第二次作业
作业①:
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
输出信息:
| 序号 | 地区 | 日期 | 天气信息 | 温度 |
| 1 | 北京 | 7日(今天) | 晴间多云,北部山区有阵雨或雷阵雨转晴转多云 | 31℃/17℃ |
| 2 | 北京 | 8日(明天) | 多云转晴,北部地区有分散阵雨或雷阵雨转晴 | 34℃/20℃ |
| 3 | ... | ... | ... | ... |
1.获取每个城市的编号,得到相应的url

在Network中找到存放城市及其编号的文件city.js,Request URL为https://j.i8tq.com/weather2020/search/city.js
2.解析网页得到数据

每个li标签对应一天的信息,通过soup.select("ul[class='t clearfix'] li")可全部获取
3.将数据保存到数据库
代码:
import requests,re
from bs4 import BeautifulSoup
import pymysql
# 获取城市对应的url
# 有些城市会重名,没重名不需要supcity参数,supcity是地区的上级地区,如:city=鼓楼,supcity可以为福州或福建
def getCityUrl(city, supcity=None):
try:
# 如果supcity不为None,则根据city和supcity进行匹配,得到只包含一个city的字符串
msg = re.search(supcity + "(.|\n)*" + city + "(.|\n)*?},",r.text).group(0) if supcity else r.text
# 单独匹配所需city
s = re.search(city + "(.|\n)*?},", msg).group(0)
# 提取s中的数字,即城市对应的编号
num = re.search("\d+", s).group(0)
return "http://www.weather.com.cn/weather/"+num+".shtml"
except AttributeError as e:
# 没匹配到就返回city不存在
errmsg = supcity + city if supcity else city
print(errmsg+"不存在!")
# 插入数据
def insertData(num, city, date, weather, temp):
try:
cursor.execute("insert into weathers(num, city, date, weather, temp)values (%s, %s, %s, %s, %s)",
(num, city, date, weather, temp))
# 提交事务
db.commit()
except Exception as e:
# 如果发生错误则输出错误信息并回滚
print(e)
db.rollback()
# 存储数据
def saveData(cityurl, cityname):
global t
cr = requests.get(cityurl)
cr.encoding = "UTF-8"
soup = BeautifulSoup(cr.text, "html.parser")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
# li.text.split("\n")含有空字符串,除去就能得到所要数据
data = [x for x in li.text.split("\n") if x != ""]
print(mat.format(t, cityname, data[0], data[1], data[2]))
insertData(t, cityname, data[0], data[1], data[2])
t += 1
# 连接数据库
db = pymysql.Connect(
host='localhost',
port=3306,
user='root',
passwd='root',
db='bai',
charset='utf8'
)
# 获取游标
cursor = db.cursor()
# 表不存在则创建表
sql = """
create table if not exists weathers (
num int(10) primary key,
city varchar(16),
date varchar(16),
weather varchar(64),
temp varchar(32))"""
cursor.execute(sql)
# 获取城市对应编号的url
url = "https://j.i8tq.com/weather2020/search/city.js"
r = requests.get(url)
# 城市集,有重名的用列表表示,福州可以替换成福建,江苏可以替换成南京
citys = ["泉州","稻城",["福州","鼓楼"],["江苏","鼓楼"],"桃花源"]
# 编号
t = 1
# 格式化输出
mat = "{:^4}\t{:^6}\t{:^8}\t{:^10}\t{:^8}"
print(mat.format("序号", "地区", "日期", "天气信息", "温度"))
for city in citys:
# 根据str或list调用不同的方法,得到城市对应的url
if type(city).__name__ == "str":
cityurl = getCityUrl(city)
cityname = city
else:
cityurl = getCityUrl(city[1], city[0])
cityname = city[0]+city[1]
if cityurl != None:
saveData(cityurl, cityname)
# 关闭数据库连接
db.close()
运行结果:
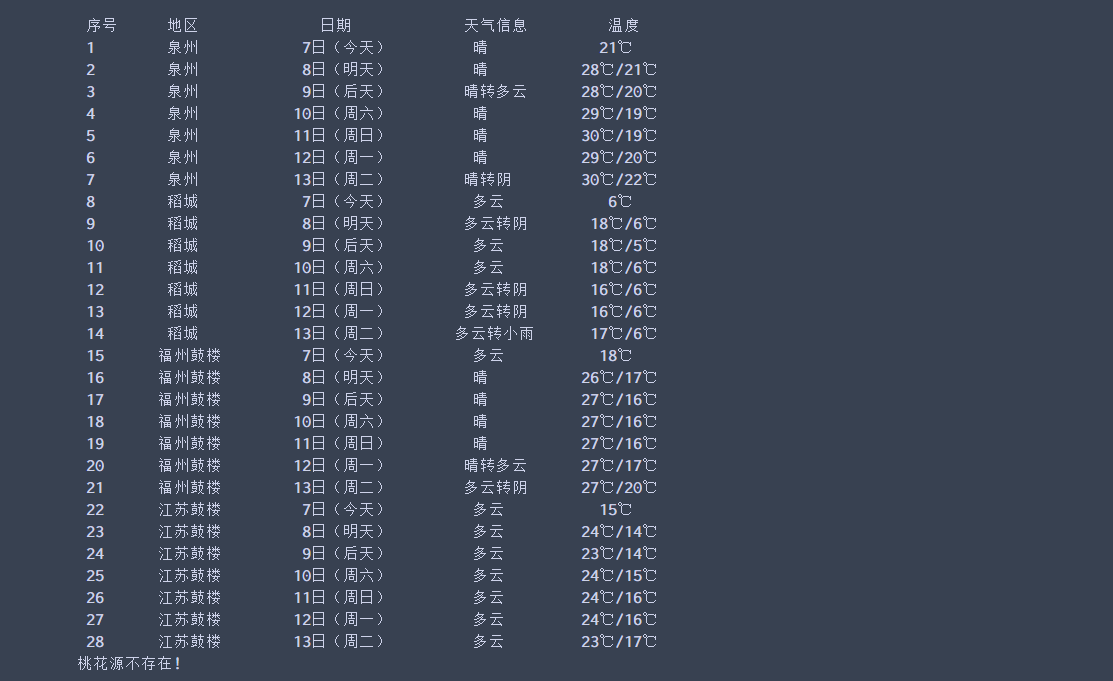

2)心得体会:本实验难点主要是获取城市对应的编号,然后通过字符串拼接得到相应的url,后面想到有同名的地方,就增加了会重名地区的查询;然后解析网页获得数据,保存在数据库,第一次使用python连接MySQL,我的青春结束了.
作业②:
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息。
输出信息:
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
| 1 | 688093 | N世华 | 28.47 | 62.22% | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.2 | 17.55 |
| 2 | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
1.该网站通过createBody方法动态创建表格.通过Network寻找其获取数据的API,得到第一页的Request URL.
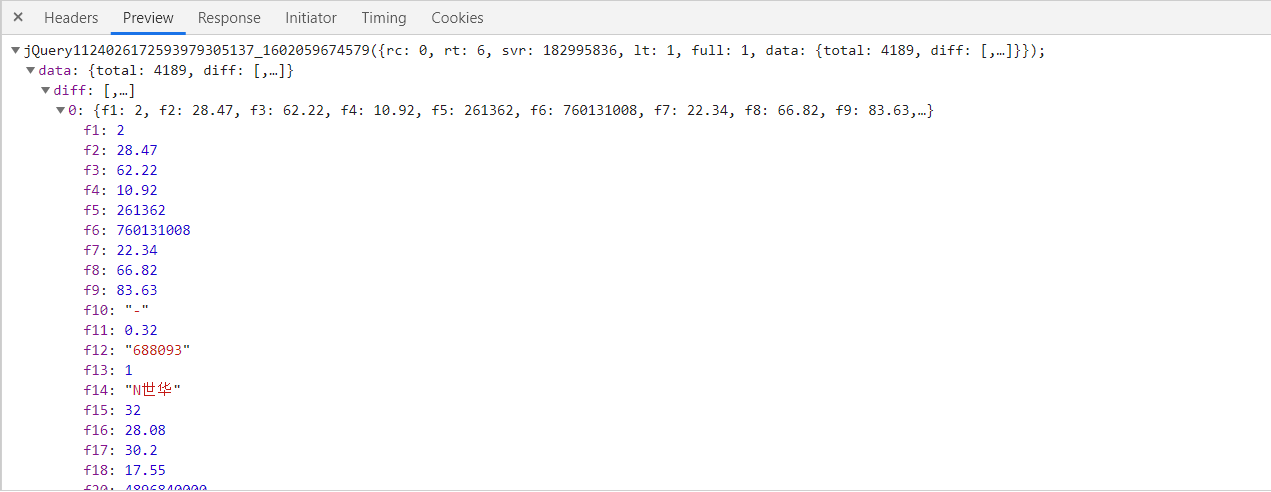
2.继续获取第二页和第三页的Request URL,探索该网站的翻页机制
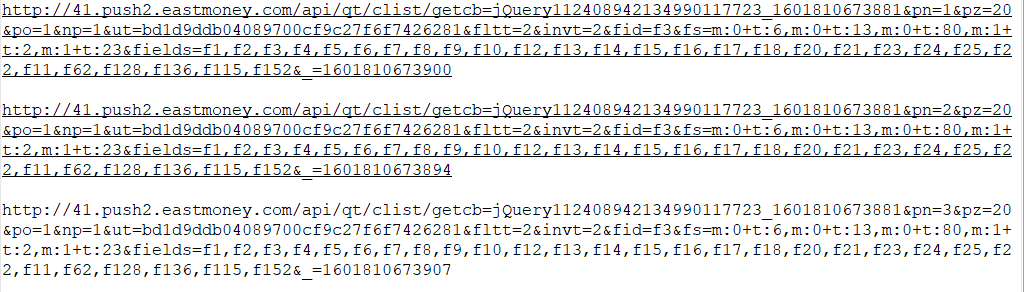
可以看出,控制第几页的参数为pn,pn=1就是第一页
3.访问API,并解析出所要的数据
代码:
import requests,re
import json
# 计算有多少个中文字符,输出格式用到
def count(s):
return len([ch for ch in s if '\u4e00' <= ch <= '\u9fff'])
cnt = 3 # 爬取页面数,最多210
# 输出表头
print("{:<3} {:<5} {:<6} {:<4} {:<5} {:<5} {:<8} {:<9} {:<4} {:<5} {:<4} {:<5} {:<5}".format(
"序号", "股票代码", "股票名称", "最新报价", "涨跌幅", "涨跌额", "成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收"))
for i in range(cnt):
# 只对沪深A股进行爬取,利用参数pn实现翻页
url = "http://41.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408942134990117723_1601810673881&pn=" + \
str(i+1)+"&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23"
r = requests.get(url)
r.encodingn = "UTF-8"
# 找到第一个[的位置,因为前面有一个{,会对匹配造成影响
text = r.text[r.text.index("["):]
# 匹配所有{},每支股票信息都包含在一个{}里
datas = re.findall("{.*?}", text)
for j in range(len(datas)):
# 将数据解析成字典
data = json.loads(datas[j])
# 输出数据
temp = "{:<5} {:<8} {:<"+str(10-count(
data['f14']))+"} {:<7} {:<7} {:<7} {:<8} {:<13} {:<6} {:<6} {:<6} {:<6} {:<6}"
print(temp.format(i*20+j+1, data['f12'], data['f14'], data['f2'], data['f3'], data['f4'],
data['f5'], data['f6'], data['f7'], data['f15'], data['f16'], data['f17'], data['f18']))
运行结果:
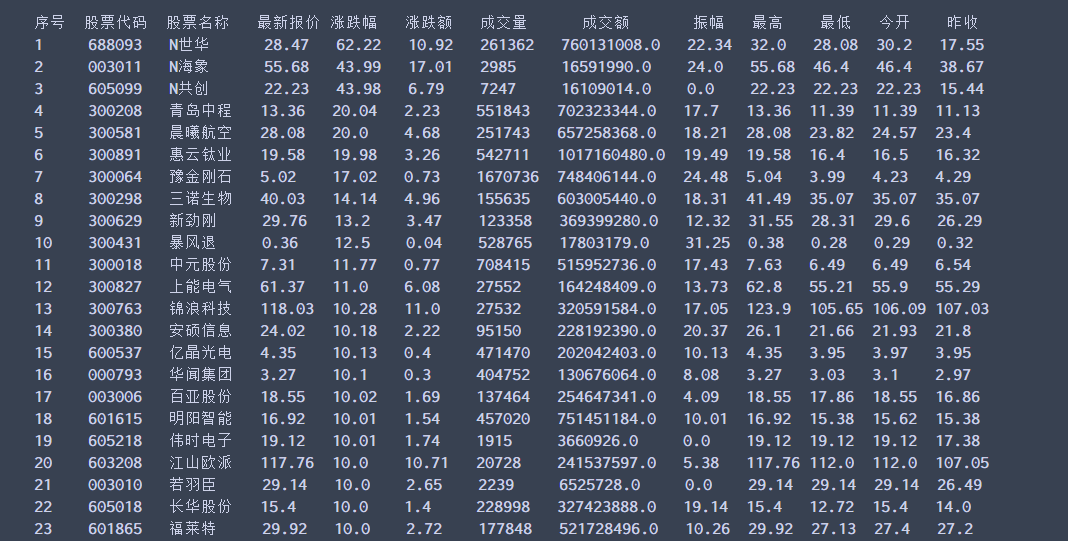
2)心得体会:本实验所爬取的网站是动态加载的,需要我们去抓包分析找到json数据接口,分析翻页的参数等等,还是selenium香.
作业③:
根据自选3位数+学号后3位选取股票,获取印股票信息。
输出信息:
| 股票代码号 | 股票名称 | 今日开 | 今日最高 | 今日最低 |
| 605006 | 山东玻纤 | 9.04 | 8.58 | 8.13 |
import requests
import re
name = "振芯科技"
number = "300101"
# 同上,在Network中寻找js文件
url = "http://76.push2his.eastmoney.com/api/qt/stock/kline/get?cb=jQuery112409186255157892003_1601815696958&secid=0.300101" + \
"&ut=fa5fd1943c7b386f172d6893dbfba10b&fields1=f1%2Cf2%2Cf3%2Cf4%2Cf5%2Cf6&fields2=f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2" + \
"Cf58%2Cf59%2Cf60%2Cf61&klt=101&fqt=0&end=20500101&lmt=120&_=1601815696974"
r = requests.get(url)
r.encoding = "UTF-8"
# 选择最新时间的那条数据,数据包含在一对引号中,定位最后两个引号的位置,获取引号之间的数据
endOne = r.text.rindex("\"")
endTwo = r.text.rindex("\"", 0, endOne)
data = r.text[endTwo:endOne]
# 用,分隔得到一个数组,选择所需要的信息输出
data = data.split(",")
mat="{:<8}\t{:<8}\t{:<8}\t{:<8}\t{:<8}"
print(mat.format("股票代码号","股票名称", "今日开", "今日最高", "今日最低"))
print(mat.format(number,name,data[1],data[3],data[4]))
运行结果:

2)心得体会:同实验2抓包得到API,个人不是很懂股票,就取最新的日期对应的数据,不过最新日期是几天前的,不知道理解正确否?
待到山花烂漫时,她在丛中笑。秋天来了,zzp们的冬天还会远吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号