
102302110高悦作业2
•作业①:要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
1.代码与过程
查看相应位置的代码

from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con=sqlite3.connect("weathers.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self,city,date,weather,temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)" ,(city,date,weather,temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows=self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city","date","weather","temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0],row[1],row[2],row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode={"福州":"10123010103A","厦门":"10123020102A","广州":"101280101","深圳":"101280601"}
def forecastCity(self,city):
if city not in self.cityCode.keys():
print(city+" code cannot be found")
return
url="http://www.weather.com.cn/weather/"+self.cityCode[city]+".shtml"
try:
req=urllib.request.Request(url,headers=self.headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
lis=soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date=li.select('h1')[0].text
weather=li.select('p[class="wea"]')[0].text
temp=li.select('p[class="tem"] span')[0].text+"/"+li.select('p[class="tem"] i')[0].text
print(city,date,weather,temp)
self.db.insert(city,date,weather,temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self,cities):
self.db=WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
#self.db.show()
self.db.closeDB()
ws=WeatherForecast()
ws.process(["福州","厦门","广州","深圳"])
print("completed")

2.心得体会:用 BeautifulSoup 的 select 方法抓ul[class='t clearfix'] li这类标签,直接提取日期、天气、温度,比正则扒数据直观。
• 作业②:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
1.代码与过程
首先打开东方财富网,使用f12来看看股票数据

还是和之前的操作一样,首先保存该网页的json下来分析,避免多次访问被网站拉黑
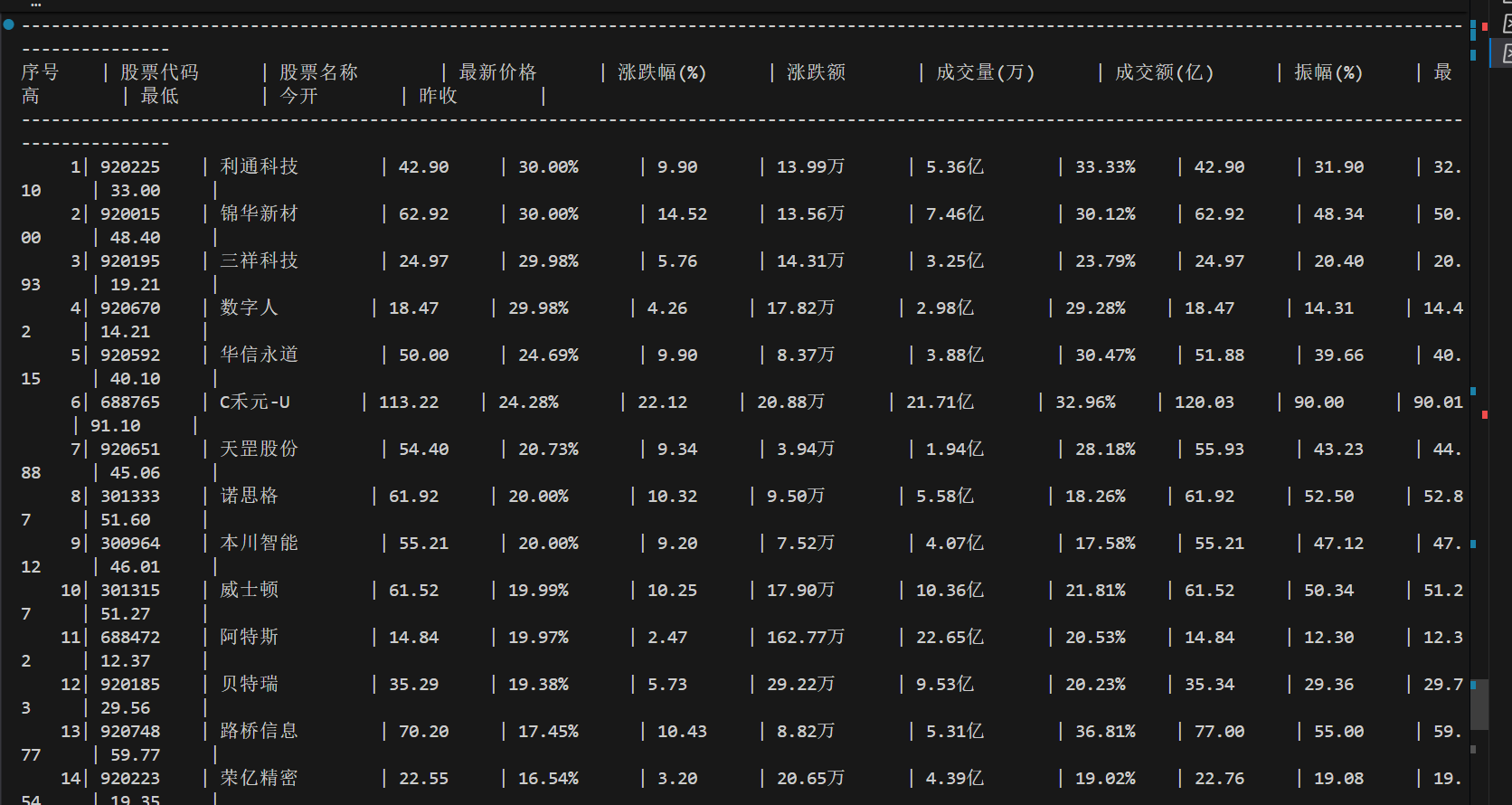
首先逐页爬取各个页面,保存股票信息
然后将爬取的股票数据进行处理和单位转换
最后将数据写入数据库
2.心得与体会:直接调用网页的api接口,可以直观快速地分析数据接口,提高了数据解析的效率。这让我明白,爬取前先分析目标网站的数据源(是 HTML、API 还是 JS 加载),能少走很多弯路。
• 作业③: 爬取中国大学2021主榜
1.代码与过程
在f12中分析数据的api,里面是json格式

可以看到其中的api是有形参和实参的,找到json的头尾,即将形参和实参一一对应,获得对应表
province_map = {
"q": "北京", "D": "上海", "k": "江苏", "y": "安徽", "w": "湖南",
"s": "陕西", "F": "福建", "u": "广东", "n": "山东", "v": "湖北",
"x": "浙江", "r": "辽宁", "M": "重庆", "K": "甘肃", "C": "吉林",
"I": "广西", "N": "天津", "B": "黑龙江", "z": "江西", "H": "云南",
"t": "四川", "o": "河南", "J": "贵州", "L": "新疆", "G": "海南",
"aA": "青海", "aB": "宁夏", "aC": "西藏"
}
category_map = {
"f": "综合", "e": "理工", "h": "师范", "m": "农业", "S": "林业",
"i": "医药", "a": "财经", "j": "政法", "g": "民族", "d": "语言",
"b": "艺术", "c": "体育"
}
解析数据,提取关键信息
def extract_universities(js_content):
if not js_content:
return []
# 正则匹配目标字段(学校名称、类型、省份、分数)
pattern = re.compile(
r'univNameCn:"([^"]+)"'
r'.*?' # 非贪婪匹配,跳过中间无关内容
r'univCategory:(\w+)'
r'.*?'
r'province:(\w+)'
r'.*?'
r'score:([\d.]+)'
, re.DOTALL # 支持跨多行匹配
)
matches = pattern.findall(js_content)
universities = []
# 用索引作为排名(从1开始)
for i, (name_cn, category_var, prov_var, score) in enumerate(matches, start=1):
universities.append({
"rank": i,
"school_name": name_cn,
"province": province_map.get(prov_var, prov_var),
"category": category_map.get(category_var, category_var),
"total_score": float(score)
})
return universities
最后将数据导入数据库
数据库输出结果

2.心得体会
在处理json的过程中,本来想将jsonp格式处理成json,就可以直接使用json.load()直接来进行解析,但是一直尝试,发现前面开头特别之长,解析的效果不好,因此又选择了正则表达式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号