
小白学 Python 爬虫(20):Xpath 进阶

人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
小白学 Python 爬虫(10):Session 和 Cookies
小白学 Python 爬虫(11):urllib 基础使用(一)
小白学 Python 爬虫(12):urllib 基础使用(二)
小白学 Python 爬虫(13):urllib 基础使用(三)
小白学 Python 爬虫(14):urllib 基础使用(四)
小白学 Python 爬虫(15):urllib 基础使用(五)
小白学 Python 爬虫(16):urllib 实战之爬取妹子图
小白学 Python 爬虫(17):Requests 基础使用
小白学 Python 爬虫(18):Requests 进阶操作
引言
文接上篇,我们接着聊,上篇我们介绍了 Xpath 一些常用的匹配方式, DOM 节点我们可以匹配出来了,这并不是我们的最终目的,我们是要从这些节点中取出来我们想要的数据。本篇我们接着介绍如何使用 Xpath 获取数据。
文本获取
我们先尝试下获取第一篇文章的题目,获取节点中的文本我们可以使用 text() 来进行获取,如图:
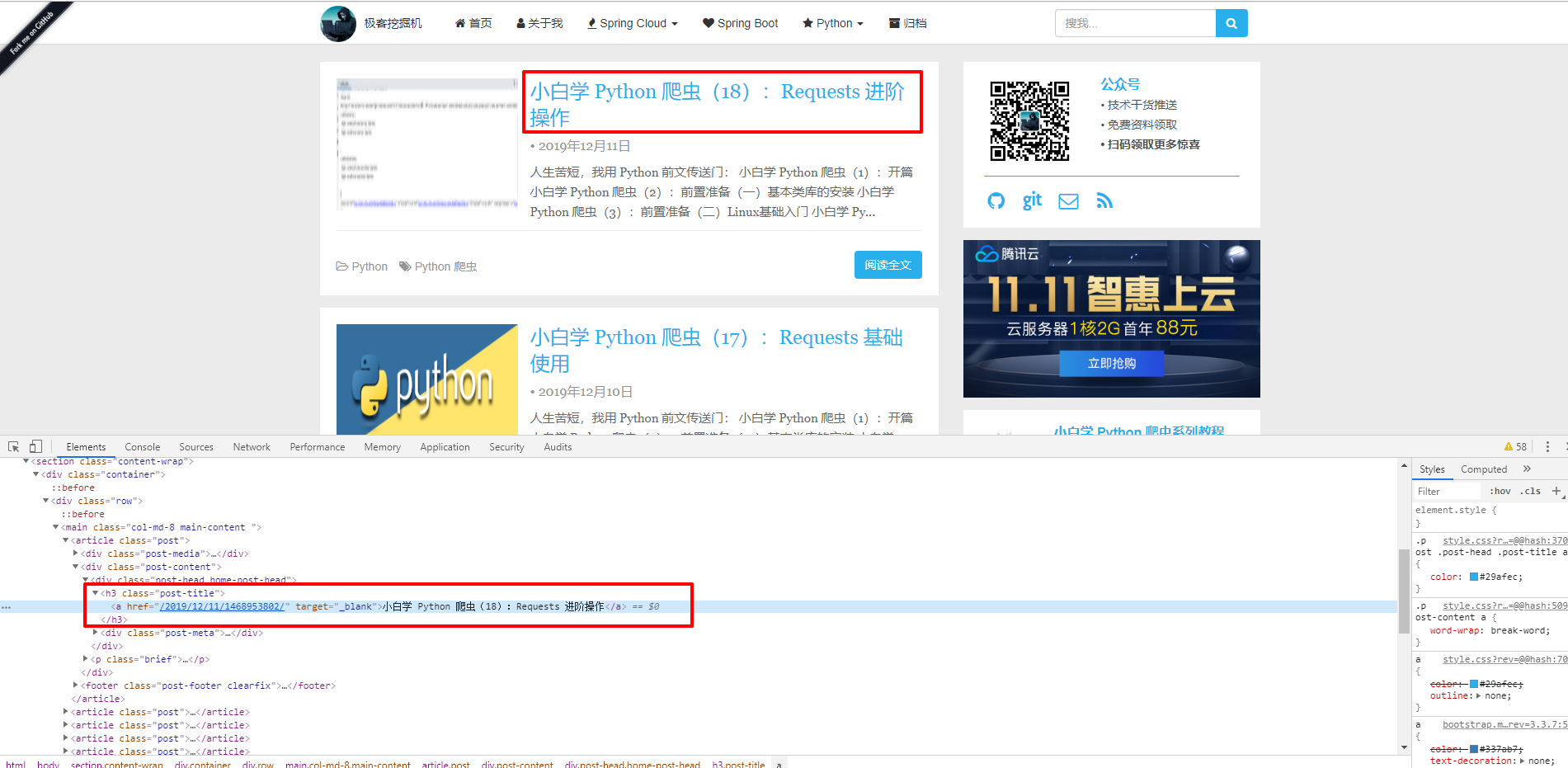
代码如下:
from lxml import etree
import requests
response = requests.get('https://www.geekdigging.com/')
html_str = response.content.decode('UTF-8')
html = etree.HTML(html_str)
result_1 = html.xpath('/html/body/section/div/div/main/article[1]/div[2]/div/h3/a/text()')
print(result_1)
结果如下:
['小白学 Python 爬虫(18):Requests 进阶操作']
哇,上面示例里面的表达式好长啊,这个怎么写出来的,怎么写的稍后再说,先介绍一下这个表达式的意思,仔细看一下,这个表达式其实是从整个 HTML 源代码的最外层的 <html> 标签写起,一层一层的定位到了我们所需要的节点,然后再使用 text() 方法获取了其中的文本内容。
关于这个表达式怎么来的,肯定不是小编写的,这么写讲实话是有点傻,完全没必要从整个文档的最外层开始写。
其实这个是 Chrome 帮我们生成的,具体操作可见下图:
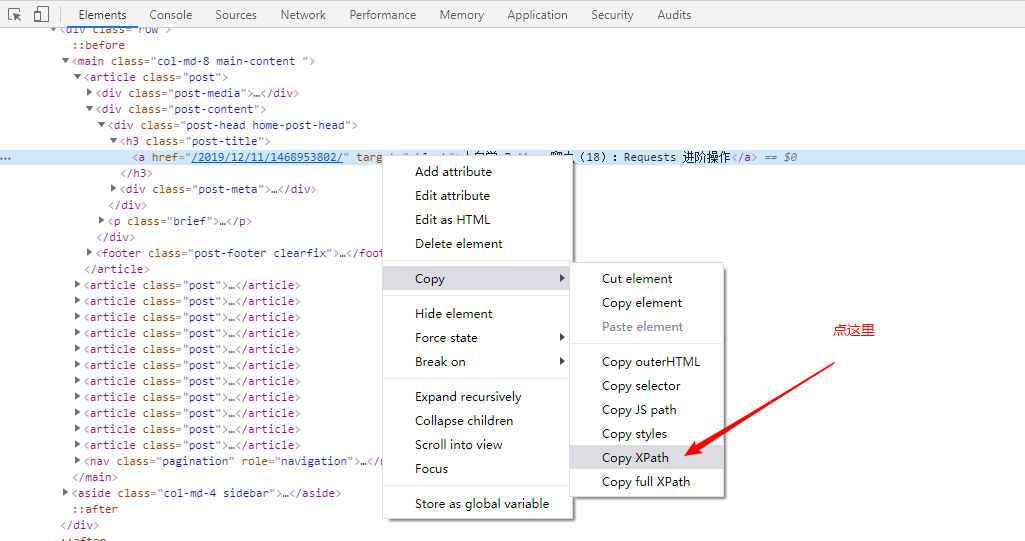
这时 Chrome 会自动帮我们把这个节点的表达式 copy 到当前的剪切板上,只需要我们在程序里 ctrl + v 一下。
属性获取
有些情况下,我们可能不止需要节点中的文本数据,可能还会需要节点中的属性数据,比如上面的示例,我们除了想知道文章标题,其实还想知道文章的跳转路径:
result_2 = html.xpath('/html/body/section/div/div/main/article[1]/div[2]/div/h3/a/@href')
print(result_2)
结果如下:
['/2019/12/11/1468953802/']
这里需要注意的是,此处和属性匹配的方法不同,属性匹配是中括号加属性名和值来限定某个属性,如 [@class="container"] ,而此处的 @href 指的是获取节点的某个属性,二者需要做好区分。
属性多值匹配
某些时候吧,某些节点的某个属性可能有多个值,这个多见于 class 属性,由于某些编码习惯以及某些其他原因,这个属性经常性会出现多个值,这时如果只使用其中的一个值的话,就无法匹配了。

如果这么写的话:
result_3 = html.xpath('//div[@class="post-head"]')
print(result_3)
结果如下:
[]
可以看到,这里没有匹配到任何节点,这时,我们可以使用一个函数:contains() ,上面的示例可以改成这样:
result_3 = html.xpath('//div[contains(@class, "post-head")]')
print(result_3)
这样通过 contains() 方法,第一个参数传入属性名称,第二个参数传入属性值,只要此属性包含所传入的属性值,就可以进行匹配了。
多属性匹配
除了上面的一个属性有多个值的情况,还经常会出现需要使用多个属性才能确定一个唯一的节点。
这时,我们可以使用运算符来进行处理。

还是这个示例,我们获取 <img> 这个节点,如果只是使用 class 属性来进行获取,会获得很多个节点:
result_4 = html.xpath('//img[@class="img-ajax"]')
print(result_4)
结果如下:
[<Element img at 0x1984505a788>, <Element img at 0x1984505a7c8>, <Element img at 0x1984505a808>, <Element img at 0x1984505a848>, <Element img at 0x1984505a888>, <Element img at 0x1984505a908>, <Element img at 0x1984505a948>, <Element img at 0x1984505a988>, <Element img at 0x1984505a9c8>, <Element img at 0x1984505a8c8>, <Element img at 0x1984505aa08>, <Element img at 0x1984505aa48>]
如果我们加上 alt 属性一起进行匹配的话,就可以获得唯一的节点:
result_4 = html.xpath('//img[@class="img-ajax" and @alt="小白学 Python 爬虫(18):Requests 进阶操作"]')
print(result_4)
结果如下:
[<Element img at 0x299905e6a48>]
Xpath 支持很多的运算符,详细见下表(来源:https://www.w3school.com.cn/xpath/xpath_operators.asp)
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | | 计算两个节点集 | //book | //cd | 返回所有拥有 book 和 cd 元素的节点集 |
| + | 加法 | 6 + 4 | 10 |
| - | 减法 | 6 - 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果 price 是 9.80,则返回 true。如果 price 是 9.90,则返回 false。 |
| != | 不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| < | 小于 | price<9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| <= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| > | 大于 | price>9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| >= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.70,则返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,则返回 true。如果 price 是 9.50,则返回 false。 |
| and | 与 | price>9.00 and price<9.90 | 如果 price 是 9.80,则返回 true。如果 price 是 8.50,则返回 false。 |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
按顺序选择
有些时候,我们匹配出来很多的节点,但是我们只想获取其中的某一个节点,比如第一个或者最后一个,这时可以使用中括号传入索引的方法获取特定次序的节点。
我们还是文章的题目为例,我们先获取所有的文章题目,再进行选择,示例代码如下:
result_5 = html.xpath('//article/div/div/h3[@class="post-title"]/a/text()')
print(result_5)
result_6 = html.xpath('//article[1]/div/div/h3[@class="post-title"]/a/text()')
print(result_6)
result_7 = html.xpath('//article[last()]/div/div/h3[@class="post-title"]/a/text()')
print(result_7)
result_8 = html.xpath('//article[position() < 5]/div/div/h3[@class="post-title"]/a/text()')
print(result_8)
结果如下:
['小白学 Python 爬虫(18):Requests 进阶操作', '小白学 Python 爬虫(17):Requests 基础使用', '小白学 Python 爬虫(16):urllib 实战之爬取妹子图', '如何用 Python 写一个简易的抽奖程序', '小白学 Python 爬虫(15):urllib 基础使用(五)', '我们真的在被 APP “窃听” 么?', '小白学 Python 爬虫(14):urllib 基础使用(四)', '小白学 Python 爬虫(13):urllib 基础使用(三)', '小白学 Python 爬虫(12):urllib 基础使用(二)', '小白学 Python 爬虫(11):urllib 基础使用(一)', '老司机大型车祸现场', '小白学 Python 爬虫(10):Session 和 Cookies']
['小白学 Python 爬虫(18):Requests 进阶操作']
['小白学 Python 爬虫(10):Session 和 Cookies']
['小白学 Python 爬虫(18):Requests 进阶操作', '小白学 Python 爬虫(17):Requests 基础使用', '小白学 Python 爬虫(16):urllib 实战之爬取妹子图', '如何用 Python 写一个简易的抽奖程序']
第一次,我们选取了当前页面所有的文章的题目。
第二次,我们选择了当前页面第一篇文章的题目,这里注意下,中括号中传入数字1即可,这里的开始是以 1 为第一个的,不是程序中的 0 为第一个。
第三次,我们使用 last() 函数,获取了最后一篇文章的题目。
第四次,我们选择了位置小于 5 的文章题目。
节点轴
轴可定义相对于当前节点的节点集。
| 轴名称 | 结果 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。 |
| self | 选取当前节点。 |
我们以 ancestor 轴来做示例:
# 节点轴示例
# 获取所有祖先节点
result_9 = html.xpath('//article/ancestor::*')
print(result_9)
# 获取祖先节点 main 节点
result_10 = html.xpath('//article/ancestor::main')
print(result_10)
结果如下:
[<Element html at 0x2a266171208>, <Element body at 0x2a266171248>, <Element section at 0x2a266171288>, <Element div at 0x2a2661712c8>, <Element div at 0x2a266171308>, <Element main at 0x2a266171388>]
[<Element main at 0x2a266171388>]
关于节点轴就先介绍到这里,更多的轴的用法可以参考:https://www.w3school.com.cn/xpath/xpath_axes.asp 。
示例代码
本系列的所有代码小编都会放在代码管理仓库 Github 和 Gitee 上,方便大家取用。
作者:极客挖掘机
定期发表作者的思考:技术、产品、运营、自我提升等。
本文版权归作者极客挖掘机和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
如果您觉得作者的文章对您有帮助,就来作者个人小站逛逛吧:极客挖掘机

 浙公网安备 33010602011771号
浙公网安备 33010602011771号