高并发下的服务器架构演变
在如今的网络环境下,高并发的场景无处不在,特别在面试如何解决高并发是一个躲不过的问题,即使生产环境达不到那么高的qps但是也应该给自己留条后路来应对日后可能发生的高并发场景,不用匆忙的加班加点的进行重构。
在应对日常高并发场景常常会有这么几个方法:
- 集群&负载均衡SLB
- 读写分离&分库分表
- 缓存
- 异步队列(RabbitMQ)
- 分布式系统、微服务
接下来就由浅入深分别来介绍下这几个方法是怎么应用到服务器并且解决高并发的,首先我们先来看下最原始的也是最简单的服务器与应用程序关系。

图1
如图1所示在一台服务器上承载了数据库、文件系统、应用程序的所有功能,这就导致即使低qps的情况下服务器的内存或者cpu占比都非常高,用过sqlserver的同僚们都知道为了达到最高效快速的数据查询、存储及运算支持sql server默认会尽可能的占用内存及CPU来达到自己的目的,从而导致我们的应用程序在处理一些运算或者请求量相对升高时应用程序就会变得非常慢,这时候我们就该考虑升级我们现有的服务器了,当然最高效也是最便捷的方式是升级硬件(cpu、内存、硬盘),这也是最容易达到瓶颈的毕竟一台服务的硬件也是有瓶颈的而且费用也是相当相当高昂的,一般情况下我们会选择我们最开始提到解决高并发方法中分布式来升级我们图1的单一服务器系统架构。
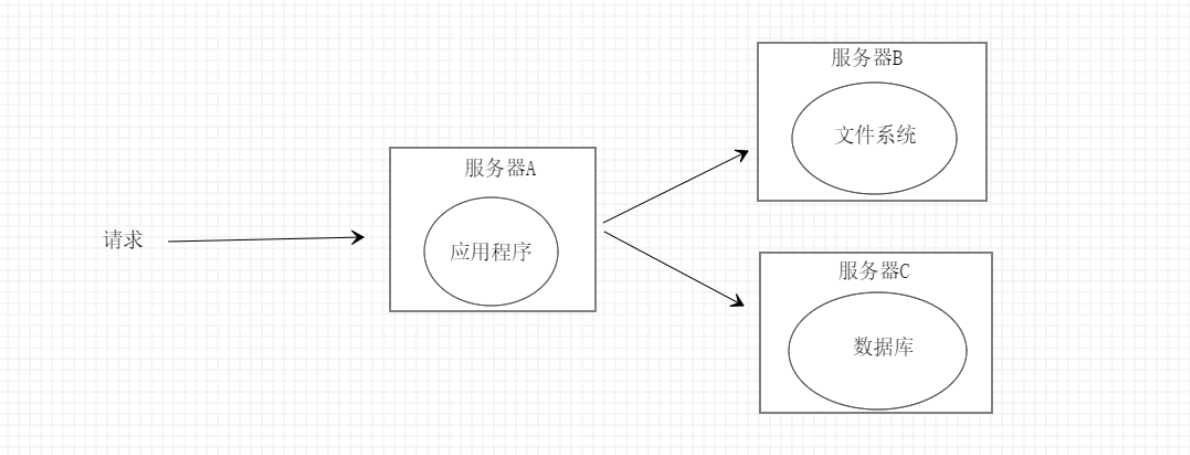
图2
如图2所示我们由一台服务器转为三台服务器互相协作的方式来处理每次请求,这也是简单的分布式系统每台服务器各司其职再也不会发生单一应用占用大量cpu或内存的情况导致请求变得缓慢,但是就图2而言的服务器架构的承载能力也是非常有限的,当请求量上升后可能就扛不住宕机了。
一般这时候我们就要分析发生宕机的原因,从图2便知只有服务器A或者服务器B最有可能出现问题,根据以往的经验在请求量升高时数据库会承载绝大部分的压力,如果数据库崩了那么整个应用就会处于不可用的状态,那么为了缓解数据库的压力,我们很自然的就会想到利用缓存,这也是高并发场景下最常用也是最有效最简单的方案,利用好缓存能让你的系统的承载能力提示几倍甚至十几倍几十倍。熟悉二八原则的同僚们都知道80%请求的数据都集中在20%的数据上,虽然有些夸张但是意思就是这么个意思。缓存又分为本地缓存和分布式缓存,本着分布式的原则,我们一般都会选用分布式缓存同时也是为后期做分布式集群打下基础。
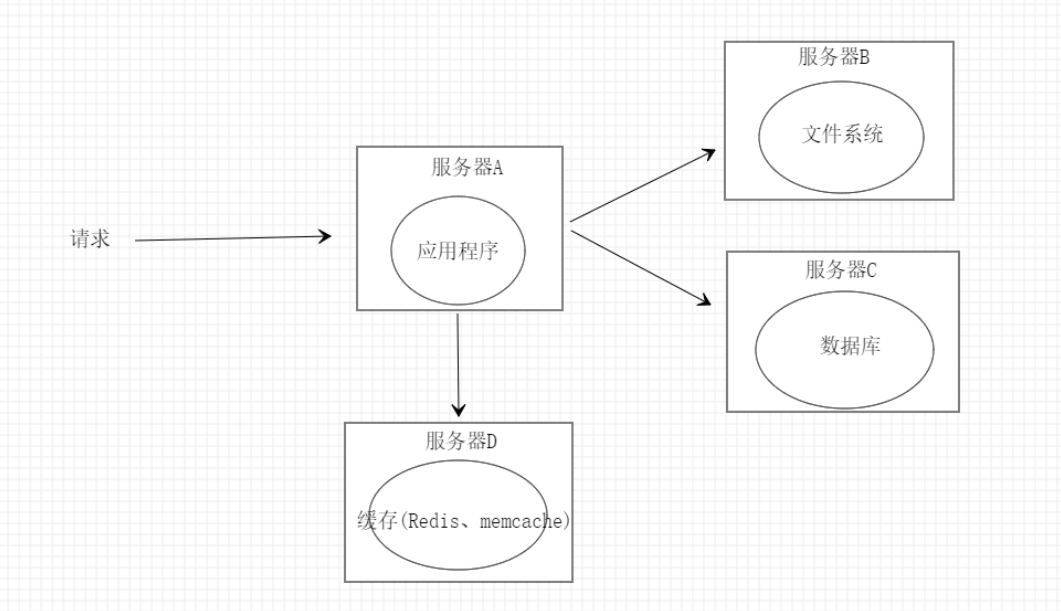
图3
如图3所示在图2的基础上增加了一台缓存服务器D来储存我们的缓存数据,一般我们会采用redis来存放缓存数据,至于memcache现在应用的频率是非常低的。现在当请求到达应用程序时会优先访问缓存服务器D,若存在缓存数据就直接返回给客户端如果不存在缓存数据才会去数据库获取数据返回给客户端同时将数据保存到缓存服务器D设置缓存失效时间这样下次请求时就不用到数据库查询数据了从而达到减轻数据库压力的目的。虽然缓存能抵挡大部分的请求,但是我们也要做好防止缓存击穿、穿透和雪崩的问题来提升系统的稳定性。
随着业务量的增多和繁多的业务种类图3的系统架构也会慢慢达到瓶颈支撑不住多样化的业务需求,这时候我们就应该采用集群的方式来达到负载均衡的目的,将请求平均的分散到多台服务器来拓展应用程序的承载能力。

图4
如图示4所示由服务器A-1、服务器A-2共同承载用户的请求来提高系统的承载能力也就是我们最开始说到集群,出现集群的地方必然少不了负载均衡,图4我们由nginx来实现请求的分发来达到负载均衡的目的。在设计图3的架构的时候我们有说到本地缓存,如果是采用本地缓存而不是分布式缓存那么系统架构就存在一个比较大的缺陷,因为一个请求过来是由nginx区分发的如果我们再用本地缓存那么在在服务器A-1和服务器A-2上可能存在大量相同的本地缓存这样就得不偿失了容易造成服务器资源的浪费严重的还会拖累服务器的性能,利用分布式缓存的好处在于我们不管有多少个应用服务器所有的缓存都是共享的。
图4的服务器架构应该是目前中小型应用中最常用的,而且系统的整体承载能力也相当不错,不过随着业务的发展流量与日俱增,图3的服务器架构也很难保证系统的稳定,特别是日常流量峰值的一些时段图3的系统可能时常会面临奔溃的危险,这时候就要重新分析各服务器的压力承载情况了,显而易见最可能出现问题的就是数据库服务器,终于要对数据库下手了,当下最有效的方法就是就写分离,还是遵循二八原则80%的数据操作都是查询操作。

图5
如图5所示在图4的基础上由单一的数据库变为主从数据库从库负责数据的查询操作主库负责数据增删改操作,但请求操作主库后主库将操作日志执行到从库达到主从数据一致的目的,但是主从分离后不可能避免的一个问题就是主从数据一致性会有延迟,数据同步延迟的问题只能尽可能的减小数据延迟的时间,但对一些时效性非常高或者不能容忍数据延迟的请求只能做一些妥协,这类操作的crud都在主库上操作这样就避免数据延迟的问题,对一些对于数据时效性不那么严格的请求可以将这部分的查询操作由从库去承载,对于主从数据库个人以为和应用集群是一样的可以理解为集群数据库只不过在请求的分发上制定了规则(主库处理更新、从库处理查询)。
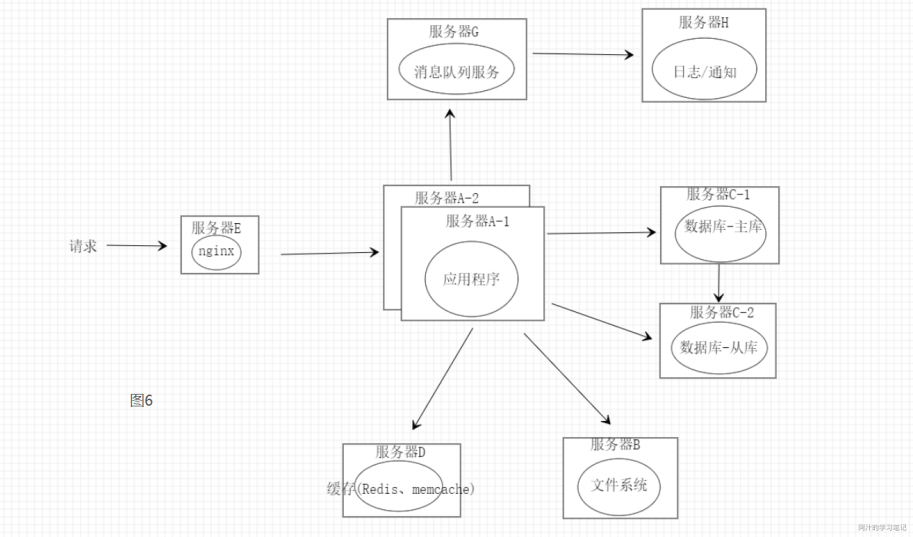
如图6将一些不属于核心业务的功能模块从应用服务中剥离出来降低服务的时延提高服务的吞吐量,这些类似日志、邮件/短信通知、监控等等都丢到队列中由单独的服务从队列中获取数据进行处理。可能一些同僚们会想到用异步的方法去处理这些方法,但是当有大量请求时这些异步处理会占用一部分服务器的性能同时异步也会增加程序的复杂度,所以用消息队列的方式可能应该是比较优的一种方法。
当然队列不仅仅是如图6所示起到一种日志收集、通知、服务解耦的作用,很多时候会用队列来应对一些特定场景(秒杀)来达到限流的防御性目的。
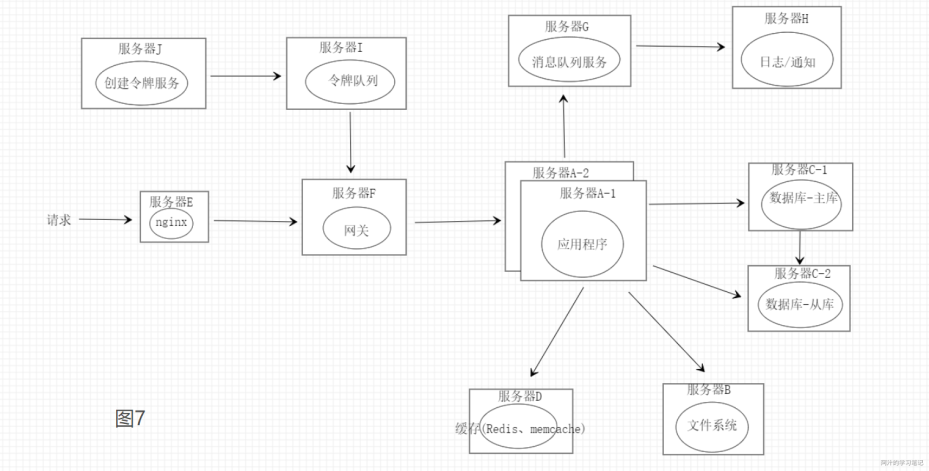
如图7,应对一些秒杀活动场景下,我们可以优先预估服务的处理处理能力然后创建令牌队列的容量同时开启服务器J的创建令牌服务匀速的将令牌放入令牌队列,如果队列满了就丢弃。当秒杀请求到达网关时由网关先到令牌队列获取令牌再请求分发到对应的服务,如果令牌没有了说明已经达到了服务的处理上限,可直接返回秒杀失败防止服务被压垮,达到限流的目的。
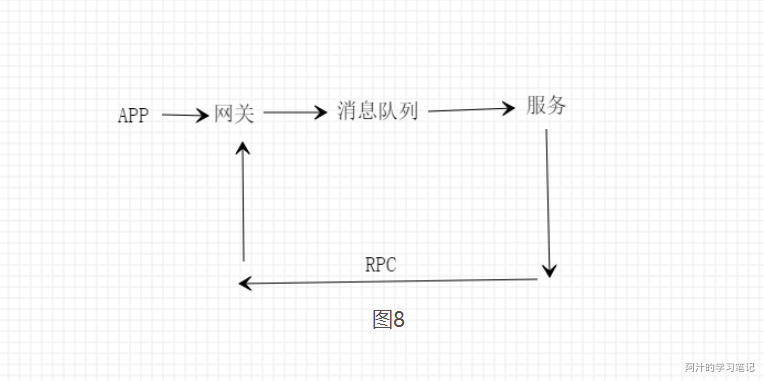
图8可能是和我一样的菜鸟同僚们能马上想到的一种队列的服务架构,请求到达网关后直接丢到消息队列中由对应的服务去消费,执行完成后通过rpc通知网关将结果返回给前端,如果请求超时或者队列满了可以直接返回请求失败,但是图8这种方式请求链比较长影响响应的时间同时异步处理会增加服务的复杂度,所以图7这种方式会更加合适一些。
至于文章开头说的微服务先放一放,太大了讲不来了~~~~~~
总结:以上就是小弟工作与学习中对高并发下服务器架构的一些理解,如果有错误的地方希望大佬们给予指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号