数据结构与算法-5 数据库索引 B+树
目录
48 | B+ 树
为了加速数据库中数据的查找速度,我们常用的处理思路是,对表中数据创建索引,那数据库索引是如何实现的呢?底层使用的是什么数据结构和算法呢?
问题:数据库的索引是如何实现的
这里我们假设要解决的问题,只包含这样两个常用的需求:
- 根据某个
值查找数据,比如select * from user where id=1234 - 根据
区间值来查找某些数据,比如select * from user where id > 1234 and id < 2345
对于非功能性需求,我们着重考虑执行效率和存储空间:
- 在执行效率方面,我们希望通过索引,查询数据的效率尽可能地高
- 在存储空间方面,我们希望索引不要消耗太多的内存空间
散列表、二叉查找树、跳表实现方案
支持快速查询、插入等操作的动态数据结构,我们已经学习过散列表、平衡二叉查找树、跳表。
-
散列表:散列表的查询性能很好,时间复杂度是
O(1)。但是,散列表不能支持按照区间快速查找数据。所以,散列表不能满足我们的需求。 -
平衡二叉查找树:尽管平衡二叉查找树查询的性能也很高,时间复杂度是
O(logn)。而且,对树进行中序遍历,我们还可以得到一个从小到大有序的数据序列,但这仍然不足以支持按照区间快速查找数据。 -
跳表:跳表是在
链表之上加上多层索引构成的。它支持快速地插入、查找、删除数据,对应的时间复杂度是O(logn)。并且,跳表也支持按照区间快速地查找数据。我们只需要定位到区间起点值对应在链表中的结点,然后从这个结点开始,顺序遍历链表,直到区间终点对应的结点为止,这期间遍历得到的数据就是满足区间值的数据。
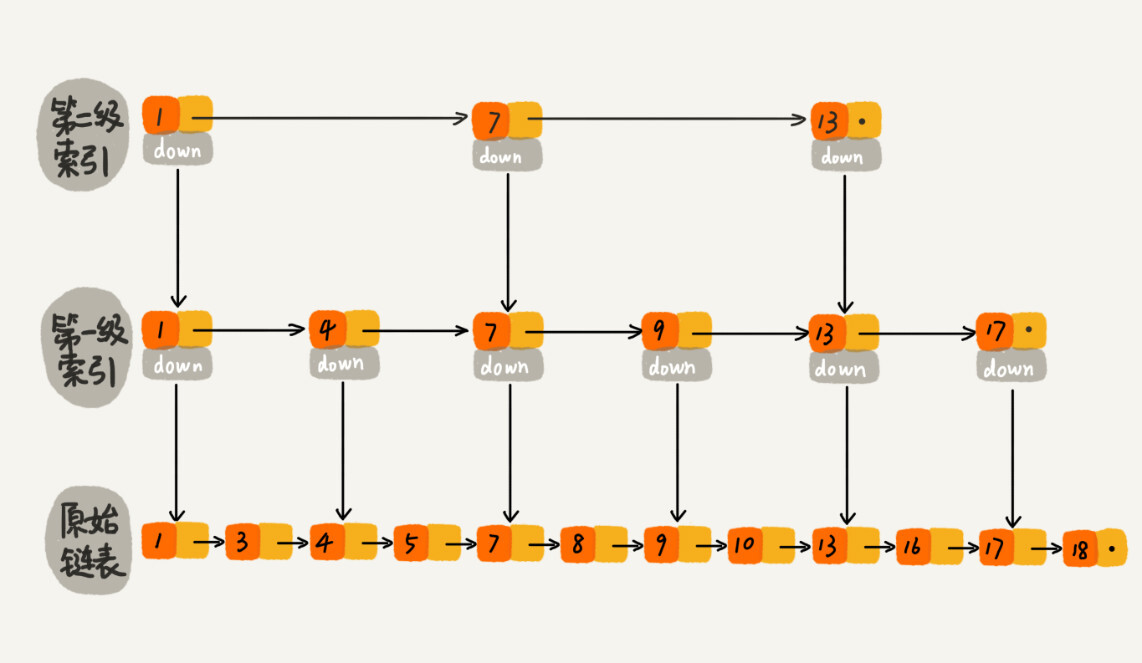
这样看来,跳表是可以解决这个问题。实际上,数据库索引所用到的数据结构跟跳表非常相似,叫作 B+ 树。不过,它是通过二叉查找树演化过来的,而非跳表。
B+ 树的演化过程
B+ 树是通过二叉查找树演化过来的,而非跳表。下面我们从就二叉查找树讲起,看它是如何一步一步被改造成 B+ 树的。
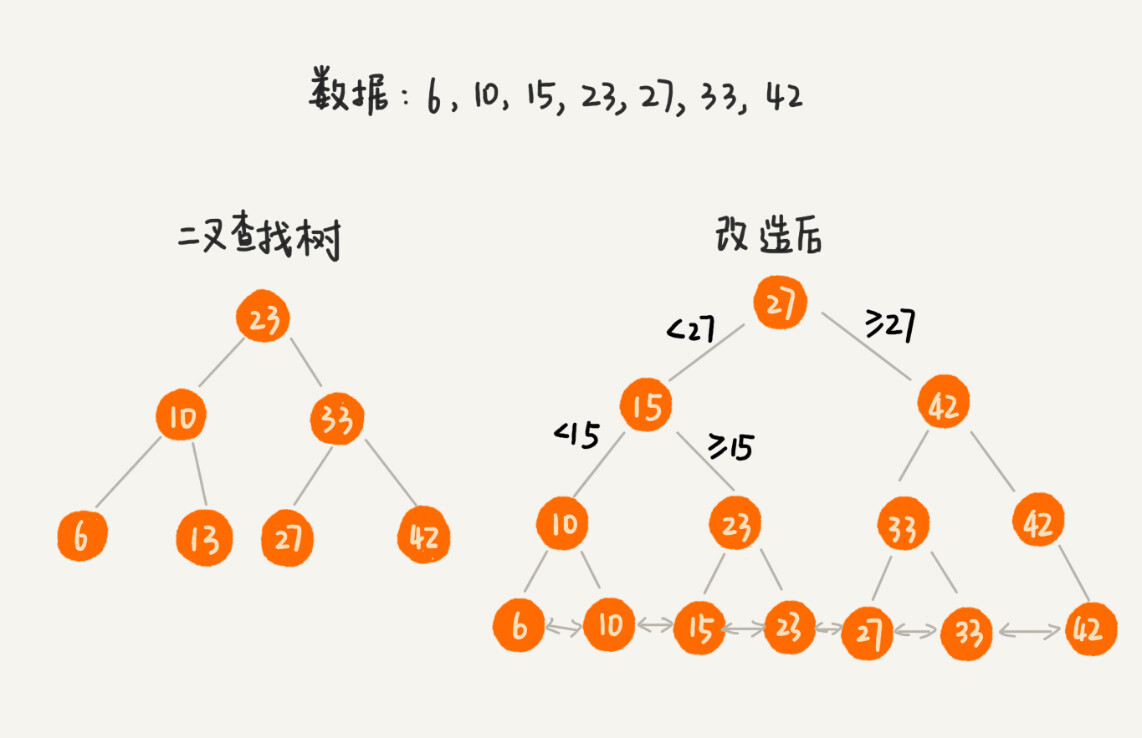
改造二叉查找树
为了让二叉查找树支持按照区间来查找数据,我们可以对它进行这样的改造:
- 树中的节点并不存储数据本身,而是只是作为索引
- 除此之外,我们把每个叶子节点串在一条链表上,链表中的数据是从小到大有序的。
经过改造之后的二叉树,就像图中这样,看起来是不是很像跳表呢?
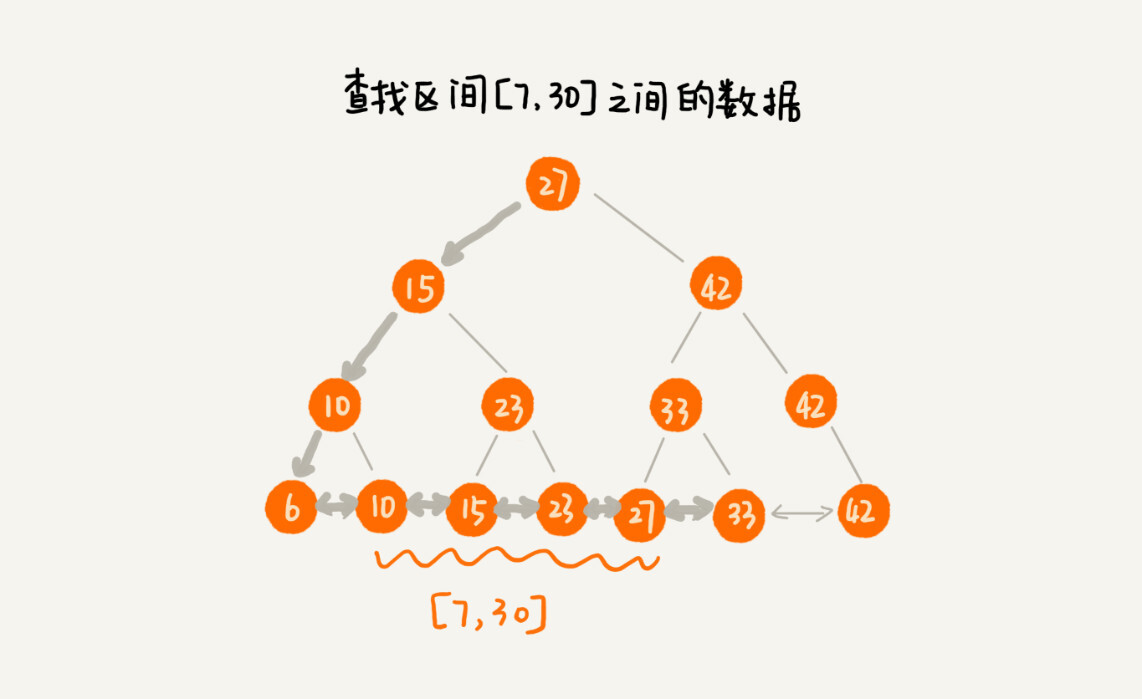
改造之后,如果我们要求某个区间的数据:
- 我们只需要拿区间的起始值,在树中进行查找
- 当查找到某个叶子节点之后,我们再顺着链表往后遍历,直到链表中的结点数据值大于区间的终止值为止
- 所有遍历到的数据,就是符合区间值的所有数据
占内存问题优化
但是,我们要为几千万、上亿的数据构建索引,如果将索引存储在内存中,尽管内存访问的速度非常快,查询的效率非常高,但是,占用的内存会非常多。
比如,我们给一亿个数据构建二叉查找树索引,那索引中会包含大约 1 亿个节点,每个节点假设占用 16 个字节,那就需要大约 1GB 的内存空间。给一张表建立索引,我们需要 1GB 的内存空间。如果我们要给 10 张表建立索引,那对内存的需求是无法满足的。如何解决这个索引占用太多内存的问题呢?
我们可以借助时间换空间的思路,把索引存储在硬盘中,而非内存中。我们都知道,硬盘是一个非常慢速的存储设备。通常内存的访问速度是纳秒级别的,而磁盘访问的速度是毫秒级别的。读取同样大小的数据,从磁盘中读取花费的时间,是从内存中读取所花费时间的上万倍,甚至几十万倍。
这种将索引存储在硬盘中的方案,尽管减少了内存消耗,但是在数据查找的过程中,需要读取磁盘中的索引,因此数据查询效率就相应降低很多。
IO 操作慢问题优化
二叉查找树,经过改造之后,支持区间查找的功能就实现了。不过,为了节省内存,如果把树存储在硬盘中,那么每个节点的读取(或者访问),都对应一次磁盘 IO 操作。树的高度就等于每次查询数据时磁盘 IO 操作的次数。
我们前面讲到,比起内存读写操作,磁盘 IO 操作非常耗时,所以我们优化的重点就是尽量减少磁盘 IO 操作,也就是,尽量降低树的高度。那如何降低树的高度呢?
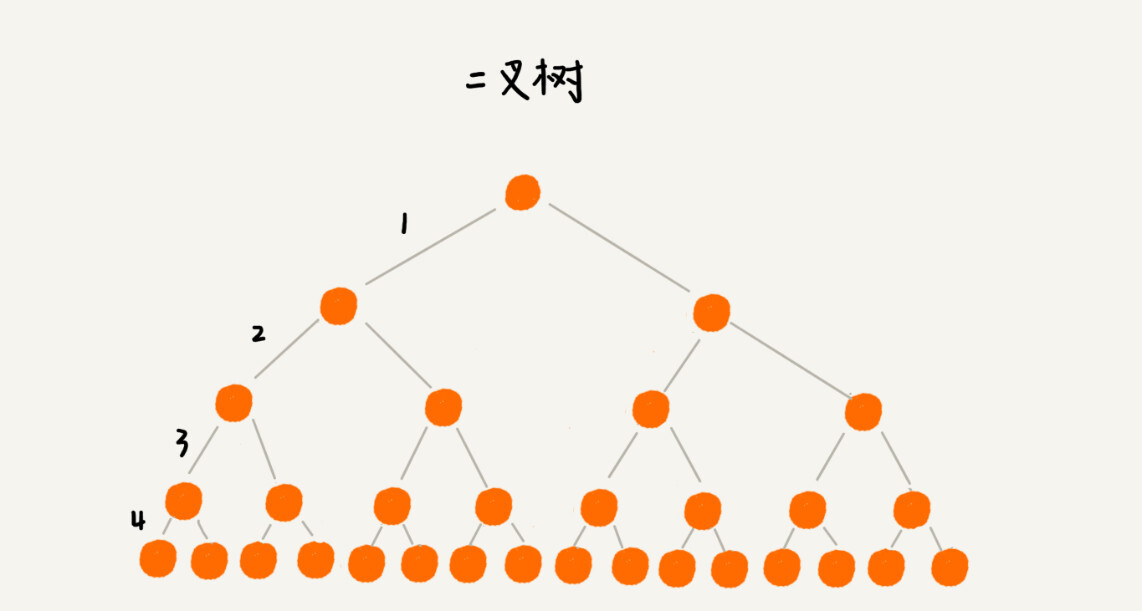
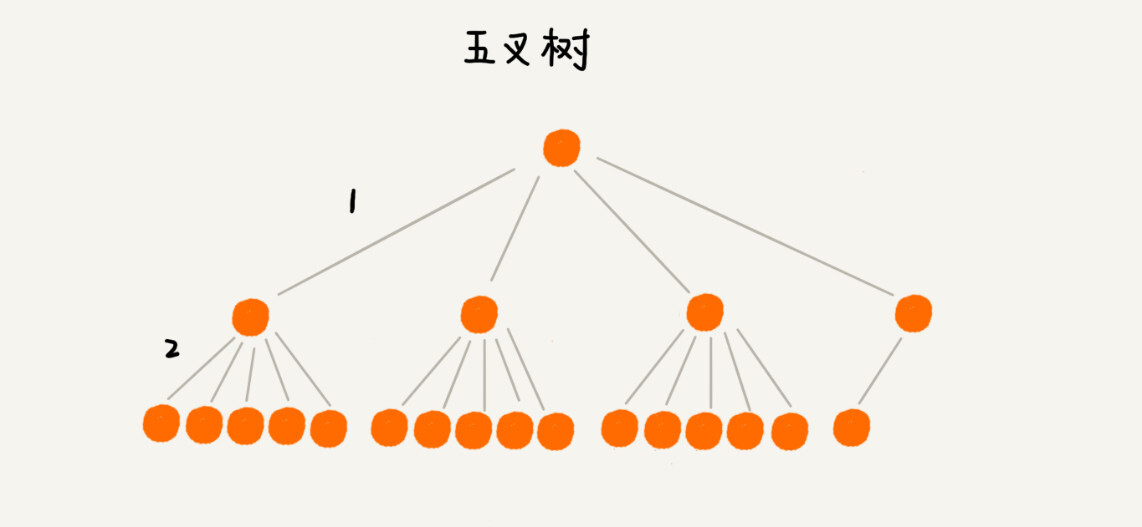
我们来看下,如果我们把索引构建成 m 叉树,高度是不是比二叉树要小呢?
如图所示,假设根节点存储在内存中,其他节点存储在磁盘中:
- 如果给 16 个数据构建二叉树索引,树的高度是 4,查找一个数据,就需要 4 次磁盘 IO 操作
- 如果对 16 个数据构建五叉树索引,那高度只有 2,查找一个数据,对应只需要 2 次磁盘操作
- 如果 m 叉树中的 m 是 100,那对一亿个数据构建索引,树的高度也只是 3,最多只要 3 次磁盘 IO 就能获取到数据
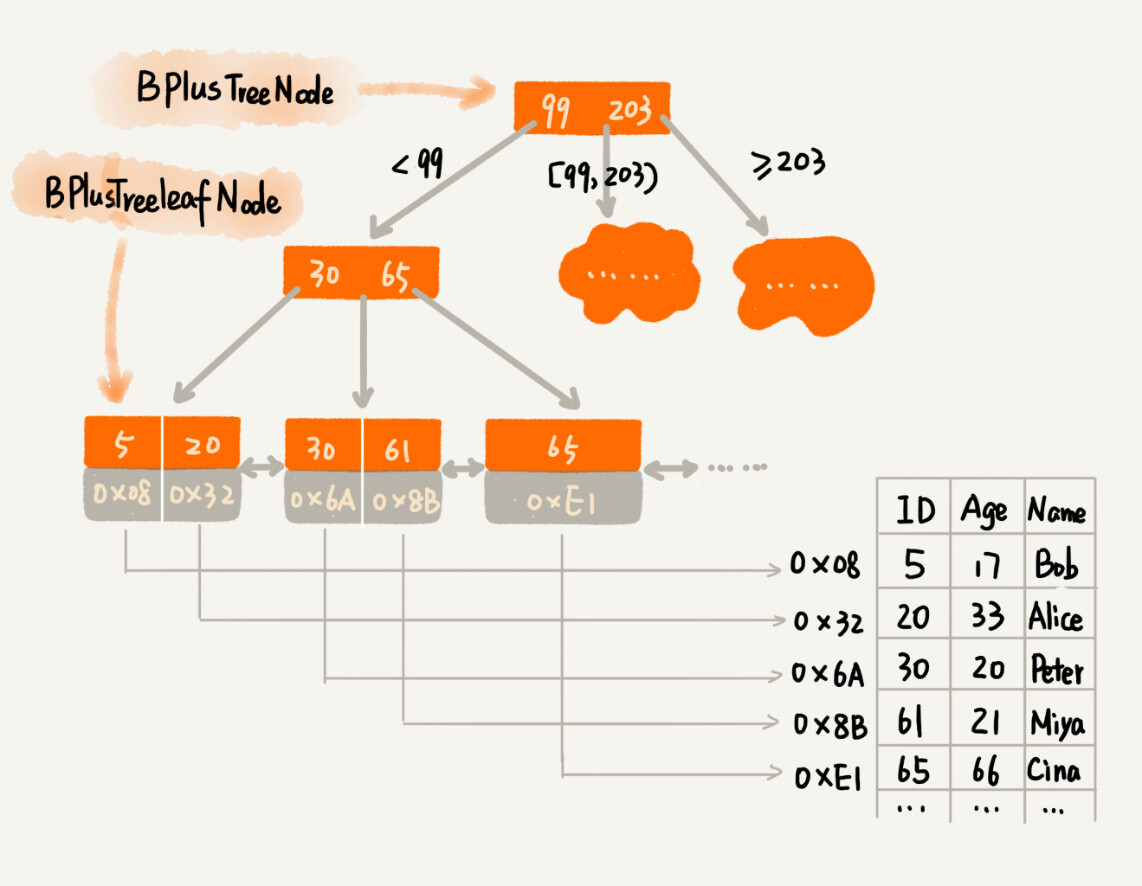
B+ 树的代码定义
如果我们将 m 叉树实现 B+ 树索引,用代码实现出来,就是下面这个样子。
假设我们给 int 类型的数据库字段添加索引,所以代码中的 keywords 是 int 类型的
B+ 树非叶子节点的定义
假设 keywords=[3, 5, 8, 10]
- 4 个键值将数据分为 5 个区间:
(-INF,3),[3,5),[5,8),[8,10),[10,INF) - 5 个区间分别对应:
children[0]...children[4]
m 值是事先计算得到的,计算的依据是让所有信息的大小正好等于页(PAGE)的大小:
PAGE_SIZE = (m-1) * 4[keywordss大小] + m * 8[children大小]
4 是用来划分区间的 int 数组每个成员大小,m 叉树,所以要 m-1 个数来划分这些节点的大小值
8 是非叶子节点的指针类型大小,m 叉树,则有 m 个 children
class BPlusTreeNode {
public static int m = 5; // 5 叉树
public int[] keywords = new int[m - 1]; // 键值,用来划分数据区间
public BPlusTreeNode[] children = new BPlusTreeNode[m]; // 保存子节点指针
}
B+ 树叶子节点的定义
B+ 树中的叶子节点跟内部节点是不一样的,叶子节点存储的是值,而非区间。
每个叶子节点存储 3 个数据行的键值及地址信息。
k 值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:
PAGE_SIZE = k * 4[keyw..大小] + k * 8[dataAd..大小] + 8[prev大小] + 8[next大小]
class BPlusTreeLeafNode {
public static int k = 3;
public int[] keywords = new int[k]; // 数据的键值
public long[] dataAddress = new long[k]; // 数据地址
public BPlusTreeLeafNode prev; // 这个结点在链表中的前驱结点
public BPlusTreeLeafNode next; // 这个结点在链表中的后继结点
}
m 叉树的最佳设计实践
对于相同个数的数据构建 m 叉树索引,m 叉树中的 m 越大,那树的高度就越小,那 m 叉树中的 m 是不是越大越好呢?到底多大才最合适呢?
不管是内存中的数据,还是磁盘中的数据,操作系统都是按页(一页大小通常是 4KB,这个值可以通过 getconfig PAGE_SIZE 命令查看)来读取的,一次只会读一页的数据。如果要读取的数据量超过一页的大小,就会触发多次 IO 操作。所以,我们在选择 m 大小的时候,要尽量让每个节点的大小等于一个页的大小。读取一个节点,只需要一次磁盘 IO 操作。
索引会导致写入、删除变慢
尽管索引可以提高数据库的查询效率,但是,索引有利也有弊,它也会让写入、删除数据的效率下降。这是为什么呢?
写入变慢的原因
数据的写入过程,会涉及索引的更新,这是索引导致写入变慢的主要原因。
对于一个 B+ 树来说,m 值是根据页的大小事先计算好的,也就是说,每个节点最多只能有 m 个子节点。在往数据库中写入数据的过程中,这样就有可能使索引中某些节点的子节点个数超过 m,这个节点的大小超过了一个页的大小,读取这样一个节点,就会导致多次磁盘 IO 操作。
为了解决这个问题,我们只需要将这个节点分裂成两个节点即可。但是,节点分裂之后,其上层父节点的子节点个数就有可能超过 m 个。不过这也没关系,我们可以用同样的方法,将父节点也分裂成两个节点。这种级联反应会从下往上,一直影响到根节点。
分裂过程图解:
- 图中的 B+ 树是一个三叉树
- 限定叶子节点中,数据的个数超过 2 个就分裂节点
- 限定非叶子节点中,子节点的个数超过 3 个就分裂节点
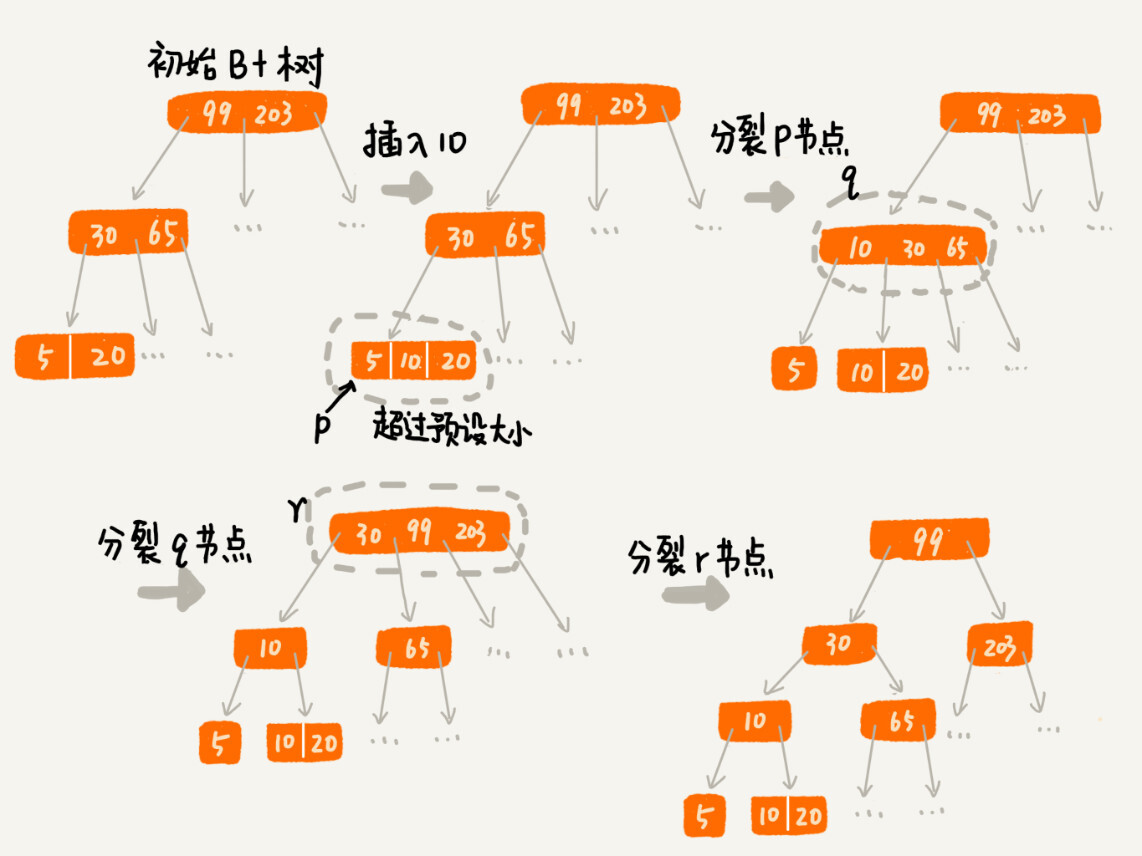
正是因为要时刻保证 B+ 树索引是一个 m 叉树,所以,索引的存在会导致数据库写入的速度降低。
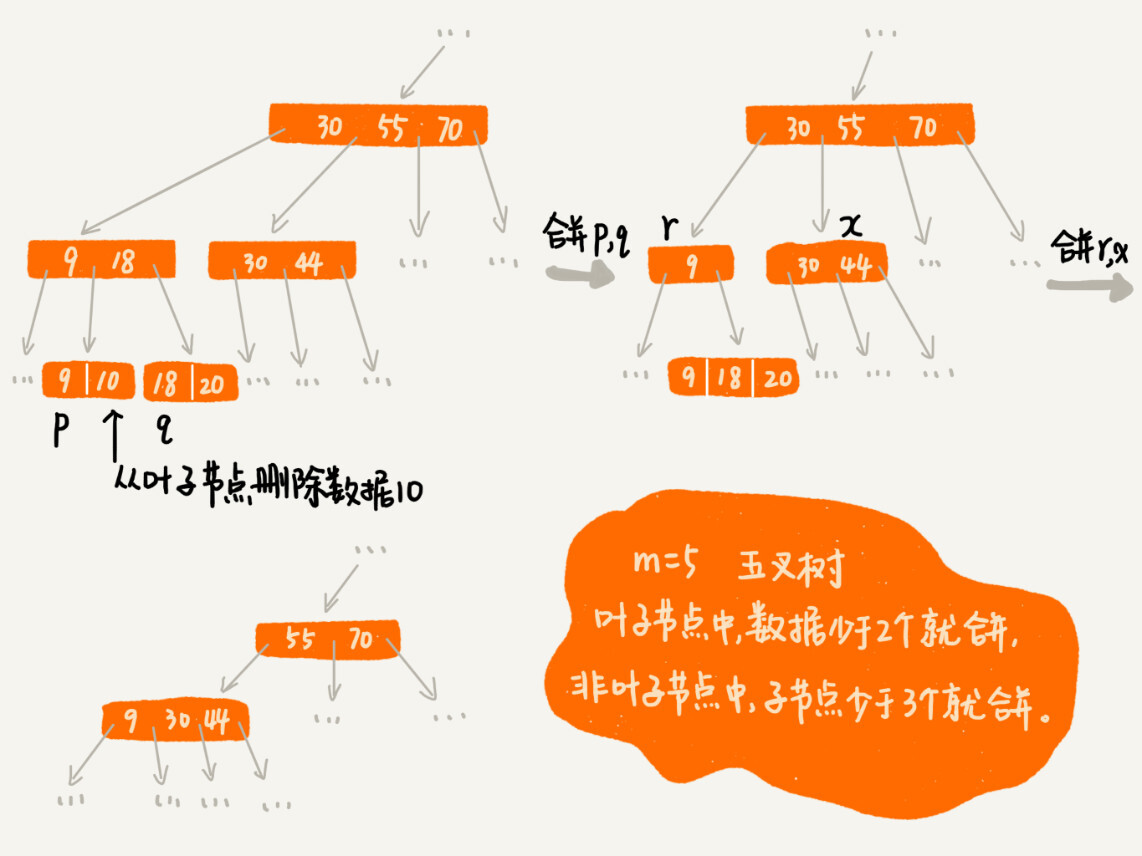
删除变慢的原因
我们在删除某个数据的时候,也要对应地更新索引节点。这个处理思路有点类似跳表中删除数据的处理思路。频繁的数据删除,就会导致某些节点中子节点的个数变得非常少,长此以往,如果每个节点的子节点都比较少,势必会影响索引的效率。
我们可以设置一个阈值。在 B+ 树中,这个阈值等于 m/2。如果某个节点的子节点个数小于 m/2,我们就将它跟相邻的兄弟节点合并。不过,合并之后节点的子节点个数有可能会超过 m。针对这种情况,我们可以借助插入数据时候的处理方法,再分裂节点。
删除过程图解:
- 图中的 B+ 树是一个五叉树
- 限定叶子节点中,数据的个数少于 2 个就合并节点
- 限定非叶子节点中,子节点的个数少于 3 个就合并节点
数据库索引以及 B+ 树的由来,到此就讲完了。你有没有发现,B+ 树的结构和操作,跟跳表非常类似。理论上讲,对跳表稍加改造,也可以替代 B+ 树,作为数据库的索引实现的。
B+ 树发明于 1972 年,跳表发明于 1989 年,我们可以大胆猜想下,跳表的作者有可能就是受了 B+ 树的启发,才发明出跳表来的。
总结引申
今天,我们讲解了数据库索引的实现,它依赖的底层数据结构是 B+ 树,它通过存储在磁盘的多叉树结构,做到了时间、空间的平衡,既保证了执行效率,又节省了内存。
B+ 树和跳表适用场景的区别:B+ 树主要是用在外部存储上,为了减少磁盘 IO 次数(客户端场景);跳表比较适合内存存储(服务器场景)。
B+ 树的特点:
- 每个节点中子节点的个数不能超过 m,也不能小于 m/2
- 根节点的子节点个数可以不超过 m/2,这是一个例外
- m 叉树只存储索引,并不真正存储数据,这个有点儿类似跳表
- 通过链表将叶子节点串联在一起,这样可以方便按区间查找
- 一般情况,根节点会被存储在内存中,其他节点存储在磁盘中
除了 B+ 树,你可能还听说过 B 树、B- 树:
- 实际上,B- 树就是 B 树,英文翻译都是
B-Tree,这里的-并不是相对 B+ 树中的+,而只是一个连接符 - 而 B 树实际上是低级版的 B+ 树,或者说 B+ 树是 B 树的改进版
B 树跟 B+ 树的不同点主要集中在这几个地方:
- B+ 树中的节点不存储数据,只是索引,而 B 树中的节点存储数据
- B 树中的叶子节点并不需要链表来串联
- B 树只是一个每个节点的子节点个数不能小于 m/2 的 m 叉树
50 | 索引
在第 48 节中,我们讲了 MySQL 数据库索引的实现原理。MySQL 底层依赖的是 B+ 树这种数据结构。那类似 Redis 这样的 Key-Value 数据库中的索引,又是怎么实现的呢?底层依赖的又是什么数据结构呢?
今天,我就来讲一下,索引这种常用的技术,底层往往会依赖哪些数据结构。同时,通过索引这个应用场景,我也带你回顾一下,之前我们学过的几种支持动态集合的数据结构。
为什么需要索引
在实际的软件开发中,业务纷繁复杂,功能千变万化,但是,万变不离其宗。如果抛开这些业务和功能的外壳,其实它们的本质都可以抽象为“对数据的存储和计算”。对应到数据结构和算法中,那“存储”需要的就是数据结构,“计算”需要的就是算法。
对于存储的需求,功能上无外乎增删改查。这其实并不复杂。但是,一旦存储的数据很多,那性能就成了这些系统要关注的重点,特别是在一些跟存储相关的基础系统(比如 MySQL 数据库、分布式文件系统等)、中间件(比如消息中间件 RocketMQ 等)中。
如何节省存储空间、如何提高数据增删改查的执行效率,这样的问题就成了设计的重点。而这些系统的实现,都离不开一个东西,那就是索引。不夸张地说,索引设计得好坏,直接决定了这些系统是否优秀。
索引这个概念,非常好理解。你可以类比书籍的目录来理解。如果没有目录,我们想要查找某个知识点的时候,就要一页一页翻。通过目录,我们就可以快速定位相关知识点的页数,查找的速度也会有质的提高。
索引的需求定义
索引的概念不难理解,我想你应该已经搞明白。接下来,我们就分析一下,在设计索引的过程中,需要考虑到的一些因素,换句话说就是,我们该如何定义清楚需求呢?
对于系统设计需求,我们一般可以从功能性需求和非功能性需求两方面来分析。
功能性需求
对于功能性需求需要考虑的点,我把它们大致概括成下面这几点。
-
数据是格式化数据还是非格式化数据?要构建索引的原始数据,类型有很多。我把它分为两类,一类是结构化数据,比如 MySQL 中的数据;另一类是非结构化数据,比如搜索引擎中网页。对于非结构化数据,我们一般需要做预处理,提取出查询关键词,对关键词构建索引。
-
数据是静态数据还是动态数据?如果原始数据是一组静态数据,也就是说,不会有数据的增加、删除、更新操作,所以,我们在构建索引的时候,只需要考虑查询效率就可以了。这样,索引的构建就相对简单些。不过,大部分情况下,我们都是对动态数据构建索引,也就是说,我们不仅要考虑到索引的查询效率,在原始数据更新的同时,我们还需要动态地更新索引。支持动态数据集合的索引,设计起来相对也要更加复杂些。
-
索引存储在内存还是硬盘?如果索引存储在内存中,那查询的速度肯定要比存储在磁盘中的高。但是,如果原始数据量很大的情况下,对应的索引可能也会很大。这个时候,因为内存有限,我们可能就不得不将索引存储在磁盘中了。实际上,还有第三种情况,那就是一部分存储在内存,一部分存储在磁盘,这样就可以兼顾内存消耗和查询效率。
-
单值查找还是区间查找?所谓单值查找,也就是根据查询关键词等于某个值的数据。这种查询需求最常见。所谓区间查找,就是查找关键词处于某个区间值的所有数据。你可以类比 MySQL 数据库的查询需求,自己想象一下。实际上,不同的应用场景,查询的需求会多种多样。
-
单关键词查找还是多关键词组合查找?比如,搜索引擎中构建的索引,既要支持一个关键词的查找,也要支持组合关键词查找。对于单关键词的查找,索引构建起来相对简单些。对于多关键词查询来说,要分多种情况。像 MySQL 这种结构化数据的查询需求,我们可以实现针对多个关键词的组合建立索引;对于像搜索引擎这样的非结构数据的查询需求,我们可以针对单个关键词构建索引,然后通过集合操作,比如求并集、求交集等,计算出多个关键词组合的查询结果。
实际上,不同的场景,不同的原始数据,对于索引的需求也会千差万别。我这里只列举了一些比较有共性的需求。
非功能性需求
讲完了功能性需求,我们再来看,索引设计的非功能性需求。
-
索引对存储空间的消耗不能过大。如果存储在内存中,索引对占用存储空间的限制就会非常苛刻。毕竟内存空间非常有限,一个中间件启动后就占用几个 GB 的内存,开发者显然是无法接受的。如果存储在硬盘中,那索引对占用存储空间的限制稍微会放宽一些。但是,我们也不能掉以轻心。因为,有时候,索引对存储空间的消耗会超过原始数据。
-
还要考虑索引的维护成本。索引的目的是提高查询效率,但是,基于动态数据集合构建的索引,我们还要考虑到索引的维护成本。因为在原始数据动态增删改的同时,我们也需要动态地更新索引,而索引的更新势必会影响到增删改操作的性能。
构建索引常用的数据结构有哪些
我刚刚从很宏观的角度,总结了在索引设计的过程中,需要考虑的一些共性因素。现在,我们就来看,对于不同需求的索引结构,底层一般使用哪种数据结构。
实际上,常用来构建索引的数据结构,就是我们之前讲过的几种支持动态数据集合的数据结构:散列表、红黑树、跳表、B+ 树
-
散列表:散列表增删改查操作的性能非常好,时间复杂度是 O(1)。这类索引,一般都构建在
内存中。一些键值数据库,比如Redis、Memcache,就是使用散列表来构建索引的。 -
红黑树:红黑树作为一种常用的平衡二叉查找树,数据插入、删除、查找的时间复杂度是 O(logn)。也非常适合用来构建
内存索引。Ext 文件系统中,对磁盘块的索引,用的就是红黑树 -
跳表:跳表也支持快速添加、删除、查找数据。而且,我们通过灵活调整索引结点个数和数据个数之间的比例,可以很好地平衡索引对内存的消耗及其查询效率。
Redis中的有序集合,就是用跳表来构建的。 -
B+ 树:B+ 树比起红黑树来说,更加适合构建存储在
磁盘中的索引。B+ 树是一个多叉树,所以,对相同个数的数据构建索引,B+ 树的高度要低于红黑树。当借助索引查询数据的时候,读取 B+ 树索引需要的磁盘 IO 次数会更少。大部分关系型数据库的索引,比如 MySQL、Oracle,都是用 B+ 树来实现的。
除了散列表、红黑树、B+ 树、跳表之外,位图和布隆过滤器这两个数据结构,也可以用于索引中,辅助存储在磁盘中的索引,加速数据查找的效率。我们来看下,具体是怎么做的。
我们知道,布隆过滤器有一定的判错率。但是,我们可以规避它的短处,发挥它的长处。尽管对于判定存在的数据,有可能并不存在,但是对于判定不存在的数据,那肯定就不存在。而且,布隆过滤器还有一个更大的特点,那就是内存占用非常少。我们可以针对数据,构建一个布隆过滤器,并且存储在内存中。当要查询数据的时候,我们可以先通过布隆过滤器,判定是否存在。如果通过布隆过滤器判定数据不存在,那我们就没有必要读取磁盘中的索引了。对于数据不存在的情况,数据查询就更加快速了。
实际上,有序数组也可以被作为索引。如果数据是静态的,也就是不会有插入、删除、更新操作,那我们可以把数据的关键词(查询用的)抽取出来,组织成有序数组,然后利用二分查找算法来快速查找数据。
总结引申
今天这节算是一节总结课。我从索引这个非常常用的技术方案,给你展示了散列表、红黑树、跳表、位图、布隆过滤器、有序数组这些数据结构的应用场景。学习完这节课之后,不知道你对这些数据结构以及索引,有没有更加清晰的认识呢?
从这一节内容中,你应该可以看出,架构设计离不开数据结构和算法。要想成长为一个优秀的业务架构师、基础架构师,数据结构和算法的根基一定要打稳。因为,那些看似很惊艳的架构设计思路,实际上,都是来自最常用的数据结构和算法。
2018-01-03
本文来自博客园,作者:白乾涛,转载请注明原文链接:https://www.cnblogs.com/baiqiantao/p/8182389.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号