第一次个人编程作业
一、作业详情
| 课程 | 软件工程 |
|---|---|
| 要求 | 个人项目 |
| GitHub | GitHub |
| 目标 | 设计论文查重算法 |
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 40 |
| Estimate | 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 360 | 300 |
| Analysis | 需求分析 (包括学习新技术) | 350 | 450 |
| Design Spec | 生成设计文档 | 40 | 30 |
| Design Review | 设计复审 | 20 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 25 |
| Design | 具体设计 | 20 | 30 |
| Coding | 具体编码 | 80 | 50 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 40 | 70 |
| Reporting | 报告 | 30 | 50 |
| Test Repor | 测试报告 | 20 | 30 |
| Size Measurement | 计算工作量 | 20 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 50 | 60 |
| 合计 | 1440 | 1275 |
三、解题思路
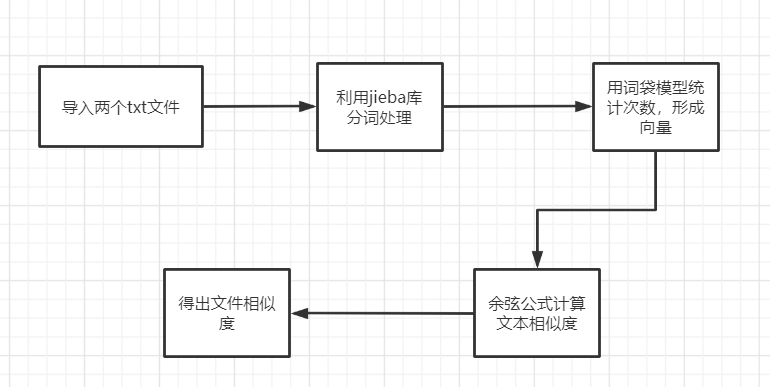
- 导入两个文本,用jieba库进行分词,编号,根据词袋模型统计形成每个词在文中出现的次数向量,用余弦公式计算文本相似度,通过计算得到文本相似度。
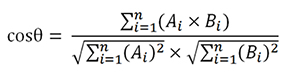
- 算法实现流程
四、实现过程
Ⅰ. jieba分词
stopwords=[]
s1_cut = [i for i in jieba.cut(s1, cut_all=True) if (i not in stopwords) and i!='']
s2_cut = [i for i in jieba.cut(s2, cut_all=True) if (i not in stopwords) and i!='']
word_set = set(s1_cut).union(set(s2_cut))
Ⅱ.统计每个词在文中出现的次数
s1_cut_code = [0]*len(word_dict)
for word in s1_cut:
s1_cut_code[word_dict[word]]+=1
s2_cut_code = [0]*len(word_dict)
for word in s2_cut:
s2_cut_code[word_dict[word]]+=1
Ⅲ.利用余弦相似度算法得出结果
sum = 0
sq1 = 0
sq2 = 0
for i in range(len(s1_cut_code)):
sum += s1_cut_code[i] * s2_cut_code[i]
sq1 += pow(s1_cut_code[i], 2)
sq2 += pow(s2_cut_code[i], 2)
try:
result = round(float(sum) / (math.sqrt(sq1) * math.sqrt(sq2)), 3)
except ZeroDivisionError:
result = 0.0
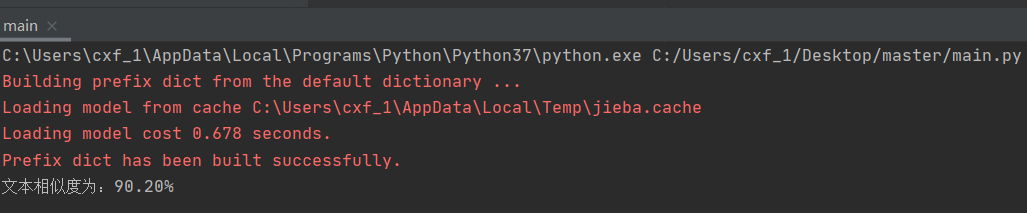
五、测试结果
参考文献
https://blog.csdn.net/u011596455/article/details/82888906
http://www.ruanyifeng.com/blog/2013/03/tf-idf.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号