
day15-zookeeper
day15-zookeeper
zookeeper
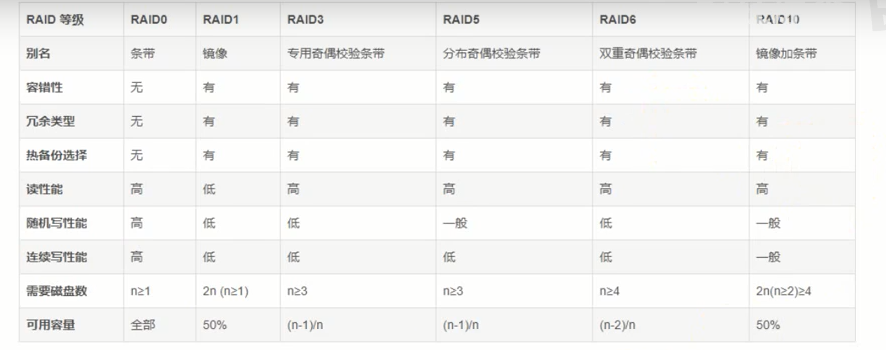
RAID等级
paxos算法
简介
- Paxos算法是Leslie Lamport宗师提出的一种基于消息传递的分布式一致性算法,使其获得2013年图灵奖。
- Paxos在1990年提出,被广泛应用分布式计算中,Google的Chubby,Apache的Zookeeper都是基于它的理论来实现的。
- Paxos算法解决的问题是分布式一致性问题,即一个分布式系统中的各个进程如何就某个值达成一致。
- 传统节点间通信存在着两种通讯模型:共享内存(Shared memory)、消息传递(Message passing),Paxos是一个基于消息传递的一致性算法。
算法描述

Paxos推断
- 小岛(Island)服务器集群
- 议员(Senator)单台服务器
- 议员的总数(Senator Count)是确定的
- 提议(Proposal)每一次对集群中的数据进行修改
- 每个提议都有一个编号(PID),这个编号是一直增长的
- 每个提议都需要超过半数((Senator Count)/2+1)的议员同意才能生效
- 每个议员只会同意大于当前编号的提议
- 每个议员在自己记事本上面记录的编号,它不断更新这个编号
- 整个议会不能保证所有议员记事本上的编号总是相同的
- 议会有一个目标(>1/2),后期广播(all)
- Paxos算法
- 数据的全量备份
- 弱一致性----》最终一致性
算法模型延申

无主集群模型
- 人人都会发送指令,投票
- 投票人数有可能导致分区(分不同阵营)
- 6个节点 33对立
- 类似于以前党争
- 事务编号混乱,每个节点都有可能有自己的提议
- 提议的编号不能重复和小于
- 投票人数有可能导致分区(分不同阵营)
- 有主集群模型
- 只能有一个主发送指令,发送提议
- 单主会单点故障,肯定有备用的方案
- 重新选举
- 切换到备用节点
- 如果存在多个主就会脑裂
- 主要集群中节点数目高于1/2+1,集群就可以正常运行
Raft算法
简介
- Raft适用于一个管理日志一致性协议,相比Paxos协议Raft更易于理解和实现它。
- Raft将一致性算法分为了几个部分,包括领导选取(leader selection)、日志复制(log replication)、安全(safety)
- http://thesecretlivesofdata.com/raft
问题
- 分布式存储系统通过维持多个副本来提高系统的availability,难点在于分布式存储系统的核心问题:
- 维护多个副本的一致性
- Raft协议基于复制状态机(replicated state machine)
- 一组server从相同的初始状态起,按相同的顺序执行相同的命令,最终会达到一致的状态
- 一组server记录相同的操作日志,并以相同的顺序应用到状态机
- Raft有一个明确的场景,就是管理复制日志的一致性。
- 每台机器保存一份日志,日志来自于客户端的请求,包含一些列的命令,状态机会按顺序执行这些命令
-
角色分配
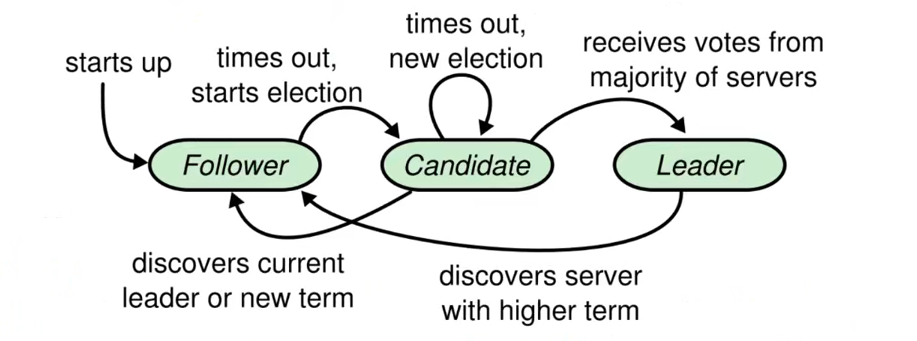
- Raft算法将Server划分为3中状态,或者也可以称作角色:
- Leader
- 负责Client交互和log复制,同一时刻系统中最多存在1个
- Follower
- 被动响应请求RPC,从不主动发起请求RPC
- Candidate
- 一种临时的角色,只存在于leader的选举阶段,某个节点想要变成leader那么就发起投票请求,同时自己变成candidate
- Leader
算法流程
-
Term
- Term的概念类比中国历史上的朝代更替,Raft算法将时间划分成为任意不同长度的任期(term)
- 任期用连续的数据进行表示。每一个任期的开始都是一次选举(election),一个或多个候选人会视图称为领导人。如果一个候选人赢得了选举,他就会在该任期的剩余时间担任领导人。在某些情况下,选 票会被瓜分,有可能么有选出领导人,那么,将会开始另一个任期,并且立刻开始下一次选举。Raft算法保证在给定的一个任期最多只有一个领导人
-
RPC
- Raft算法中服务器节点之间通信使用远程过程调用(RPCs)
- 基本的一致性算法只需要两种类型的RPCs,为了在服务器之间传输快照增加了第三种RPC
- RequestVote RPC:候选人在选举期间发起
- AppendEntries RPC:领导人发起的一种心跳机制,复制日志也在该命令中完成
- InstallSnapshot RPC:领导者使用该RPC来发送快照给太落后的追随者
-
日志复制(Log Replication)
- 主要用于保证节点的一致性,这阶段所作的操作也是为了保证一致性与高可用性
- 当Leader选举出来后便开始负责客户端的请求,所有事务(更新操作)请求都必须先经过Leader处理
- 日志复制(Log Replication)就是为了保证执行相同的操作序列所做的工作
- 在Raft中当接受到客户端的日志(事务请求)后先把该日志追加到本地的Log中
- 然后通过heartbeat把该Entry同步给其他Follower,Follower接收到日之后记录日志,然后向LEader发送ACK
- 当Leader收到大多数(n/2+1)Follower的ACK信息后将该日志设置为已提交并追加到本地磁盘中
- 通知客户端并在下个heartbeat中Leader将通知所有的Follower将该日志存储在自己的本地磁盘中。
Zookeeper
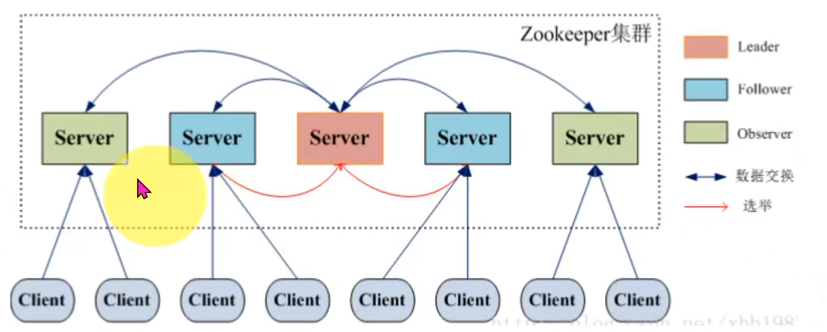
角色分配
- 小岛-ZK Server Cluster
- 总统-ZK Server Leader
- 集群中所有修改数据的执行必须由总统发出
- 总统是由议员投票产生的(无主-->有主)
- 选举条件
- 首先按照事务zxid进行排序
- 如果事务相同按照myid排序
- 议员(Senator)-ZK server Learner
- 接受客户端请求
- 查询直接返回结果(有可能数据不一致)
- 写入数据,先将数据写入到当前server
- 发送消息给总统,总统将修改数据的命令发送给其他server
- 其他server接受命令后开始修改数据,修改完成后给总统返回成功的消息
- 当总统发现超过半数的人都修改成功,就认为修改成功了
- 并将信息传递给接受请求的zkServer,zkServer将消息返回给客户端,说明数据更新完成
- 分类Learner
- Follower
- 拥有选举权
- 拥有投票权
- 接受客户端的访问
- Observer
- 只可以为客户端提供数据的查询和访问
- 如果客户端进行写请求,只是将请求转发给Leader
- Follower
- 接受客户端请求
- 提议(Proposal)-Znode-Change
- 客户端的提议会被封装成一个节点挂载到一个Zookeeper维护的目录树上面
- 我们可以对数据进行访问(绝对路径)
- 数据量不能超过1M
- 提议编号(PID)-Zxid
- 会按照数据序列递增,不会减少不会重复
- 正式法令- 所有Znode及其数据
- 超过半数的服务器更新这个数据,就说明数据已经是正式的了
- 屁民--Client
- 发送请求(查询请求,修改请求)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号