pandas数据分析(二)
一、数据提取
1.1.按索引提取单行的数值
语法:
# 根据索引取值 df_inner.loc[3]
案例:
import pandas as pd import numpy as np # 示例数据 data = { 'age': [25, 30, 20, 35], 'name': ['小明', '小红', '小刚', '小美'], 'city': ['北京', '上海', '广州', '北京'], 'price': [2500, 4000, 1500, 3000], 'category': ['A-10', 'B-20', 'A-15', 'C-25'], 'date': pd.date_range(start='1/1/2013', periods=4) } # 创建DataFrame df_inner = pd.DataFrame(data) print("原始DataFrame:") print(df_inner) """ 原始DataFrame: age name city price category date 0 25 小明 北京 2500 A-10 2013-01-01 1 30 小红 上海 4000 B-20 2013-01-02 2 20 小刚 广州 1500 A-15 2013-01-03 3 35 小美 北京 3000 C-25 2013-01-04 """ # 1. 按索引提取单行的数值 row_3 = df_inner.loc[3] # 索引为3 print("\n按索引提取第3行的数值:") print(row_3) """ 按索引提取第3行的数值: age 35 name 小美 city 北京 price 3000 category C-25 date 2013-01-04 00:00:00 Name: 3, dtype: object """
1.2.按索引提取区域行数值
语法:
df_inner.iloc[0:3]
案例:
import pandas as pd import numpy as np # 示例数据 data = { 'age': [25, 30, 20, 35], 'name': ['小明', '小红', '小刚', '小美'], 'city': ['北京', '上海', '广州', '北京'], 'price': [2500, 4000, 1500, 3000], 'category': ['A-10', 'B-20', 'A-15', 'C-25'], 'date': pd.date_range(start='1/1/2013', periods=4) } # 创建DataFrame df_inner = pd.DataFrame(data) print("原始DataFrame:") print(df_inner) """ 原始DataFrame: age name city price category date 0 25 小明 北京 2500 A-10 2013-01-01 1 30 小红 上海 4000 B-20 2013-01-02 2 20 小刚 广州 1500 A-15 2013-01-03 3 35 小美 北京 3000 C-25 2013-01-04 """ # 按索引提取区域行数值 rows_0_2 = df_inner.iloc[0:3] print("\n按索引提取第0到2行的数值:") print(rows_0_2) """ 按索引提取第0到2行的数值: age name city price category date 0 25 小明 北京 2500 A-10 2013-01-01 1 30 小红 上海 4000 B-20 2013-01-02 2 20 小刚 广州 1500 A-15 2013-01-03 """
1.3.重设索引
语法:
df_inner.reset_index()
案例:
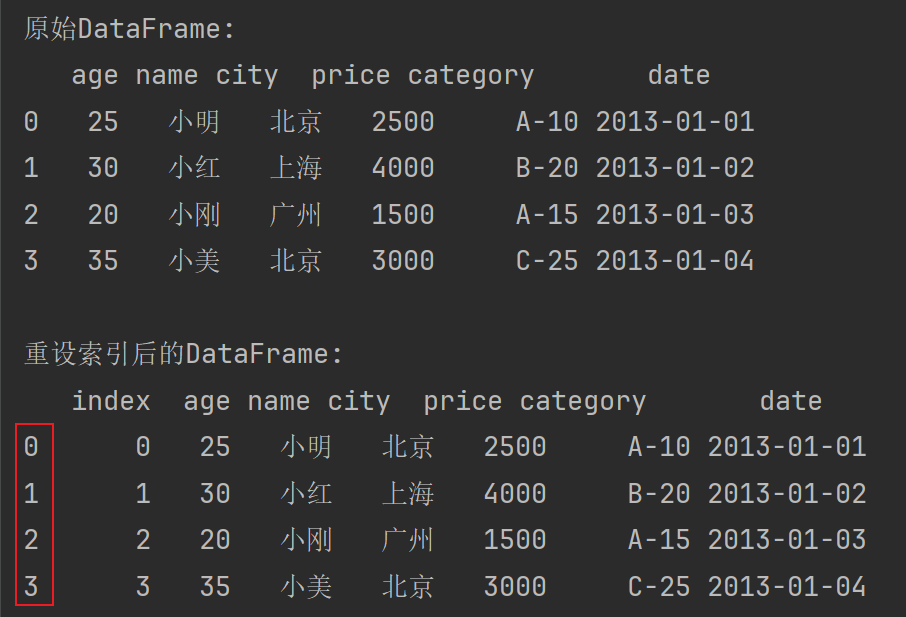
import pandas as pd import numpy as np # 示例数据 data = { 'age': [25, 30, 20, 35], 'name': ['小明', '小红', '小刚', '小美'], 'city': ['北京', '上海', '广州', '北京'], 'price': [2500, 4000, 1500, 3000], 'category': ['A-10', 'B-20', 'A-15', 'C-25'], 'date': pd.date_range(start='1/1/2013', periods=4) } # 创建DataFrame df_inner = pd.DataFrame(data) print("原始DataFrame:") print(df_inner) """ 原始DataFrame: age name city price category date 0 25 小明 北京 2500 A-10 2013-01-01 1 30 小红 上海 4000 B-20 2013-01-02 2 20 小刚 广州 1500 A-15 2013-01-03 3 35 小美 北京 3000 C-25 2013-01-04 """ # 重设索引 df_reset = df_inner.reset_index() print("\n重设索引后的DataFrame:") print(df_reset)
输出如下:
1.4.设置日期为索引
语法:将date列设置为索引
df_inner=df_inner.set_index('date')
案例:
# 设置日期为索引 df_inner.set_index('date', inplace=True) print("\n设置日期为索引后的DataFrame:") print(df_inner) """ 设置日期为索引后的DataFrame: age name city price category date 2013-01-01 25 小明 北京 2500 A-10 2013-01-02 30 小红 上海 4000 B-20 2013-01-03 20 小刚 广州 1500 A-15 2013-01-04 35 小美 北京 3000 C-25 """
1.5.提取3日之前的所有数据(包含3日)
语法:
df_inner[:'2013-01-03']
案例:需要先将date列设置为索引,然后在根据日期索引取值
import pandas as pd import numpy as np # 示例数据 data = { 'age': [25, 30, 20, 35], 'name': ['小明', '小红', '小刚', '小美'], 'city': ['北京', '上海', '广州', '北京'], 'price': [2500, 4000, 1500, 3000], 'category': ['A-10', 'B-20', 'A-15', 'C-25'], 'date': pd.date_range(start='1/1/2013', periods=4) } # 创建DataFrame df_inner = pd.DataFrame(data) print("原始DataFrame:") print(df_inner) """ 原始DataFrame: age name city price category date 0 25 小明 北京 2500 A-10 2013-01-01 1 30 小红 上海 4000 B-20 2013-01-02 2 20 小刚 广州 1500 A-15 2013-01-03 3 35 小美 北京 3000 C-25 2013-01-04 """ # 设置日期为索引 df_inner.set_index('date', inplace=True) print("\n设置日期为索引后的DataFrame:") print(df_inner) """ 设置日期为索引后的DataFrame: age name city price category date 2013-01-01 25 小明 北京 2500 A-10 2013-01-02 30 小红 上海 4000 B-20 2013-01-03 20 小刚 广州 1500 A-15 2013-01-04 35 小美 北京 3000 C-25 """ # 提取3日之前的所有数据 df_before_20130104 = df_inner[:'2013-01-03'] print("\n提取2013-01-03之前的所有数据(包含3日数据):") print(df_before_20130104) """ 提取2013-01-04之前的所有数据: age name city price category date 2013-01-01 25 小明 北京 2500 A-10 2013-01-02 30 小红 上海 4000 B-20 2013-01-03 20 小刚 广州 1500 A-15 """
1.6.使用iloc按位置区域提取数据
语法:
df_inner.iloc[:3,:2] #冒号前后的数字不再是索引的标签名称,而是数据所在的位置,从0开始,前三行,前两列。
案例:
# 使用 iloc 按位置区域提取数据 data_pos = df_inner.iloc[:3, :2] # 获取前3行2列的这个范围内的数据,df_inner.iloc[3, 2]指的是获取3行2列位置的数据 print("\n使用 iloc 按位置区域提取前三行前两列的数据:") print(data_pos) """ 使用 iloc 按位置区域提取前三行前两列的数据: age name 0 25 小明 1 30 小红 2 20 小刚 """
1.7.适应iloc按位置单独提起数据
语法:
df_inner.iloc[[0,2,5],[4,5]] #提取第0、2、5行,4、5列
案例:
# 使用 iloc 按位置单独提取数据 data_specific_pos = df_inner.iloc[[0, 2, 3], [1, 2]] print("\n使用 iloc 提取第0、2、3行,第1、2列的数据:") print(data_specific_pos)
df_inner.iloc[[0, 2, 3], [4, 5]] 返回指定行和列位置的数据,例如第0、2、3行和第1、2列的数据。

1.8.判断city列的值是否为北京
语法:
# 方式一:isin df_inner['city'].isin(['beijing']) # 方式二:== df_inner['city'] == '北京'
案例:
# 判断 city 列的值是否为北京 # is_bool = df_inner['city'] == '北京' is_bool = df_inner['city'].isin(['北京']) print("\n判断 city 列的值是否为北京:") print(is_bool) """ 判断 city 列的值是否为北京: 0 True 1 False 2 False 3 True Name: city, dtype: bool """
1.9.判断city列里是否包含beijing和shanghai,然后将符合条件的数据提取出来
语法:
df_inner.loc[df_inner['city'].isin(['beijing','shanghai'])]
案例:df_inner.loc[df_inner['city'].isin(['北京', '上海'])] 返回 city 列中包含北京或上海的所有行。
# 判断 city 列里是否包含北京和上海,然后将符合条件的数据提取出来 # df_inner['city'].isin(['北京', '上海'])返回的city列符合要求的返回true,不符合的返回false df_beijing_shanghai = df_inner.loc[df_inner['city'].isin(['北京', '上海'])] print("\n判断 city 列里是否包含北京和上海,提取符合条件的数据:") print(df_beijing_shanghai) """ 判断 city 列里是否包含北京和上海,提取符合条件的数据: age name city price category date 0 25 小明 北京 2500 A-10 2013-01-01 1 30 小红 上海 4000 B-20 2013-01-02 3 35 小美 北京 3000 C-25 2013-01-04 """
1.10.提取前三个字符,并生成数据表
语法:
pd.DataFrame(df_inner['category'].str[:3])
案例:df_inner['category'].str[:3] 提取 category 列中每个元素的前三个字符,并使用 pd.DataFrame() 创建一个新的 DataFrame。# 提取 category 列的前三个字符,并生成数据表
category_first3 = pd.DataFrame(df_inner['category'].str[:3]) print("\n提取 category 列的前三个字符,并生成数据表:") print(category_first3) """ 提取 category 列的前三个字符,并生成数据表: category 0 A-1 1 B-2 2 A-1 3 C-2 """
二、数据筛选
使用与、或、非三个条件配合大于、小于、等于对数据进行筛选,并进行计数和求和。
2.1.使用“与”进行筛选
筛选 age 大于 25 且 price 小于 3500 的数据:
import pandas as pd # 示例数据 data = { 'age': [25, 30, 20, 35, 28, 22], 'name': ['小明', '小红', '小刚', '小美', '小强', '小华'], 'city': ['北京', '上海', '广州', '北京', '上海', '广州'], 'price': [2500, 4000, 1500, 3000, 3500, 2800], 'category': ['A-10', 'B-20', 'A-15', 'C-25', 'B-30', 'A-20'], } # 创建DataFrame df_inner = pd.DataFrame(data) print("原始DataFrame:") print(df_inner) """ 原始DataFrame: age name city price category 0 25 小明 北京 2500 A-10 1 30 小红 上海 4000 B-20 2 20 小刚 广州 1500 A-15 3 35 小美 北京 3000 C-25 4 28 小强 上海 3500 B-30 5 22 小华 广州 2800 A-20 """ and_filtered = df_inner[(df_inner['age'] > 25) & (df_inner['price'] < 3500)] print("\n使用“与”进行筛选:") print(and_filtered) """ 使用“与”进行筛选: age name city price category 3 35 小美 北京 3000 C-25 """
2.2.使用“或”进行筛选
筛选 city 为 “北京” 或 price 大于 3000 的数据:
or_filtered = df_inner[(df_inner['city'] == '北京') | (df_inner['price'] > 3000)] print("\n使用“或”进行筛选:") print(or_filtered) """ 使用“或”进行筛选: age name city price category 0 25 小明 北京 2500 A-10 1 30 小红 上海 4000 B-20 3 35 小美 北京 3000 C-25 4 28 小强 上海 3500 B-30 """
2.3.使用“非”条件进行筛选
筛选 city 不等于 “广州” 的数据:
# ~取反 not_filtered = df_inner[~(df_inner['city'] == '广州')] print("\n使用“非”条件进行筛选:") print(not_filtered) """ 使用“非”条件进行筛选: age name city price category 0 25 小明 北京 2500 A-10 1 30 小红 上海 4000 B-20 3 35 小美 北京 3000 C-25 4 28 小强 上海 3500 B-30 """
2.4.对筛选后的数据按city列进行计数
value_counts() 是 pandas 中的一个方法,用于计算一个 Series 中每个唯一值的出现次数,并返回一个按降序排列的 Series。这个方法通常用于数据分析和数据清理过程中,以便快速了解数据的分布情况。
Series.value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
参数说明
- normalize: 布尔值,如果为 True,则返回相对频率(即每个唯一值的比例),而不是绝对频率。
- sort: 布尔值,如果为 True,则按值的频率排序。如果为 False,则按值的顺序排序。
- ascending: 布尔值,控制排序顺序。如果为 True,则按升序排列。
- bins: 整数,表示要将数据分成的等宽区间的数量。如果指定此参数,返回的是区间及其频率。
- dropna: 布尔值,控制是否包含 NaN 值。如果为 True,NaN 值将被忽略。
统计了在筛选后的数据中每个城市(city 列的唯一值)出现的次数。
# 筛选 price 大于 2500 的数据 filtered_data = df_inner[df_inner['price'] > 2500] """ age name city price category 1 30 小红 上海 4000 B-20 3 35 小美 北京 3000 C-25 4 28 小强 上海 3500 B-30 5 22 小华 广州 2800 A-20 """ # 对筛选后的数据按 city 列进行计数 city_counts = filtered_data['city'].value_counts() print("\n筛选后的数据按 city 列进行计数:") print(city_counts) """ 筛选后的数据按 city 列进行计数: city 上海 2 北京 1 广州 1 """
2.5.使用query函数进行筛选
筛选 age 大于 25 且 price 小于 3500 的数据:
query_filtered = df_inner.query('age > 25 and price < 3500') print("\n使用 query 函数进行筛选:") print(query_filtered) """ 使用 query 函数进行筛选: age name city price category 3 35 小美 北京 3000 C-25 """
2.6.对筛选后的结果按price进行求和
sum() 函数在 pandas 中用于对 DataFrame 或 Series 进行求和操作。它可以对每列或每行的数值进行求和,返回一个包含求和结果的 Series。这个函数广泛用于数据分析和处理任务中。
语法
DataFrame.sum(axis=None, skipna=True, level=None, numeric_only=None, min_count=0) Series.sum(axis=None, skipna=True, level=None, numeric_only=None, min_count=0)
参数说明
- axis: 控制求和的方向。
0或'index'表示按列求和(即对每列的所有值求和),1或'columns'表示按行求和(即对每行的所有值求和)。默认值为0。 - skipna: 布尔值,表示是否忽略缺失值(NaN)。如果为 True(默认值),则忽略 NaN 值进行求和。
- level: 如果指定了 MultiIndex(多级索引),可以沿着指定级别进行聚合。
- numeric_only: 布尔值或 None。若为 True,则只包括数字列。如果为 None,则尝试包括所有列。
- min_count: 整数,表示需要参与求和操作的最少非 NaN 元素个数。如果少于该数目,则返回 NaN。
案例:对于price 大于 2500 的数据进行求和:
import pandas as pd # 示例数据 data = { 'age': [25, 30, 20, 35, 28, 22], 'name': ['小明', '小红', '小刚', '小美', '小强', '小华'], 'city': ['北京', '上海', '广州', '北京', '上海', '广州'], 'price': [2500, 4000, 1500, 3000, 3500, 2800], 'category': ['A-10', 'B-20', 'A-15', 'C-25', 'B-30', 'A-20'], } # 创建DataFrame df_inner = pd.DataFrame(data) print("原始DataFrame:") print(df_inner) """ 原始DataFrame: age name city price category 0 25 小明 北京 2500 A-10 1 30 小红 上海 4000 B-20 2 20 小刚 广州 1500 A-15 3 35 小美 北京 3000 C-25 4 28 小强 上海 3500 B-30 5 22 小华 广州 2800 A-20 """ # 1.筛选 price 大于 2500 的数据 filtered_data = df_inner[df_inner['price'] > 2500] print(filtered_data) """ age name city price category 1 30 小红 上海 4000 B-20 3 35 小美 北京 3000 C-25 4 28 小强 上海 3500 B-30 5 22 小华 广州 2800 A-20 """ # 2.对筛选后的结果按 price 进行求和 and_price_sum = filtered_data['price'].sum() print("\n对于price 大于 2500 的数据进行求和: ") print(and_price_sum) """ 按“与”条件筛选后的结果按 price 进行求和: 13300 """
三、数据汇总
3.1.对所有的列进行计数汇总
groupby() 函数是 pandas 中的一个重要方法,用于对数据进行分组,然后对每个组应用聚合函数。它类似于 SQL 中的 GROUP BY 操作,是数据分组和汇总的核心工具。
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=NoDefault.no_default, observed=False, dropna=True)
参数说明
- by: 用于分组的列名、数组、列表、字典或函数。
- axis: 控制分组的方向。
0或'index'表示按行分组,1或'columns'表示按列分组。默认值为0。 - level: 如果使用 MultiIndex(多级索引),则可以指定索引级别进行分组。
- as_index: 布尔值,默认为 True。若为 True,则分组键成为结果的索引;若为 False,则分组键作为列保留在结果中。
- sort: 布尔值,默认为 True。若为 True,则按分组键对结果进行排序;若为 False,则保持输入顺序。
- group_keys: 布尔值,默认为 True。若为 True,则将分组键加到结果中。
- squeeze: 布尔值,默认为 NoDefault.no_default。若为 True,则如果结果是单列 Series,则返回 Series 而不是 DataFrame。
- observed: 布尔值,默认为 False。若为 True,则仅保留分组键的观察值(用于分类数据)。
- dropna: 布尔值,默认为 True。若为 True,则丢弃所有含有 NaN 值的分组。
案例:按照 city 列对数据进行分组,并对每一列的数据进行计数。
import pandas as pd # 示例数据 data = { 'id': [1, 2, 3, 4, 5, 6], 'age': [25, 30, 20, 35, 28, 22], 'name': ['小明', '小红', '小刚', '小美', '小强', '小华'], 'city': ['北京', '上海', '广州', '北京', '上海', '广州'], 'price': [2500, 4000, 1500, 3000, 3500, 2800], 'category': ['A-10', 'B-20', 'A-15', 'C-25', 'B-30', 'A-20'], 'size': ['S', 'M', 'S', 'L', 'M', 'S'] } # 创建DataFrame df_inner = pd.DataFrame(data) print("原始DataFrame:") print(df_inner) count_all = df_inner.groupby('city').count() print("\n对所有的列进行计数汇总:") print(count_all) """ city 上海 2 2 2 2 2 2 北京 2 2 2 2 2 2 广州 2 2 2 2 2 2 """
3.2.按城市对id字段进行计数
语法:
df_inner.groupby('city')['id'].count()
案例:按照 city 列对数据进行分组,并对 id 列进行计数。
count_id = df_inner.groupby('city')['id'].count() print("\n按城市对 id 字段进行计数:") print(count_id) """ 按城市对 id 字段进行计数: city 上海 2 北京 2 广州 2 Name: id, dtype: int64 """
3.3.对两个字段进行汇总计数
语法:
df_inner.groupby(['city','size'])['id'].count()
案例:按照 city 和 size 列对数据进行分组,并对 id 列进行计数
count_two_fields = df_inner.groupby(['city', 'size'])['id'].count() print("\n对两个字段进行汇总计数:") print(count_two_fields) """ 对两个字段进行汇总计数: city size 上海 M 2 北京 L 1 S 1 广州 S 2 Name: id, dtype: int64 """
3.4.对city字段进行汇总,并分别计算prince的合计和均值
agg() 函数在 pandas 中用于对 DataFrame 或 Series 执行一组聚合操作。它允许你同时应用多个聚合函数,可以对不同的列应用不同的聚合操作,从而提供了灵活和强大的数据汇总功能。语法
DataFrame.agg(func=None, axis=0, *args, **kwargs) Series.agg(func=None, axis=0, *args, **kwargs)
参数说明
- func: 聚合函数或函数名的字符串、列表或字典。可以是单个函数、函数名的字符串,或者这些元素组成的列表或字典。
- axis: 控制聚合操作的方向。
0或'index'表示按列聚合,1或'columns'表示按行聚合。默认值为0。 - args: 传递给聚合函数的位置参数。
- kwargs: 传递给聚合函数的关键字参数。
⑴.对 DataFrame 应用单个聚合函数
# 示例 DataFrame df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}) # 对 DataFrame 应用单个聚合函数 result = df.agg('sum') print("DataFrame sum by columns:\n", result)
输出:
DataFrame sum by columns: A 6 B 15 C 24 dtype: int64
⑵.对 DataFrame 应用多个聚合函数
# 对 DataFrame 应用多个聚合函数 result = df.agg(['sum', 'mean']) print("DataFrame multiple aggregations by columns:\n", result)
输出:
DataFrame multiple aggregations by columns: A B C sum 6.0 15.0 24.0 mean 2.0 5.0 8.0
⑶.案例:按照 city 列对数据进行分组,并对 price 列进行统计,计算数据的数量、总和和均值。
# 对 city 字段进行汇总,并分别计算 price 的合计和均值 agg_price = df_inner.groupby('city')['price'].agg([len, 'sum', 'mean']) print("\n对 city 字段进行汇总,并分别计算 price 的合计和均值:") print(agg_price) """ 对 city 字段进行汇总,并分别计算 price 的合计和均值: len sum mean city 上海 2 7500 3750.0 北京 2 5500 2750.0 """
四、数据统计
数据统计解释总结:
- 采样:用于从数据中获取子集,以便进一步分析或建模。
- 描述性统计:提供数据的基本特征,帮助理解数据分布和变异性。
- 标准差:衡量数据的离散程度。
- 协方差:度量两个变量之间的共同变动程度。
- 相关系数:评估两个变量之间的线性关系。
4.1.简单的数据采样
sample_simple = df_inner.sample(n=3) print("\n简单的数据采样:") print(sample_simple)
作用和含义:
- 作用:从数据集中随机抽取 3 条记录。
- 含义:简单随机采样有助于获取数据的代表性样本,用于进一步分析或测试。
4.2.手动设置采样权重
weights = [0, 0, 0, 0, 0.5, 0.5] sample_weights = df_inner.sample(n=2, weights=weights) print("\n手动设置采样权重:") print(sample_weights)
作用和含义:
- 作用:根据指定的权重进行随机抽样,权重较大的记录被抽中的概率较高。
- 含义:权重采样用于在抽样过程中赋予某些记录更高的优先级,适用于偏好特定记录的场景。
4.3.采样后不放回
sample_no_replace = df_inner.sample(n=6, replace=False) print("\n采样后不放回:") print(sample_no_replace)
作用和含义:
- 作用:从数据集中随机抽取 6 条记录,不放回,即每条记录只能被抽取一次。
- 含义:不放回抽样确保每条记录只能出现一次,用于需要唯一样本的情况
4.4.采样后放回
sample_replace = df_inner.sample(n=6, replace=True) print("\n采样后放回:") print(sample_replace)
作用和含义:
- 作用:从数据集中随机抽取 6 条记录,放回,即同一条记录可以被抽取多次。
- 含义:放回抽样允许重复记录,适用于需要模拟重复试验的情况
4.5.数据表描述性统计
desc_stats = df_inner.describe().round(2).T print("\n数据表描述性统计:") print(desc_stats)
作用和含义:
- 作用:生成数据表的描述性统计信息,包括计数、均值、标准差、最小值、四分位数和最大值。
- 含义:描述性统计提供数据的基本特征概览,帮助理解数据分布和变异性。
4.6.计算列的标准差
std_price = df_inner['price'].std() print("\n计算列的标准差:") print(f"price 列的标准差: {std_price:.2f}")
作用和含义:
- 作用:计算
price列的标准差。 - 含义:标准差度量数据的离散程度,表示价格数据的波动范围。
4.7.计算两个字段间的协方差
cov_price_mpoint = df_inner['price'].cov(df_inner['m-point']) print("\n计算两个字段间的协方差:") print(f"price 和 m-point 列的协方差: {cov_price_mpoint:.2f}")
作用和含义:
- 作用:计算
price和m-point列的协方差。 - 含义:协方差度量两个变量共同变化的方向和程度,正值表示正相关,负值表示负相关。
4.8.数据表中所有字段间的协方差
pandas 在计算协方差矩阵时需要将所有列转换为浮点数,这些非数值类型的数据会导致转换失败。
# 8.数据表中所有字段间的协方差 # select_dtypes(include=[float, int]) 方法选择所有数值类型的列,然后对选中的数值类型列计算协方差。 df_numeric = df_inner.select_dtypes(include=[float, int]) cov_all = df_numeric.cov() print("\n数据表中所有字段间的协方差:") print(cov_all) """ 数据表中所有字段间的协方差: id age price m-point id 3.5 -0.600000 150.000000 4.5 age -0.6 30.266667 3153.333333 -11.8 price 150.0 3153.333333 741666.666667 2450.0 m-point 4.5 -11.800000 2450.000000 51.5 """
作用和含义:
- 作用:计算数据表中float、int字段间的协方差矩阵。
- 含义:协方差矩阵展示了所有变量之间的协方差关系,帮助理解变量间的共同变动情况。
4.9.两个字段的相关性分析
corr_price_mpoint = df_inner['price'].corr(df_inner['m-point']) print("\n两个字段的相关性分析:") print(f"price 和 m-point 列的相关系数: {corr_price_mpoint:.2f}")
作用和含义:
- 作用:计算
price和m-point列的相关系数。 - 含义:相关系数度量两个变量间的线性关系,值在 -1 到 1 之间,接近 1 表示强正相关,接近 -1 表示强负相关,接近 0 表示无相关性。
4.10.数据表的相关性分析
pandas 在计算相关性矩阵时需要将所有列转换为浮点数,所以需要选择数值列或者数组均为数值才可以。
# 选择数值类型的列 df_numeric = df_inner.select_dtypes(include=[float, int]) corr_all = df_numeric.corr() print("\n数据表的相关性分析:") print(corr_all)
作用和含义:
- 作用:计算数据表中数值字段间的相关系数矩阵。
- 含义:相关系数矩阵展示了所有变量之间的线性关系,有助于识别显著相关的变量对。
完整代码:
import pandas as pd import numpy as np # 示例数据 data = { 'id': [1, 2, 3, 4, 5, 6], 'age': [25, 30, 20, 35, 28, 22], 'name': ['小明', '小红', '小刚', '小美', '小强', '小华'], 'city': ['北京', '上海', '广州', '北京', '上海', '广州'], 'price': [2500, 4000, 1500, 3000, 3500, 2800], 'category': ['A-10', 'B-20', 'A-15', 'C-25', 'B-30', 'A-20'], 'm-point': [80, 90, 85, 75, 95, 88] } # 创建DataFrame df_inner = pd.DataFrame(data) print("原始DataFrame:") print(df_inner) """ 原始DataFrame: id age name city price category m-point 0 1 25 小明 北京 2500 A-10 80 1 2 30 小红 上海 4000 B-20 90 2 3 20 小刚 广州 1500 A-15 85 3 4 35 小美 北京 3000 C-25 75 4 5 28 小强 上海 3500 B-30 95 5 6 22 小华 广州 2800 A-20 88 """ # 1.简单的数据采样 sample_simple = df_inner.sample(n=3) # print(sample_simple) # 2.手动设置采样权重 weights = [0, 0, 0, 0, 0.5, 0.5] sample_weights = df_inner.sample(n=2, weights=weights) print("\n手动设置采样权重:") print(sample_weights) """ 手动设置采样权重: 由于前四条权重为0,则没有出现 id age name city price category m-point 4 5 28 小强 上海 3500 B-30 95 5 6 22 小华 广州 2800 A-20 88 """ # 3.采样后不放回 sample_no_replace = df_inner.sample(n=3, replace=False) print("\n采样后不放回:") print(sample_no_replace) # 4.采样后放回 sample_replace = df_inner.sample(n=6, replace=True) print("\n采样后放回:") print(sample_replace) # 5.数据表描述性统计 desc_stats = df_inner.describe().round(2).T print("\n数据表描述性统计:") print(desc_stats) """ 数据表描述性统计:包括计数、均值、标准差、最小值、四分位数和最大值。 count mean std min 25% 50% 75% max id 6.0 3.50 1.87 1.0 2.25 3.5 4.75 6.0 age 6.0 26.67 5.50 20.0 22.75 26.5 29.50 35.0 price 6.0 2883.33 861.20 1500.0 2575.00 2900.0 3375.00 4000.0 m-point 6.0 85.50 7.18 75.0 81.25 86.5 89.50 95.0 """ # 6.计算列的标准差 std_price = df_inner['price'].std() print("\n计算列的标准差:") print(f"price 列的标准差: {std_price:.2f}") """ 计算列的标准差: price 列的标准差: 861.20 """ # 7.计算两个字段间的协方差 cov_price_mpoint = df_inner['price'].cov(df_inner['m-point']) print("\n计算两个字段间的协方差:") print(f"price 和 m-point 列的协方差: {cov_price_mpoint:.2f}") """ 计算两个字段间的协方差: price 和 m-point 列的协方差: 2450.00 """ # 8.数据表中所有字段间的协方差 # select_dtypes(include=[float, int]) 方法选择所有数值类型的列,然后对选中的数值类型列计算协方差。 df_numeric = df_inner.select_dtypes(include=[float, int]) cov_all = df_numeric.cov() print("\n数据表中所有字段间的协方差:") print(cov_all) """ 数据表中所有字段间的协方差: id age price m-point id 3.5 -0.600000 150.000000 4.5 age -0.6 30.266667 3153.333333 -11.8 price 150.0 3153.333333 741666.666667 2450.0 m-point 4.5 -11.800000 2450.000000 51.5 """ # 9.两个字段的相关性分析 corr_price_mpoint = df_inner['price'].corr(df_inner['m-point']) print("\n两个字段的相关性分析:") print(f"price 和 m-point 列的相关系数: {corr_price_mpoint:.2f}") """ 两个字段的相关性分析: price 和 m-point 列的相关系数: 0.40 """ # 10.数据表的相关性分析 # 选择数值类型的列 df_numeric = df_inner.select_dtypes(include=[float, int]) corr_all = df_numeric.corr() print("\n数据表的相关性分析:") print(corr_all) """ 数据表的相关性分析: id age price m-point id 1.000000 -0.058295 0.093101 0.335178 age -0.058295 1.000000 0.665554 -0.298879 price 0.093101 0.665554 1.000000 0.396422 m-point 0.335178 -0.298879 0.396422 1.000000 """
五、数据输出
分析后的数据可以输出为xlsx格式和csv格式
5.1.写入Excel
将数据写入到Excel

语法:
df_inner.to_excel('excel_to_python.xlsx', sheet_name='data')
生成Excel如下:

5.2.写入到CSV
语法:
df_inner.to_csv('csv_to_python.xlsx')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号