




#Auther Bob #--*--conding:utf-8 --*-- import redis # 创建连接 conn = redis.Redis(host="0.0.0.0",password="123",port=6379) # 创建一个连接redis数据库的连接 conn.set("name","cuiyuerong",ex=5) # 在内存数据库中设置一个键值对,name等于cuiyuerong,超时时间为5s print(conn.get("name")) # 去数据库中获取连接 # 推荐大家使用连接池的方式连接redis,使用连接池的方式可以提高性能 # 创建连接池,创建一个连接池,这个连接池最大有1000个连接 from test_redis.redis_poll import conn_poll # conn_poll = redis.ConnectionPool(host="0.0.0.0",password="123",port=6379,max_connections=1000) conn = redis.Redis(connection_pool=conn_poll) conn.set("name","cuiyuerong",ex=5) print(conn.get("name"))
单实例
#Auther Bob
#--*--conding:utf-8 --*--
# redis是一个软件,帮助用户操作内存
# 同样也可以做持久化,持久化有2种办法
# AOF
# RDB
# redis相当于一个大字典
# redis是一个单进程和单线程
# 连接池
# 本质是维护一个已经和服务端连接成功地socket连接,以后再次发消息直接取一个连接,send数据
import redis
conn_poll = redis.ConnectionPool(host="0.0.0.0",password="123",port=6379,max_connections=1000)
conn_poll.get_connection()
一、redis操作字典




 \
\
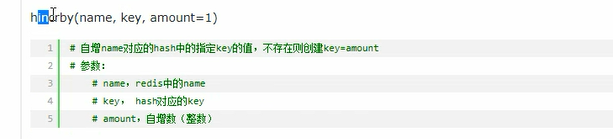
# 默认自增为1,可以设置为自增的多少
conn.hincrby("s1","age",amount=2)

def hscan_iter(self, name, match=None, count=None):
"""
Make an iterator using the HSCAN command so that the client doesn't
need to remember the cursor position.
``match`` allows for filtering the keys by pattern
``count`` allows for hint the minimum number of returns
"""
cursor = '0'
while cursor != 0:
cursor, data = self.hscan(name, cursor=cursor,
match=match, count=count)
for item in data.items():
yield item
cursor表示起始位置,count表示取的数量

这里的cursor就是取完100条数据后的游标
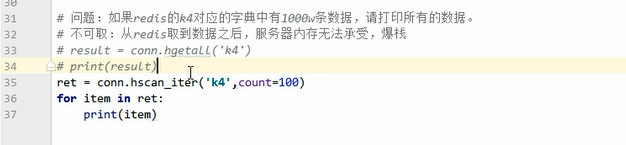
# ==========================================================================================
# 今天下来说一下redis的字典的操作
# 1、hset/hget
# 设置单个字段
# conn.hset("k1","name","zmx")
#
# 获取单个字段
# print(conn.hget("k1","name"))
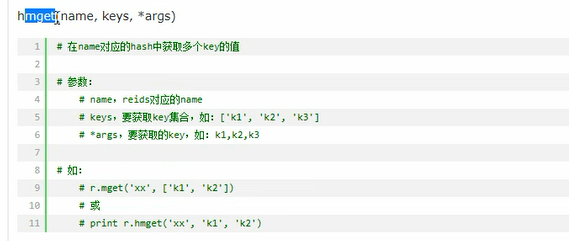
# 2、hmset/hmget
# d = {"name":"zmx","age":12}
#
# 批量设置单个字段
# conn.hmset("k1",d)
#
# 批量获取所有的字段
# name = conn.hmget("k1",["name","age"])
#
# print(name)
# [b'zmx', b'12']
# name = conn.hmget("k1","name","age")
# print(name)
# [b'zmx', b'12']
# 3、hgetall
# 获取做所有的信息
name = conn.hgetall("k1")
print(name)
# {b'name': b'zmx', b'age': b'12'}
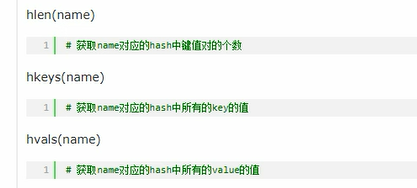
# 获取长度
l = conn.hlen("k1")
print(l)
# 2
# 获取key
k = conn.hkeys("k1")
print(k)
# [b'name', b'age']
# 获取values
v = conn.hvals("k1")
print(v)
# [b'zmx', b'12']
# 判断是否存在这个字段
b = conn.hexists("k1","age")
print(b)
# True
b = conn.hexists("k1","test")
print(b)
# False
# 删除某个字段
conn.hdel("k1","age")
b = conn.hexists("k1","age")
print(b)
# False
# 自增,每次增加2
conn.hincrby("k1","age",amount=2)
print(conn.hexists("k1","age"))
# True
print(conn.hvals("k1"))
# [b'zmx', b'2']
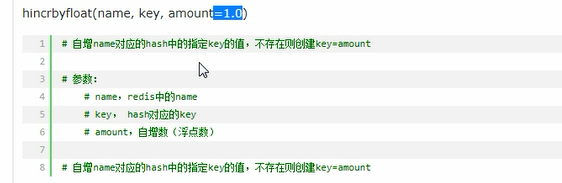
conn.hincrbyfloat("k1","age",amount=1.2)
print(conn.hget("k1","age"))
# b'3.2'
d = {"a":1,"b":2,"c":3,"d":4,"e":5,"f":6,"g":7,"h":8}
conn.hmset("k2",d)
for i in conn.hscan_iter("k2",count=2):
print("--------")
print(i)
# 这个match支持通配符,意思是匹配k为k1,v为a*的数据
for i in conn.hscan_iter("k1",match="a*",count=2):
print("--------")
print(i)
如果往redis存放下面的格式

则要把绿色框中的作为字符串传递进去

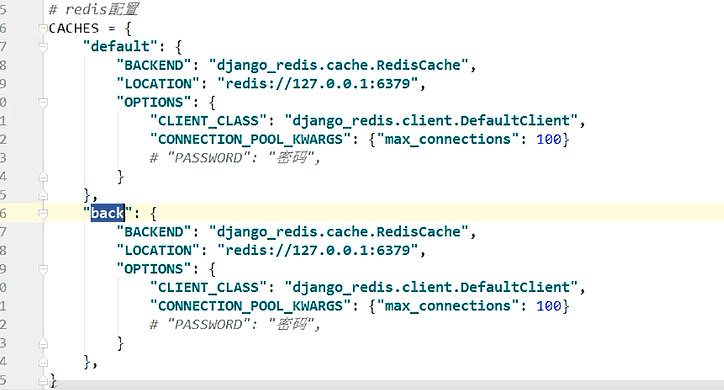
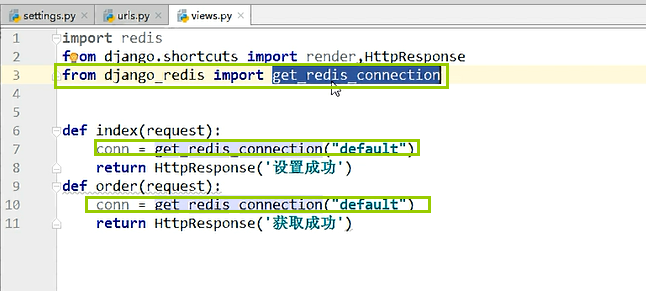
2、django使用redis
可以使用django自带的redis模块,也可以使用python的redis模块
pip3.6.exe install django-redis
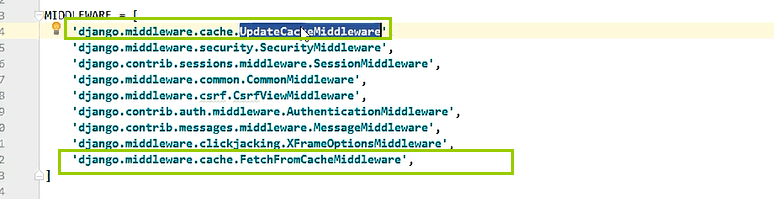
a、全站缓存
django实现全站的缓存,加2个中间件就可以了

全站缓存其他配置,超时时间的设置
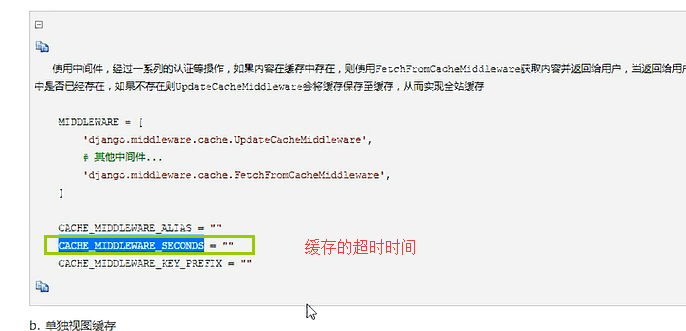
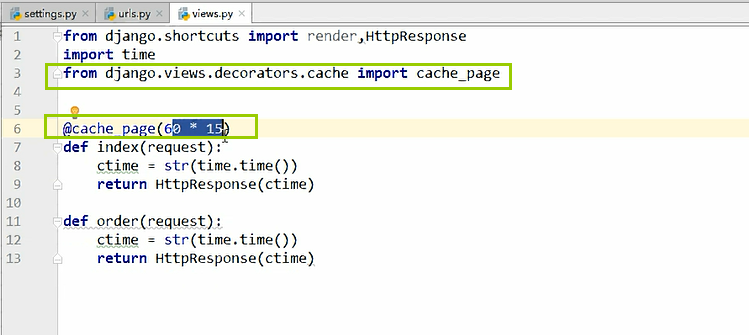
b、单视图缓存,针对某个视图函数做缓存,这个优先级比全站缓存的优先级高
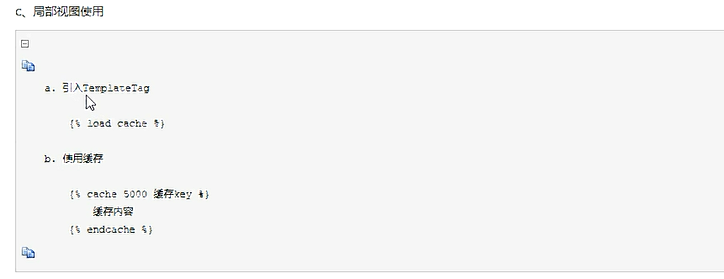
c、局部视图的redis缓存,针对某个页面的某个部分做缓存,这里的5000的单位是秒,redis缓存的超时时间
d、django配置缓存
第一个缓存放到文件中,第二个缓存放到memcached中,memcached也是一个类似redis的软件



 浙公网安备 33010602011771号
浙公网安备 33010602011771号