102302110高悦作业3
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
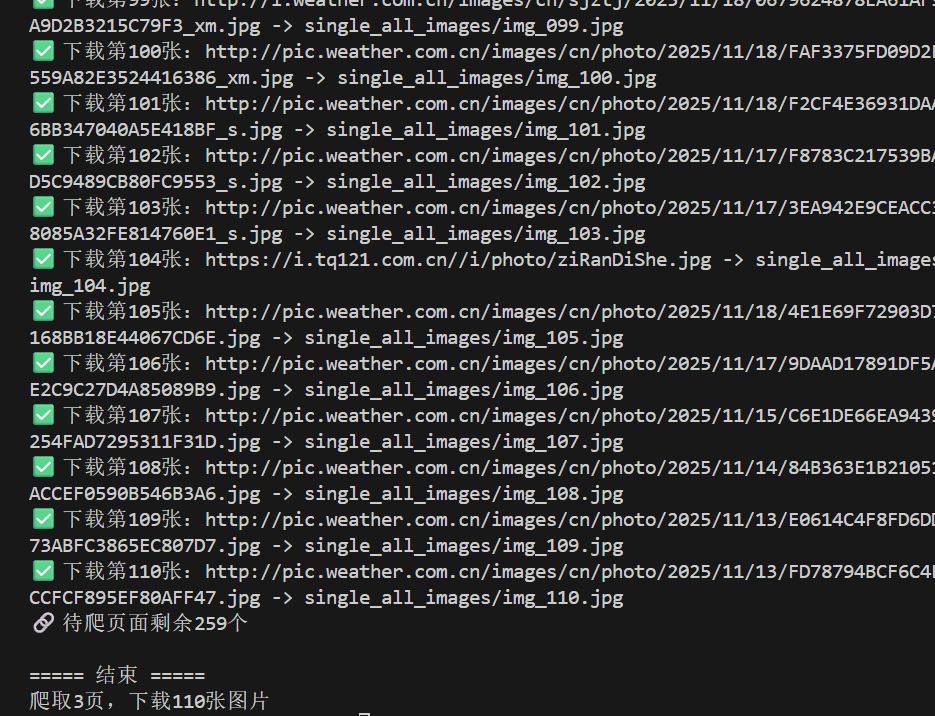
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
1.实现过程及代码
1.1 单线程
1.1.1获取网页的内容
def get_html(url):
try:
headers = {"User-Agent": random.choice(USER_AGENTS)}
resp = requests.get(url, headers=headers, timeout=10)
resp.encoding = "utf-8"
time.sleep(2)
return resp.text if resp.status_code == 200 else None
except Exception as e:
return None
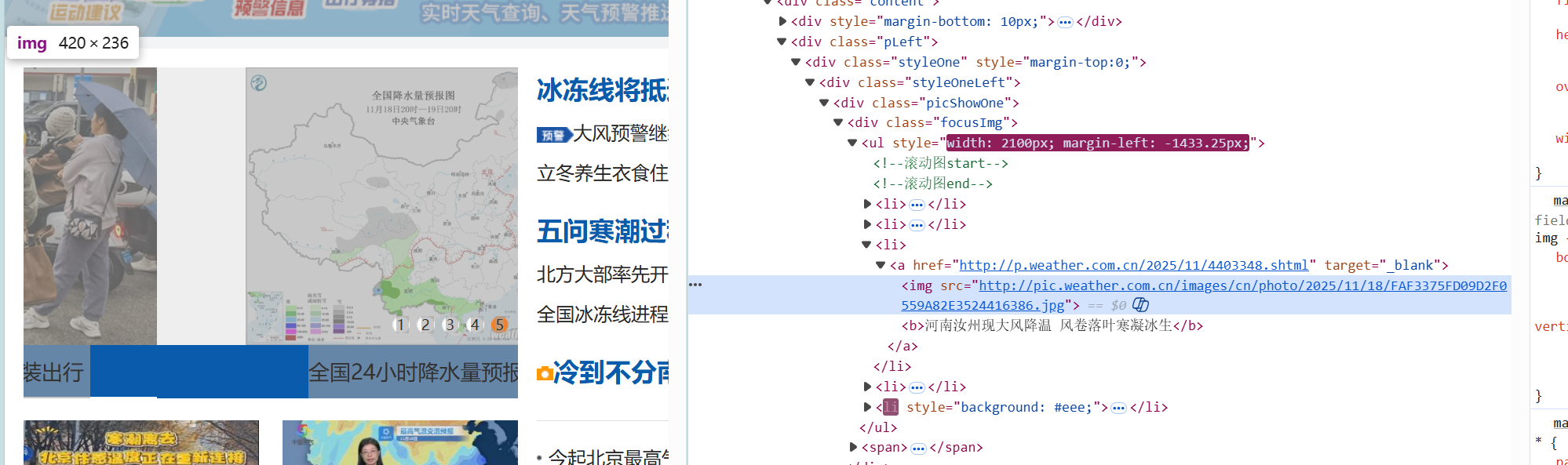
通过观察可知,网页中的图片都是以"img src"的形式显示,通过bs4将其提取出来
def extract_all_images(html, base_url):
soup = BeautifulSoup(html, "html.parser")
all_imgs = soup.find_all("img")
img_urls = []
for img in all_imgs:
# 提取图片链接(支持src、data-src、data-original等常见属性)
img_src = img.get("src") or img.get("data-src") or img.get("data-original")
if not img_src:
continue # 没有链接的跳过
full_url = urljoin(base_url, img_src)
return img_urls
地址:https://gitee.com/augtrqv/shoren/blob/master/作业3/第一题单线程.py
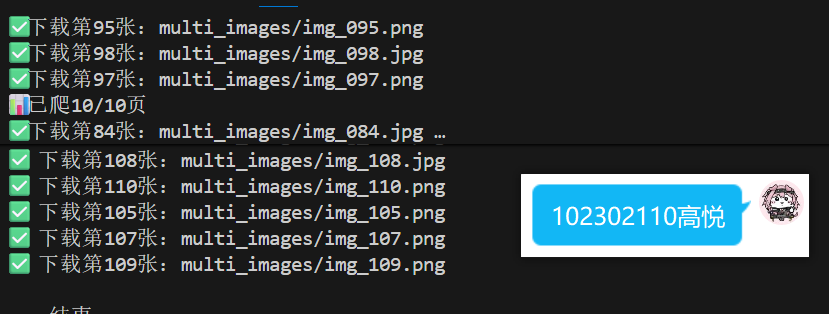
1.2 多线程
一共设置了6个线程:3个负责页面爬取,另外3个负责图片的下载
爬取线程:
def page_worker():
global crawled_pages_count
while not stop_event.is_set() and crawled_pages_count < MAX_PAGES:
try:
url = url_queue.get(timeout=2)
except:
break
with lock: # 锁保护访问visited_urls
if url in visited_urls or stop_event.is_set():
url_queue.task_done()
continue
visited_urls.add(url)
html = fetch_html(url)
if html and not stop_event.is_set():
img_urls = extract_images(html, url)
if img_urls:
with lock: # 锁保护读取计数器
remaining = MAX_IMAGES - downloaded_images_count
if remaining <= 0:
stop_event.set()
url_queue.task_done()
break
img_urls = img_urls[:remaining] # 只添加剩余所需数量
for img in img_urls:
if stop_event.is_set():
break
img_queue.put(img)
new_links = extract_links(html, url)
if new_links and crawled_pages_count < MAX_PAGES and not stop_event.is_set():
for link in new_links:
url_queue.put(link)
with lock: # 锁保护更新页数
crawled_pages_count += 1
url_queue.task_done()
if stop_event.is_set():
break
下载线程:
def img_worker():
global downloaded_images_count
while not stop_event.is_set():
# 先检查是否已达标,避免无效取任务
with lock:
if downloaded_images_count >= MAX_IMAGES:
stop_event.set()
break
try:
img_url = img_queue.get(timeout=2)
except:
# 队列空且达标,退出
with lock:
if downloaded_images_count >= MAX_IMAGES:
stop_event.set()
break
# 核心修复:获取唯一编号(全程锁保护,确保原子操作)
current_idx = None
with lock:
# 再次检查,防止多线程竞争导致超额
if downloaded_images_count >= MAX_IMAGES:
stop_event.set()
img_queue.task_done()
break
current_idx = downloaded_images_count + 1 # 分配唯一编号
downloaded_images_count = current_idx # 立即更新计数器
try:
if stop_event.is_set():
img_queue.task_done()
break
resp = requests.get(img_url, timeout=10)
if resp.status_code == 200 and not stop_event.is_set():
ext = "jpg" if ".jpg" in img_url else "png"
filename = f"{SAVE_FOLDER}/img_{current_idx:03d}.{ext}"
with open(filename, "wb") as f:
f.write(resp.content)
# 达标后清空队列
if current_idx == MAX_IMAGES:
stop_event.set()
# 清空残留任务
while not img_queue.empty():
img_queue.get()
img_queue.task_done()
break
except Exception as e:
print(f"图片{img_url}下载失败(编号{current_idx}):{e}")
finally:
img_queue.task_done()
地址:https://gitee.com/augtrqv/shoren/blob/master/作业3/第一题多线程.py
2.实验的心得
我的多线程代码在刚开始特别容易卡死,即已经爬完了110张图片但是无法退出。而且还出现了下载的数量混乱的问题,即不同的线程对共享计数器的竞争。我通过用锁和“超时 + 停止信号”来处理这两个问题,对多线程的处理需要更多的思考。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
1.实验过程及代码
在mysql创建数据库

同作业2,分析网页的数据
编写items.py,规定爬取的数据以及数据格式
import scrapy
class StockItem(scrapy.Item):
"""沪深A股个股数据模型(字段与数据库对应)"""
serial_num = scrapy.Field() # 序号(自增)
stock_code = scrapy.Field() # 股票代码(6位数字)
stock_name = scrapy.Field() # 股票名称
latest_price = scrapy.Field() # 最新价(元)
price_change = scrapy.Field() # 涨跌额(元)
price_change_rate = scrapy.Field()# 涨跌幅(带%)
volume = scrapy.Field() # 成交量(万手)
turnover = scrapy.Field() # 成交额(亿元)
amplitude = scrapy.Field() # 振幅(%)
highest_price = scrapy.Field() # 当日最高价(元)
lowest_price = scrapy.Field() # 当日最低价(元)
opening_price = scrapy.Field() # 当日开盘价(元)
previous_close = scrapy.Field() # 昨日收盘价(元)
def process_item(self, item, spider):
sql = '''
INSERT INTO stock_table (serial_num, stock_code, ...)
VALUES (%s, %s, ...)
'''
params = (item['serial_num'], item['stock_code'], ...) # Item字段对应SQL占位符
try:
self.cursor.execute(sql, params)
self.conn.commit() # 提交事务
return item
except Exception as e:
self.conn.rollback() # 出错回滚
spider.logger.error(f"插入失败:{str(e)}")
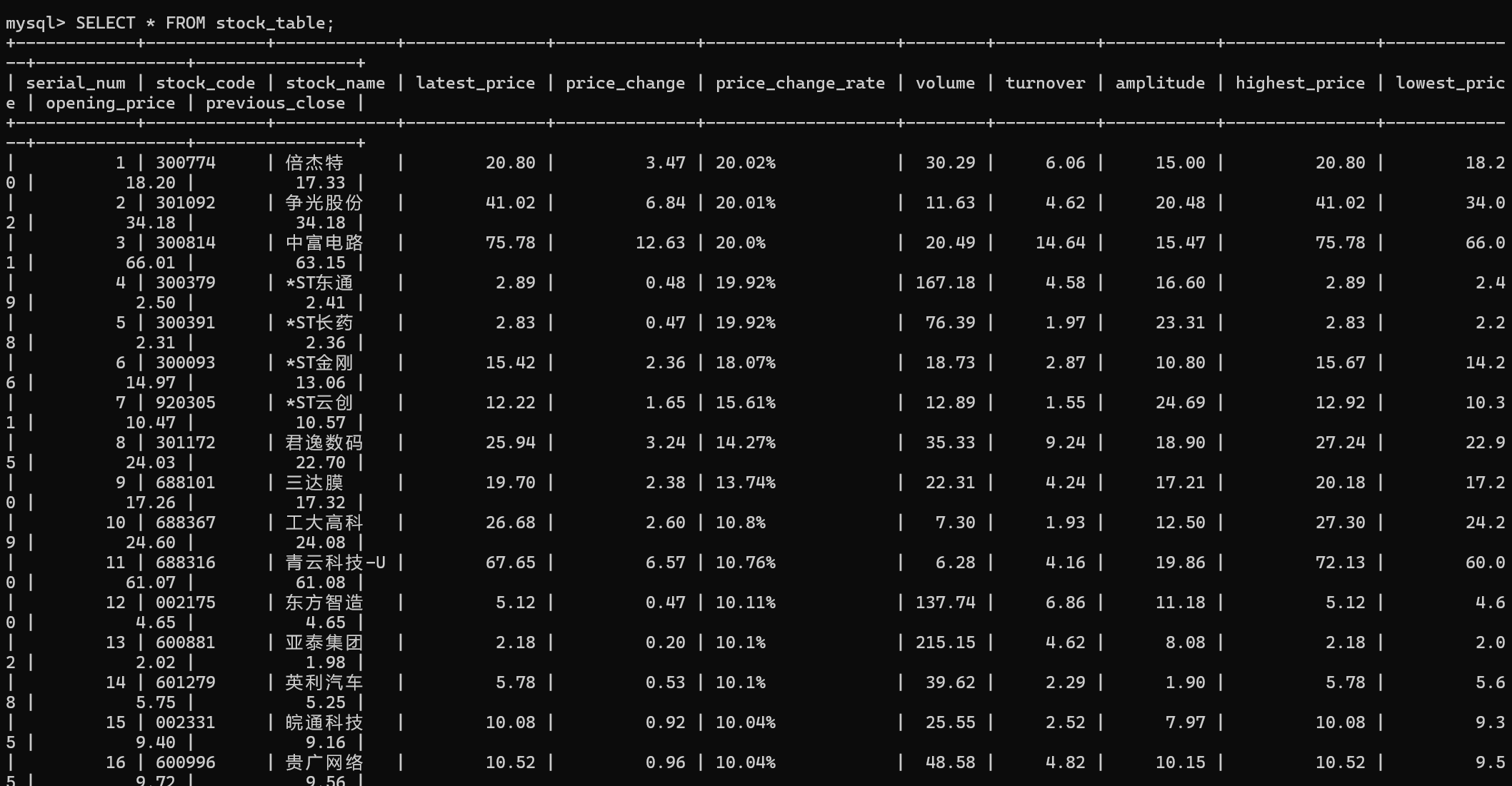
在mysql里查看
地址:https://gitee.com/augtrqv/shoren/tree/master/作业3/second_topic
2.实验心得
这个实验让我懂得了 Scrapy 框架的核心用法,我对于各个文件的作用理解的更加深刻与清晰
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
1.实验过程与代码
定位外汇数据所在的html标签,区分表头以及数据
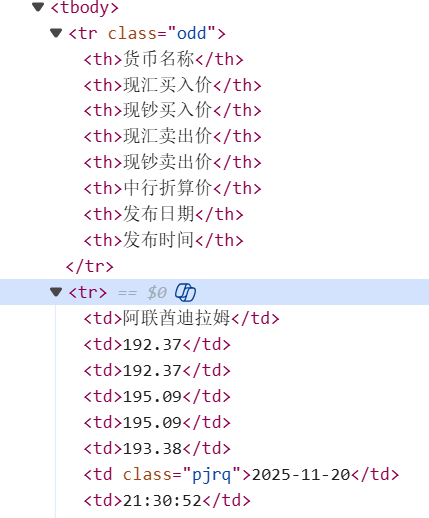
根据该索引,写出xpath
货币名称:./td[1]/text()
现汇买入价:./td[2]/text();
现钞买入价:./td[3]/text();
现汇卖出价:./td[4]/text();
现钞卖出价:./td[5]/text();
发布时间:./td[8]/text()。
思路同第二题。
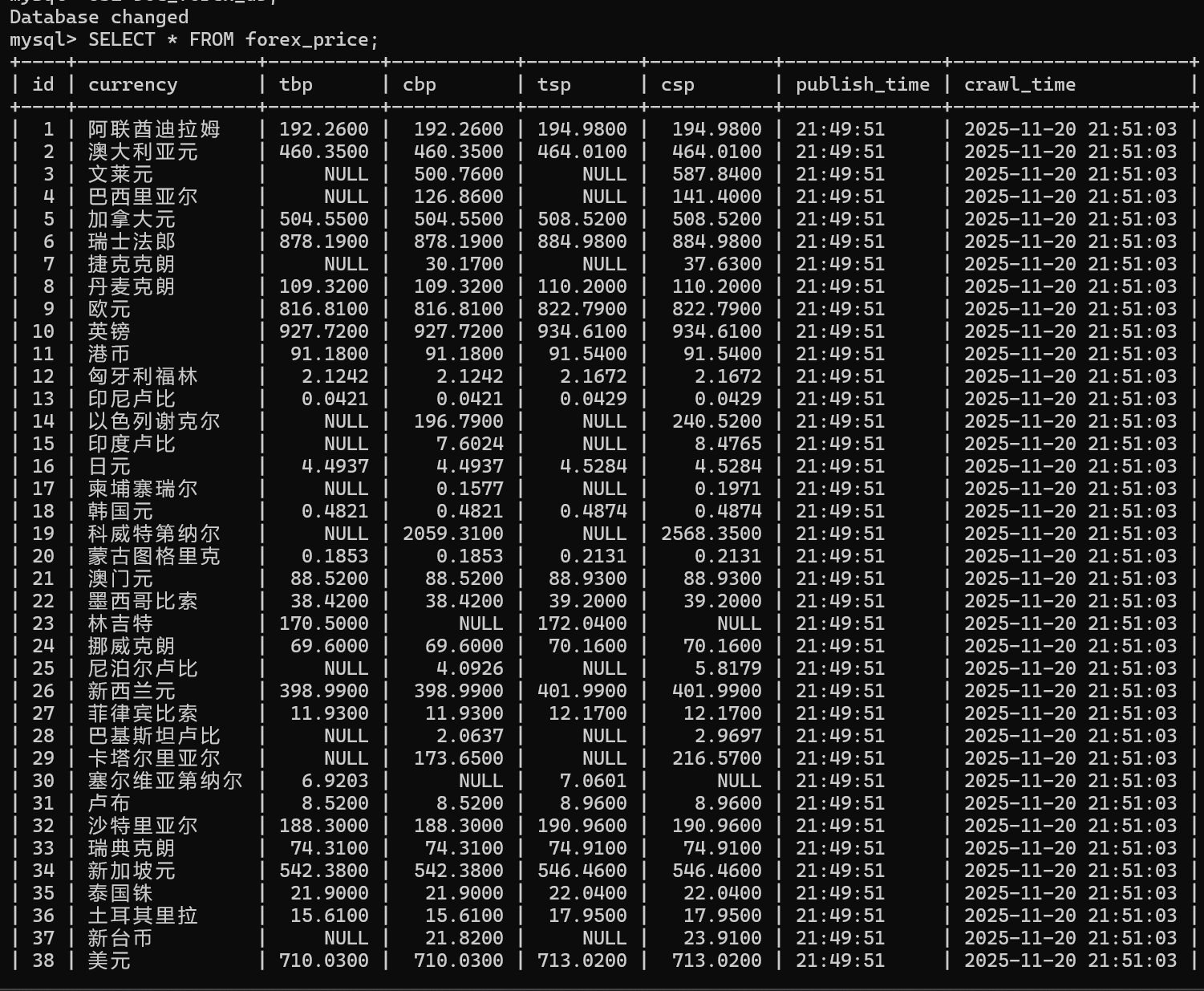
地址:https://gitee.com/augtrqv/shoren/tree/master/作业3/boc_forex_scrapy
2.心得
这两个实验都让我巩固了使用scrapy爬取数据以及用xpath分析存储数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号