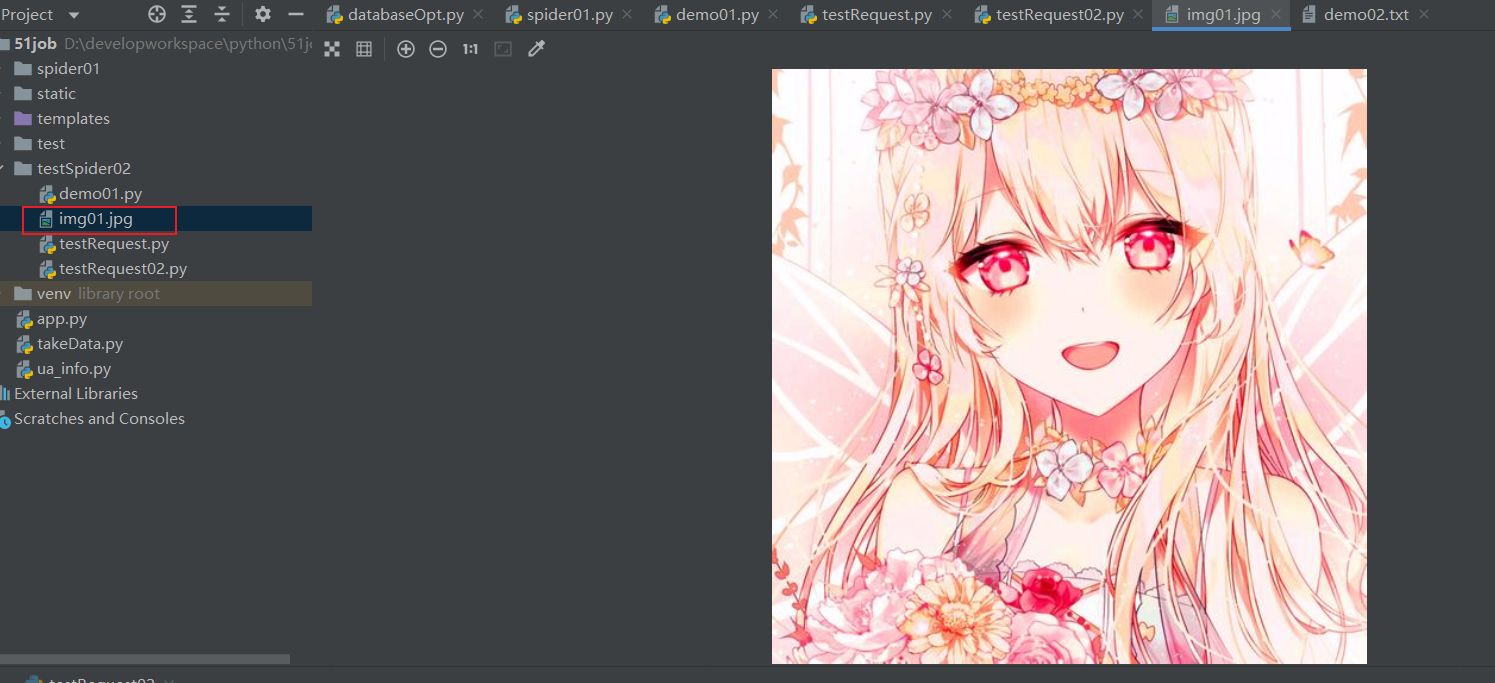
with open("img01.jpg","wb") as f:
f.write(html)
结果:
其他方法说明
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求对象,request |
| requests.get(req) | 通过get请求获取网页的信息 |
| requests.post(req) | 通过post请求获取网页的信息 |
| requests.head(req) | 获取网页的头信息 |
| request.put(req) | 通过put请求获取网页的信息 |
| request.patch(req) | 获取网页局部修改的信息 |
| request.delete(req) | 删除的请求 |
SSL认证-verify参数
SSL认证是数字证书的一种,类似于驾驶证、护照和营业执照。
因为配置在服务器上,也称为SSL服务器认证。
SSL证书遵循SSL协议,由受信任的数字证书颁发机构CA(电子认证服务)颁发。
SSL具有服务器身份验证和数据传输加密功能。
-
SSL(Secure Sockes Layer安全套接字协议),及其继任者传输层安全(Transport Layer Security,TLS)是为网络通信提供数据完整性的一种安全协议。TLS与SSL在传输层与应用层之间对网络连接进行加密。
-
verify参数的作用是检查SSL证书认证,参数的默认值为True,如果设置为False则表示不检查SSL证书,此参数适用于没有经过CA机构认证的HTTPS类型的网站。
-
格式
-
response=requests.request( url=url, params=params, headers=headers, verify=False )
-
代理IP-proxies参数
一些网站为了限制爬虫从而设置了很多反爬策略,之中一项就是针对IP地址设置的。比如网站超过规定次数导致流量异常或者某个时间段频繁地更换浏览器访问,存在上述行为的IP极有可能被网站封杀掉。
代理IP就是解决上述问题的,它突破了IP地址的访问限制,隐藏了本地网络的真实IP,而使用第三方IP代替自己去访问网站。
代理IP池
通过构建代理 IP 池可以让你编写的爬虫程序更加稳定,从 IP 池中随机选择一个 IP 去访问网站,而不使用固定的真实 IP。总之将爬虫程序伪装的越像人,它就越不容易被网站封杀。当然代理 IP 也不是完全不能被察觉,通过端口探测技等术识仍然可以辨别。其实爬虫与反爬虫永远相互斗争的,就看谁的技术更加厉害。
proxies参数
-
Requests提供了一个代理IP参数proxies
-
格式
-
proxies={ '协议类型(http/https)':'协议类型://IP地址:端口号', ... }
-
代理IP的使用
代码:
import requests
from fake_useragent import UserAgent
url = "http://httpbin.org/get"
ua = UserAgent()
headers = {
'User-Agent': ua.ie
}
proxies = {
"http": "http://115.218.2.167:9000",
"http": "http://103.37.141.69:80"
}
resp = requests.get(url=url, headers=headers,proxies=proxies)
html = resp.text
print(html)
付费代理
网上有许多提供代理 IP 服务的网 站,比如快代理、代理精灵、齐云代理等。这些网站也提供了相关文档说明,以及 API 接口,爬虫程序通过访问 API 接口,就可以构建自己的代理 IP 池。
付费代理 IP 按照资源类型可划分为:开发代理、私密代理、隧道代理、独享代理,其中最常使用的是开放代理与私密代理。
- 开发代理:开放代理是从公网收集的代理服务器,具有 IP 数量大,使用成本低的特点,全年超过 80% 的时间都能有 3000 个以上的代理 IP 可供提取使用。
- 私密代理:私密代理是基于云主机构建的高品质代理服务器,为您提供高速、可信赖的网络代理服务。
用户认证-auth参数
Requests提供了一个auth参数,该参数的支持用户认证功能,也就是适合那些需要验证用户名,密码的网站
-
格式
-
auth=('username','password')
-
-
范例
-
import requests from fake_useragent import UserAgent url = "http://code.tarena.com.cn/AIDCode/aid1906/13Redis/" ua = UserAgent() headers = { 'User-Agent': ua.ie } # 代理ip proxies = { "http": "http://115.218.2.167:9000", "http": "http://103.37.141.69:80" } # 网站使用的用户名和密码 auth = ('c语言中文网', 'c.biancheng.net') resp = requests.get(url=url, headers=headers, auth=auth) html = resp.text print(html)
-
Xpath
简介
XPath(XML Path Language):XML路径语言,他是一门在XML文档中查找信息的语言,最初被用来搜索XML文档,同时也适用于搜索html文档。
XML是一种遵循W3C标准的标记语言,类似于html,但两者的设计目的是不同的,XML通常被用来传输和存储数据,而Html常用来显示数据。
XPath在html和XML文件中检索、匹配元素节点的工具
XPath节点
xml文档
<?xml version="1.0" encoding="utf-8"?>
<website>
<site>
<title lang="zh-CN">website name</title>
<name>编程帮</name>
<year>2010</year>
<address>www.biancheng.net</address>
</site>
</website>
节点
<website></website> 文档节点
<site></site> 元素节点
lang="zh-CN" 属性节点
XPath基本语法
路径表达式
| 表达式 | 描述 |
|---|---|
| node_nane | 选取此节点的所有子节点 |
| / | 绝对路径匹配 |
| // | 相对路径匹配,从所有节点中查找当前选择的节点,包括子节点和后代节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性,通过属性值选取数据。@属性名 |
XPath通配符
| 通配符 | 描述 |
|---|---|
| * | 匹配任意元素节点 |
| @* | 匹配任意属性节点 |
| node() | 匹配任意类型的节点 |
XPath内建函数
| 函数名称 | xpath表达式示例 | 示例说明 |
|---|---|---|
| text() | ./text() | 文本匹配,表示值取当前节点中的文本内容。 |
| contains() | //div[contains(@id,'stu')] | 模糊匹配,表示选择 id 中包含“stu”的所有 div 节点。 |
| last() | //*[@class='web'] [last()] | 位置匹配,表示选择@class='web'的最后一个节点。 |
| position() | //*[@class='site'] [position()<=2] | 位置匹配,表示选择@class='site'的前两个节点。 |
| start-with() | "//input[start-with(@id,'st')]" | 匹配 id 以 st 开头的元素。 |
| ends-with() | "//input[ends-with(@id,'st')]" | 匹配 id 以 st 结尾的元素。 |
| concat(string1,string2) | concat('C语言中文网',.//*[@class='stie']/@href) | C语言中文与标签类别属性为"stie"的 href 地址做拼接。 |
lxml库
lxml使用
-
导入模板
-
lxml提供了etree模块,此模块专门用来解析HTML/XML
-
from lxml import etree
-
-
创建解析对象
-
parseHtml=etree.HTML(html)
-
-
调用xpath表达式
-
rlist=parseHtml.xpath('xpath表达式')
-
实例
from lxml import etree
import requests
from fake_useragent import UserAgent
# 要爬取的url
url="https://movie.douban.com/top250"
# 伪造headerss
ua=UserAgent()
headers={
"User-Agent":ua.firefox
}
# 获取响应对象
resp=requests.get(url=url,headers=headers)
html=resp.text
# print(html)
# 创建解析对象
parseHtml=etree.HTML(html)
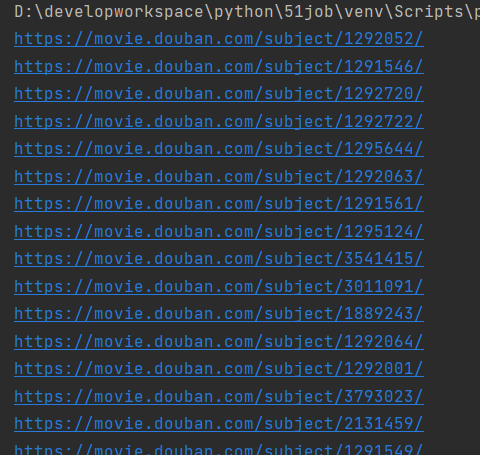
# 获取电影详情链接
xpathBds='//div[@class="pic"]/a/@href'
title=parseHtml.xpath(xpathBds)
# 获取电影
for url in title:
print(url)
其他
状态码
200 请求成功
日期和时间
Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间。
time
常用方法
time.time() 获取当前时间的秒的浮点数表示
time.localtime() 获取当前时间的元组
time.asctime() 获取格式化的时间
time.strftime(format,[t]) 格式化日期
代码
import time
print(time.time())
print(time.localtime())
print(time.asctime())
week=["日","一","二","三","四","五","六"]
print(time.strftime(f"%Y-%m-%d %H:%M:%S %A "))

calendar库
处理年历和月历
os库
处理文件和目录的库
常用方法
os.chdir(path) 改变当前工作目录
os.getcwd() 返回当前的工作目录
os.link(src,dst) 创建硬连接,名为dst,指向参数src
os.symlink(src,dest) 创建软连接
os.listdir(path) 返回path指定的文件夹包含的文件或文件夹的名字的列表
os.makedirs(path,[mode]) 递归创建文件夹
os.mkdir(path,[mode]) 创建一个名为path的文件夹,默认的mode是0777(八进制)
os.open(file,flags,[mode]) 打开文件
os.remove(path) 删除路径为path的文件
os.removedirs(path) 递归删除目录
os.rename(src,dst) 重命名文件或目录,从src到dst
os.rmdir(path) 删除path指定的空目录,如果不是空目录,则抛出一个OSError异常
os.pardir() 获取当前目录的父目录
文件描述符
内核(kernel)利用文件描述符(file descriptor)来访问文件。文件描述符是非负整数。打开现存文件或新建文件时,内核会返回一个文件描述符。读写文件也需要使用文件描述符来指定待读写的文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号