二叉搜索树与B树引入
二叉树的引入:
在一个链表之中,我们已知它的时间复杂度是O(N),。对于一个数组,我们可以通过二分搜索,来将寻找一个元素的时间复杂度降低为O(logN), 那么树的建立实际上就是对于链表进行的一个二分搜索。
我们要做的就是引入中间节点,以O(1)的复杂度到达链表中间;再翻转节点的指针,是能够遍历到左右两部分。
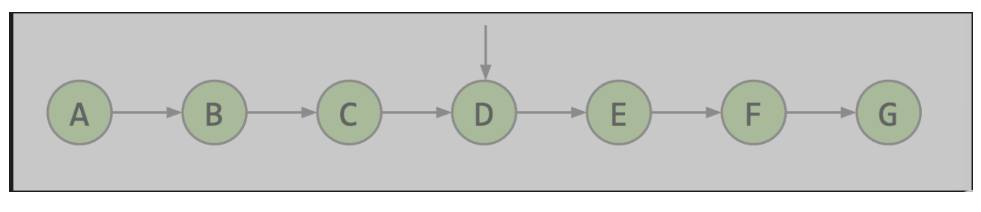
若将这个结构垂直拉伸,那么你就会发现你得到了一个树。
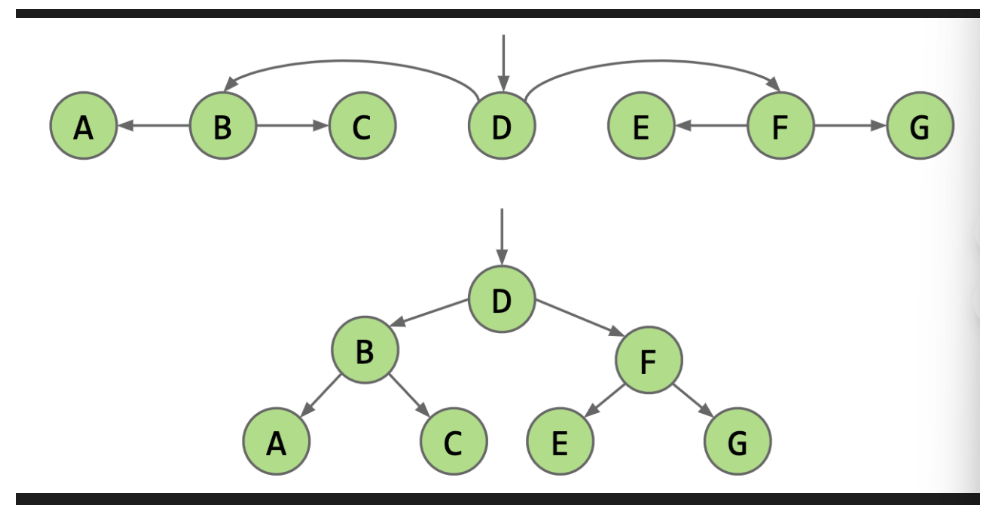
故有结论:带有递归中间指针的链表就是二叉树。
BST Definitions:
我们对于二叉树引入新的property约束:
对于二叉搜索树中的每一个节点Node X,
·左侧子树中的每一个值都小于X的值;
·右侧子树中的每一个值都大于X的值;
代码表现:
private class BST<Key> {
private key;
private BST left;
private BST right;
public BST(Key key, BST left, BST right){
this.key = key;
this.left = left;
this.right = right;
}
public BST(key){
this.key = key;
}
}

BST Operation:
Search
递归写法:
假设我们正在寻找的元素是X,从根节点开始,若X大于root, 则寻找root的右子树;若X小于root, 则寻找root的左子树。递归地重复这一操作,直到找到该元素,或是到达一个叶节点;
static BST find(BST T, Key sk){
if(T == null){
return null;
}
if (sk == T){
return T
}
else if (sk < T.key){
return find(T.left, sk);
}
else return find(T.right, sk);
}
如果搜索的是一个bushy tree, 则时间复杂度为O(logN), 即为树的最大height。
Insert:
由搜索的性质可知,
我们在树中搜索该节点,若已经找到该节点,则什么都不做;若未找到,则我们此时已经来到了恰当的叶节点处,将新元素添加到叶子的左侧或右侧即可。
static BST find(BST T, Key sk){
if(T == null){
return new BST(sk);
}
if(sk < T.key){
T.left = insert(T, sk);
}
else{
T.right = insert(T, sk);
}
return T;
}
Delete:
删除操作需要分为四种情况讨论:
· 该节点无child,为叶节点:
仅删除它的父指针,再释放它即可。
· 被删节点右子树为空,左子树非空:
用这个节点的左子女节点代替它的位置,即可。
· 被删节点左子树为空,右子树非空:
用右子女节点代替它的位置即可。
· 被删节点左右子树都不为空:
在右子树中寻找中序下的第一个节点,来取代他的位置——
满足是右子树中最小的,且大于左子树所有点。
代码实现:
bool remove(int target, Node ptr){
if(ptr != null){
if(target < ptr->data){
remove(target, ptr->left);
}
else if(target > ptr->data){
remove(target, ptr->right);
}
else if(ptr->left != null && ptr->right != null){
Node tmp = ptr;
while(tmp->left) tmp = tmp->left;
ptr->data = tmp->data;
remove(ptr->data, ptr->right);
}
else{ //只有一个非空或为叶节点
tmp = ptr;
if(ptr->left == null){
ptr = ptr->right;
}
else if(ptr->right == null){
ptr = ptr->left;
}
delete tmp; //释放老节点空间
return true;
}
return false;
}
}
AVL树:
定义:
- 左右子树均为AVL树。
- 左右子树高度差不超过1,高度之差称为该节点的平衡因子,即平衡因子只能取-1, 0, 1。
平衡化旋转:
主要包括两类——单旋转,双旋转。
执行时机:每插入一个新节点时,均需从当前位置向root回溯,检查路径上的平衡因子。
二叉查找树的扩展:
类比于线索二叉树——将每个节点扩展为:左子结点,键值,右子节点,左子结点标签,右子节点标签五个属性。
左子结点标签:若左子结点确实存在,标签为1;若左子结点为空,则指针指向比当前节点小一个的节点。
右子节点标签:若右子结点确实存在,标签为1;若右子结点为空,则指针指向比当前节点大一个的节点。
形如:
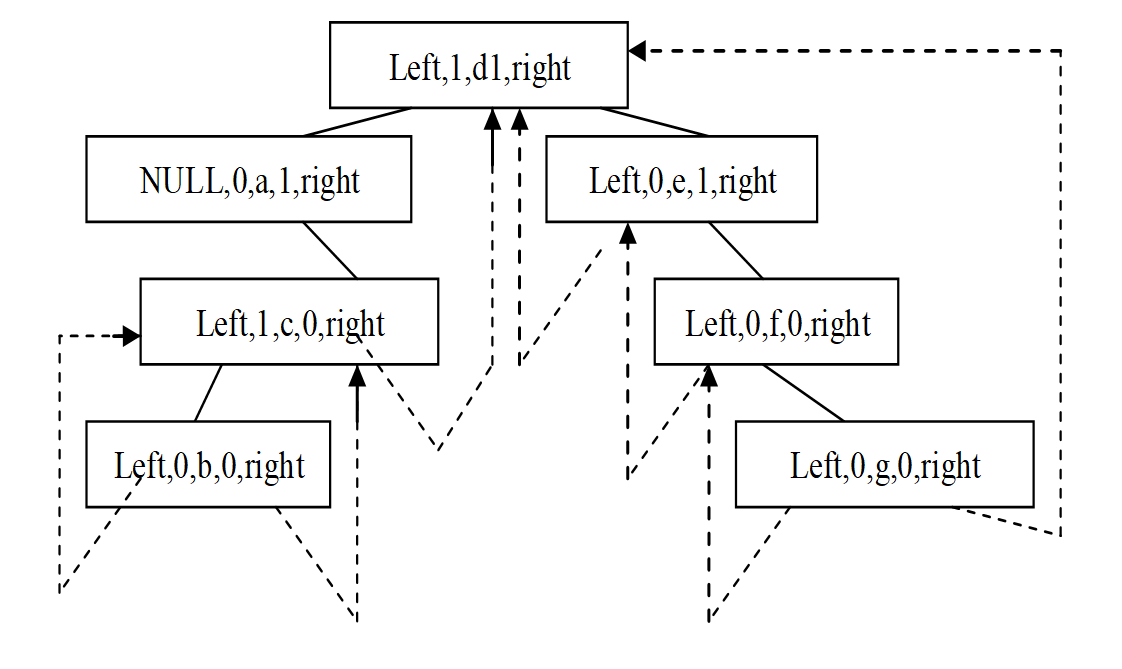
基于上述结构,对BST的搜索方法进行改造:
两个基本函数next和previous:
Node next(Node now){
Node tmp;
if(now->rightid = 0) return now->right;
else{
tmp = now->right;
while(tmp->left) tmp = tmp->left;
return tmp;
}
}
Node previous(Node now){
Node tmp;
if(now->leftid == 0) return now->left;
else{
tmp = now-> left;
while(tmp-right) tmp = tmp->right;
return tmp;
}
}
//基于next实现遍历由小到大
void search(Node root){
Node tmp = root;
while(tmp->leftid != 0) tmp = tmp->left;
cout<<tmp>data;
while(tmp){
tmp = next(tmp);
if(tmp) cout<<tmp>data;
}
}
最优二叉搜索树:
B-Trees的引入与操作:
引入的必要性:
BSTS的运行效率取决于树的height与aver-depth----高度决定了最坏运行情况时间,平均深度决定了搜索操作的平均运行时间;
而我们插入节点的顺序也会对树的形状造成影响:
按顺序,1,2,3,4,5,6,7插入节点,会得到一个高度为6,平均深度为3的细长BST;
而若按顺序:4,2,1,3,6,5,7插入相同节点,会得到更优的高度2与平均深度1.43.
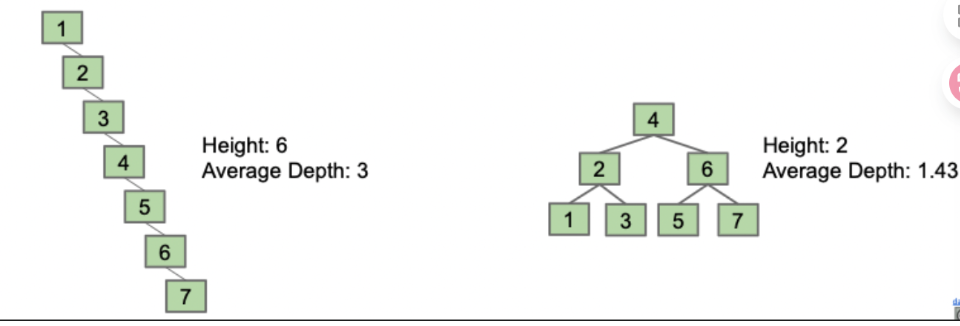
而由此可以得到若以随机方式插入节点,往往可以得到一个效率为O(logN)的bushy tree
但实际上很难以随机方式插入,因为我们不可能一开始就获得所有数据。
由此引入一个可以尽可能保持bushy-property的树,B-Trees。
B-Trees:
Avoid Imbalance:
我们要尽可能保持树的平衡,即在BST中添加新的叶子时,高度永不会增加,或增加得尽可能少。采取的一个策略是过度填充:将新值加入适当位置的现有节点中
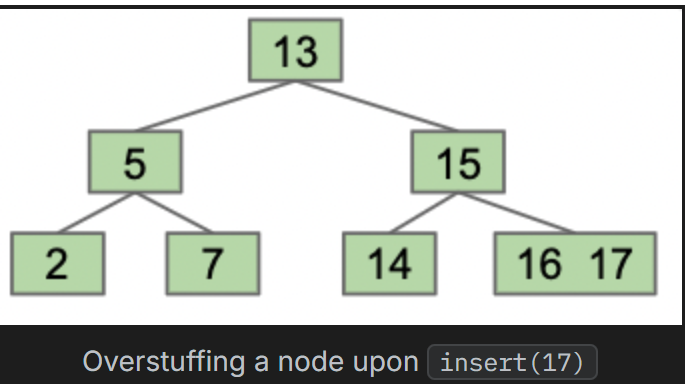
但这又会造成一个问题,遍历每一个节点时,又会呈现出线性时间。
Moving Items Up:
为了解决上述问题,采取策略是:为每一个节点设置一个limit值,每当超过limit值时,将left-middle的节点上移到父节点中。
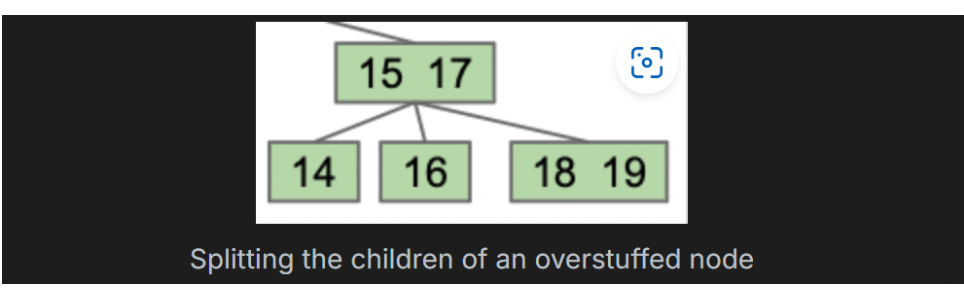
这种情况下搜索节点的范围划分为(-infty, 15)(15, 17)(17, infty)
假设我们设置的limit为L,则时间复杂度变为O(LlogN)实际上仍是O(logN)无变化。
Perfect Balance:
此结构具有完美的平衡。
若我们拆分根,则所有节点都会向下推一级。若我们拆分其他节点,则树的高度不发生改变,永远不会有不平衡的情况发生。
这种数据结构称为B-Trees。Limit为3的树,也被称为2-3-4树或2-4树(一个节点可以有2,3或4个节点)。Limit为2的树,会产生2-3个节点
Invariants:
由于B-Trees的构造方式,它具有如下的不变量:
1,所有叶子与根的距离都相同;
2,具有k个项的非叶节点,必须恰好有k+1个子节点。
此保证了B-Trees为O(logN)的bushy tree

 浙公网安备 33010602011771号
浙公网安备 33010602011771号