Hadoop的读写操作、元数据及SecondaryNameNode、Checkpoint原理
一、写操作
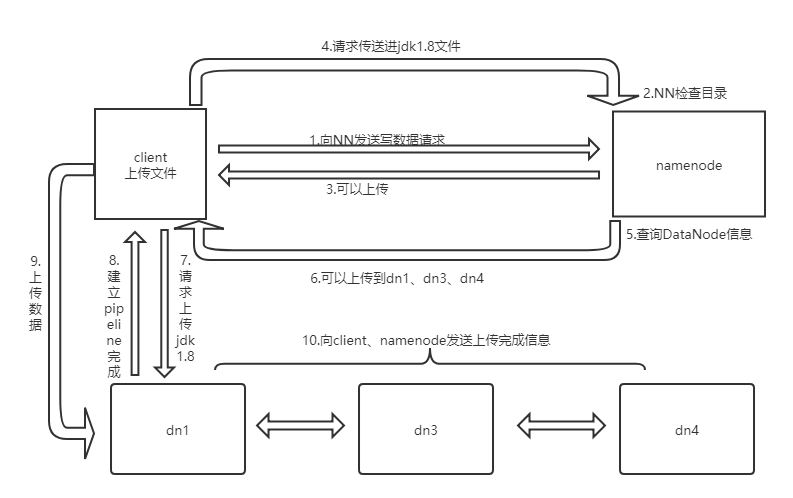
1)客户端通过Distributed FileSystem模块向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
2)namenode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存,然后才会写入本地磁盘),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。(重复执行3-7步)
二、读操作
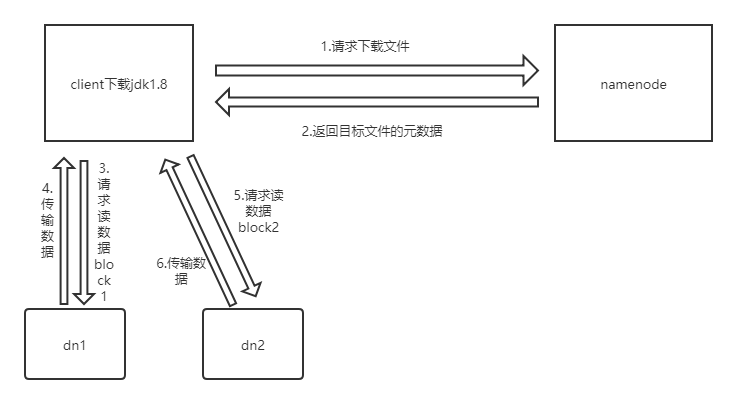
1.请求namenode 因为namenode元数据里面记录了DataNode的地址
2.把我们的信息返回给客户端
3.客户端收到信息之后 就到相应客户端去请求数据即可
4.重点是请求那个DataNode上的哪个块信息,因为namenode上存放的是块编号
三、元数据
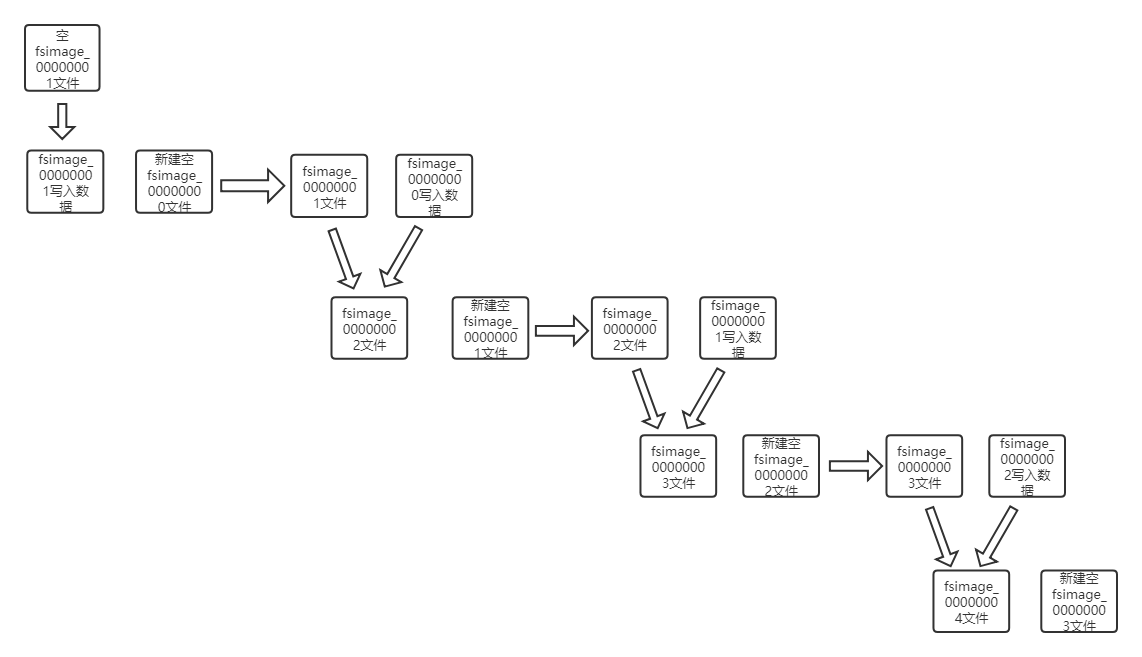
元数据保存在内存中,fsimage是元数据文件的存放方式,fsimage中的内容是各个文件的块信息
namenode中fsimage信息会每隔半小时更新一次,新文件与旧文件合并不断更新,在关闭时也会更新一次,开启时namenode会吧fsimage的数据加载到内存
四、namenode和SecondaryNameNode CheckPoint原理
在无Secondarynamenode时namenode要处理大量的客户端的请求还要每半小时把内存的数据同步到fsimage一次,为了减小namenode工作负担,设计出secondarynamenode。
secondarynamenode是对namenode的一个备份,它会下载namenode上的日志信息,根据日志生成fsimage实现对namenode的备份,把fsimage传给namenode,这时同步的任务交给secondarynamenode,namenode无需自己每半小时同步到fsimage。
不开启secondarynamenode的情况下,如果namenode挂掉就无法恢复。
1.secondary namenode请求主Namenode停止使用edits文件,暂时将新的写操作记录到一个新文件中,如edits.new。
2.secondary namenode节点从主Namenode节点获取fsimage和edits文件(采用HTTP GET)
3.secondary namenode将fsimage文件载入到内存,逐一执行edits文件中的操作,创建新的fsimage文件
4.secondary namenode将新的fsimage文件发送回主Namenode(使用HTTP POST)
5.主Namenode节点将从secondary namenode节点接收的fsimage文件替换旧的fsimage文件,用步骤1产生的edits.new文件替换旧的edits文件(即改名)。同时更新fstime文件来记录检查点执行的时间
注:从Hadoop0.21.0开始,辅助Namenode已经放弃不用,由checkpoint节点取而代之,功能不变。新版本同时引入一种新的Namenode,名为BackupNode

 浙公网安备 33010602011771号
浙公网安备 33010602011771号