转自:Reverse Engineering 101 — Part 1 (cymetrics.io)
稍作了些修改,因为弯弯的一些计算机术语和我们的不太一样
然后有一些执行结果图片用的是自己的
Reverse Engineering 101 — Part 1
最近解一些CTF顺便跟同事分享Reversing的一点基础技巧,想说写成文章分享一下。 这篇是给技术小白的 Reversing 入门系列,零基础第一课!
本篇会用到的工具有:
- linux 或 Unix-like 操作系统
- GDB(GNU Debugger),一个不管静态还是动态分析都很好用的 linux 内建工具
- 满满的好奇心!
该如何开始?
以下以一个简单的小程序为例。
今天拿到一个未知的档案,我们该从何下手呢? 首先,要知道我们的目标是什么样的档案。 我们可以用 linux 内置的file指令来识别文件类型。

例如从上图中我们可以观察到几件事:
-
这是一个 ELF 文件(Executable Linkable Format),是 Unix 系统上常见的 binary 执行文件、共享函式库、或是 object code 类型,也意味这我们可以直接在 linux 系统上把他跑起来
-
内存的字节顺序(Endianness)为 LSB(Least Significant Bit),或是常说的 little endian(低位存储),表示把最高位的字节放在最高的内存地址上,如下图所示。
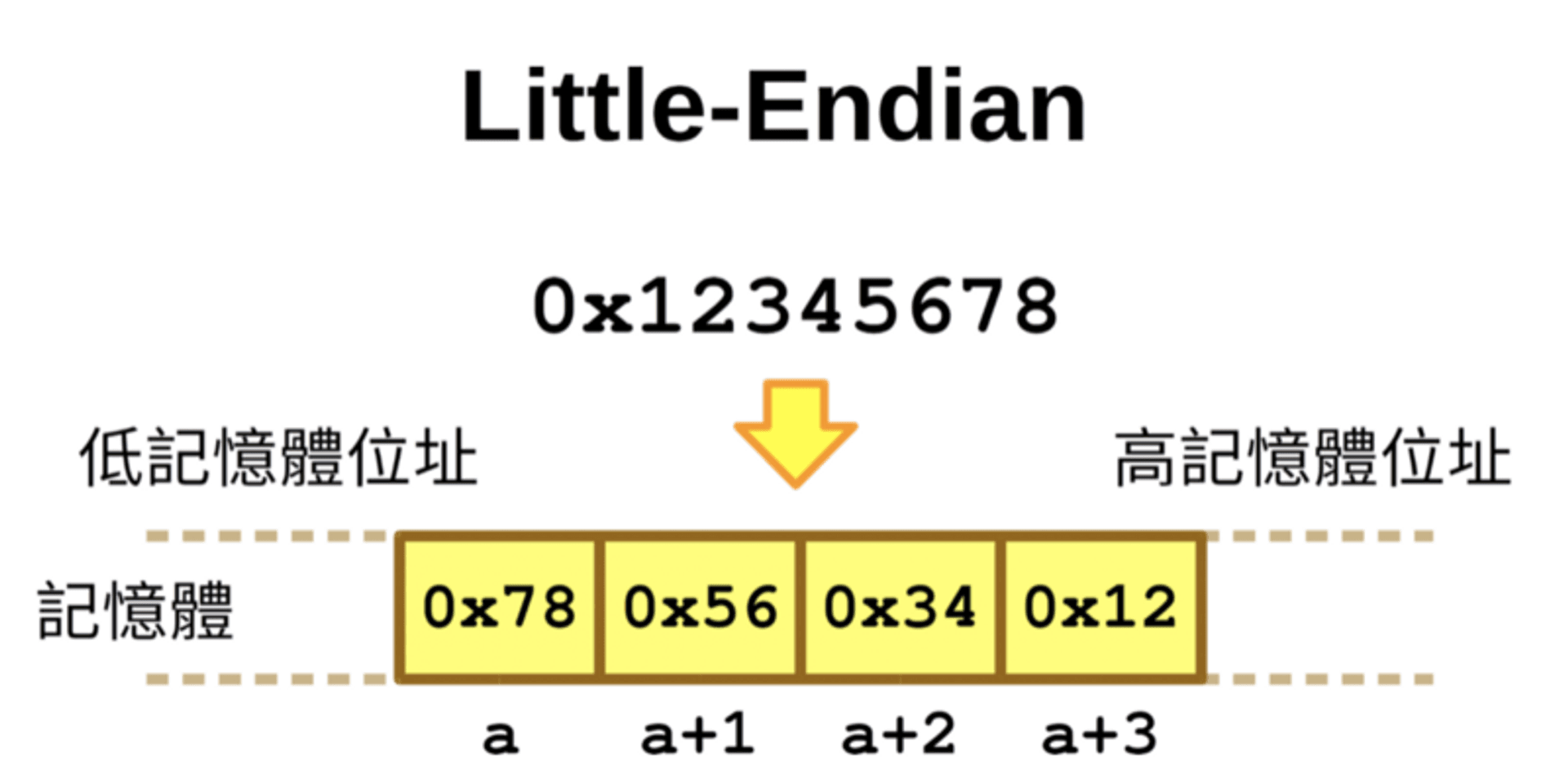
这表示当我们输入的时候1234,在 GDB 等软件里观察内存时会看到的是\x34\x33\x32\x31 ,这部分我们等等用 GDB 会再看到。
图片来自 这篇文章
-
libc 函数的调用为 dynamically linked(动态链接),亦即程序跑起来的时候,操作系统才会做 linking,把各个要调用的 libc 函数的位置填到这只程序的一张表里,方便执行时查询呼叫。 如果是 statically linked(静态链接),在编译过程中就会直接把这些外部函数都一起包到程序里面,产出一个比较肥大的档案。 就像有人制作笔记时,会把课本内容抄到笔记本上,这样所有资料一目了然,马上就能找到,缺点是笔记厚厚一本; 也有人仅是标注对应的课本页数,这样笔记较为精简轻便,不过缺点是要找资料时必须另外参照课本。
-
跑在 x86–64 (64 bits)的结构上,64 bits 跟 32 bits 不只在寄存器名称上不同,在 system call (系统调用)的呼叫上也不一樣。
-
not stripped,表示在编译过程中,debugging 信息沒有被去掉,我們还看得到各个函数跟变量的名称等等。
接着,就可以执行看看!跑起来如下图所示,会先跟使用者要三个数字,然后进行某些判断,错误就会像这样印出 nope.。因此,我们可以判断拿到 flag 的條件就是让这三個数字符合某些关系,检查通过了就会印出 flag。

GDB 是什麼?能吃嗎?
GDB 的全名是 GNU Debugger,顾名思义就是可以让你一边执行一个档案一边看到里面的细节,也可以设置中断点来逐步检视记忆体里面存的东西跟执行顺序,方便开发者抓BUG。 他还有很多强大的功能跟插件,例如最常用的 peda、gef、pwndbg 等等,可以让你很方便地看到不同区段的数据甚至产生 shellcode ,大家如果有兴趣可以再去逛逛。
①首先,执行就可以在 GDB 里面加载这个执行文件。
②再来就是用下面代码来观察这个程序的进入点跟各区段位置。
gdb <文件名称>
info file
编译器运作时,会把负责逻辑的代码跟变量等数据分区存放并加上对应的标签以供程序运行时存取。

ps:图片中线索pwndbg是因为装了插件,没有装插件显示的不一样但输入info file也会显示出各区段位置。
通常我们会注意的几个比较重要的区段为:
①放置可执行的代码。 权限为只读。.text
②已初始化的数据,例如你在程序里面写死的字符串或是常数。 权限为只读。.rodata
③已初始化的数据,例如你在程序里面使用的全局变量。 权限为可读可写。.data
④未初始化的数据。 权限为可读可写。.bss
我们知道开始执行的地方是后,就可以用disass 0x400860反编译这段代码。
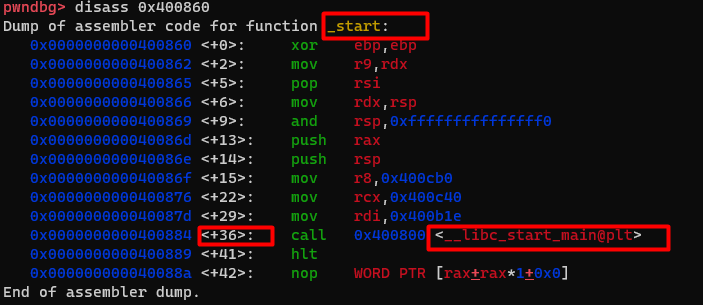
您可以观察到此函数有一个名字 。 之前说过,not stripped表示函数名称都有被保留,所以我们也可以用函数名称_start当作reference对象,在反编译跟设断点的时候使用这个名称。
但是我们的程序里面没有写到_start这个函数啊,他是哪里来的呢?
其实在编译的过程中,编译器会加入一个进入点函数,负责初始化一些 gcc/glibc 的准备工作后再调用main函数 ,可以想成是在我们的程序外多加一层包装来整顿好环境再开始执行主逻辑。 所以,我们可以看到在_startmain<+36>的地方调用<__libc_start_main@plt>,其实也就是通过libc的函数再间接调用我们所撰写的主程序main 。
这里我们打个岔,回去看一下前面提到的little endian(低位存储)。
下面这张图是在GDB里面用去看内存的指令x/<num><unit> addr,
①unit有 b(bytes = 1 byte)、h(halfword = 2 bytes)、w(word = 4 bytes)、g(giant word = 8 bytes)这几种,表示一次看的单位是多少位
②前面的 num 就是看多少单位,所以addr x/4x 0x400cd0就是从地址0x400cd0开始读取 4 个 4 byte 的内存。
③unit 默认是 w,x 就是延续用最后一次设的单位。

我们看到第一行的第一块内存0x65746e45是红色框起来的 ,第二块内存0x68742072是黄色框起来的 ,那第三行一次读 8 bytes 的时候怎么顺序交换变成黄色框在前面了呢?
那就是因为little endian(低位存储)必须反过来读,我们看到的\x65\x74\x6e\x45在内存里面存的其实是\x45\x6e\x74\x65 ,所以把第一行的框框们从屁股读回来,黏一起就是\x45\x6e\x74\x65 \x72\x20\x74\x68,就是第三行的第一个单位反过来的样子啦! 大家记得不要读反罗!
基础知识:汇编语言与计算机结构
接下来,在进到main之前,先来讲讲一点基本的组合语言与计算机结构。
汇编语言是介于机器看得懂的二进制操作码(opcode)与一般人看得懂的高阶程式语言中间的一种低阶语言,目的是让二进位的程序变得可以阅读与编辑。
由于每一种 CPU 使用的机器指令(machine instruction)都不同,所以对应的汇编语言也不一样,这里我们以 x86–64 为例介绍,遇到不懂或没看过的都可以去查指令集哦。
最常见的指令如下,S 指 source, D指 destination:
mov D, S:将某个值或是内存的位置写入某个暂存器。 把S里面的值写到D里面。push S:将S里面的值放到 stack (栈)上。pop D:把 stack (栈)顶的值放到D里面,从 stack (栈)移除。add D, S、sub D, S:将S跟D里面的值相加相减,结果D放在里面。call Label:调用带有 Label 标签的函数,这时程序会为这个函数创一个新的 stack frame(栈帧)。ret:终止当前函数的执行,返回到上一层的函数。
还有进行条件判断的cmp\test、跟各种跳跃的家族jmp,之后我们遇到再说明。
要注意的是,上面的写法是Intel语法,如果是AT&T语法就将S跟D反过来(如mov S,D)。
首先,我们必须先理解暂存器与内存。 CPU 只跑指令,而数据储存交给内存,当 CPU 需要用到数据时就会向内存请求。 我们可以把内存想象成一间很小的图书馆,门口有一个柜子放本周最热门的书籍,进门后一楼放各个老师指定的课本与参考资料,其他书籍都放在地下仓库内。 那么今天有学生想借书,他要是在门口一看就能找到想要的那本当然是最有效率的,不然他就得走进去,在层架间仔细翻找,也许要一个小时才能找到。 要是更惨都没有,还要劳烦管理员到仓库里搜寻,说不定要一两天功夫才行。 越多的数据量查询起来越没有效率,反之,越少的数据越能快速存取。
内存常见的结构如下图。 最上层是CPU寄存器(register),是存取最快速频繁也最小的内存。 再往下至缓存(cache)、RAM、 hard drive ,能存的数据越来越多、体积越来越大、存取速度也越来越慢。
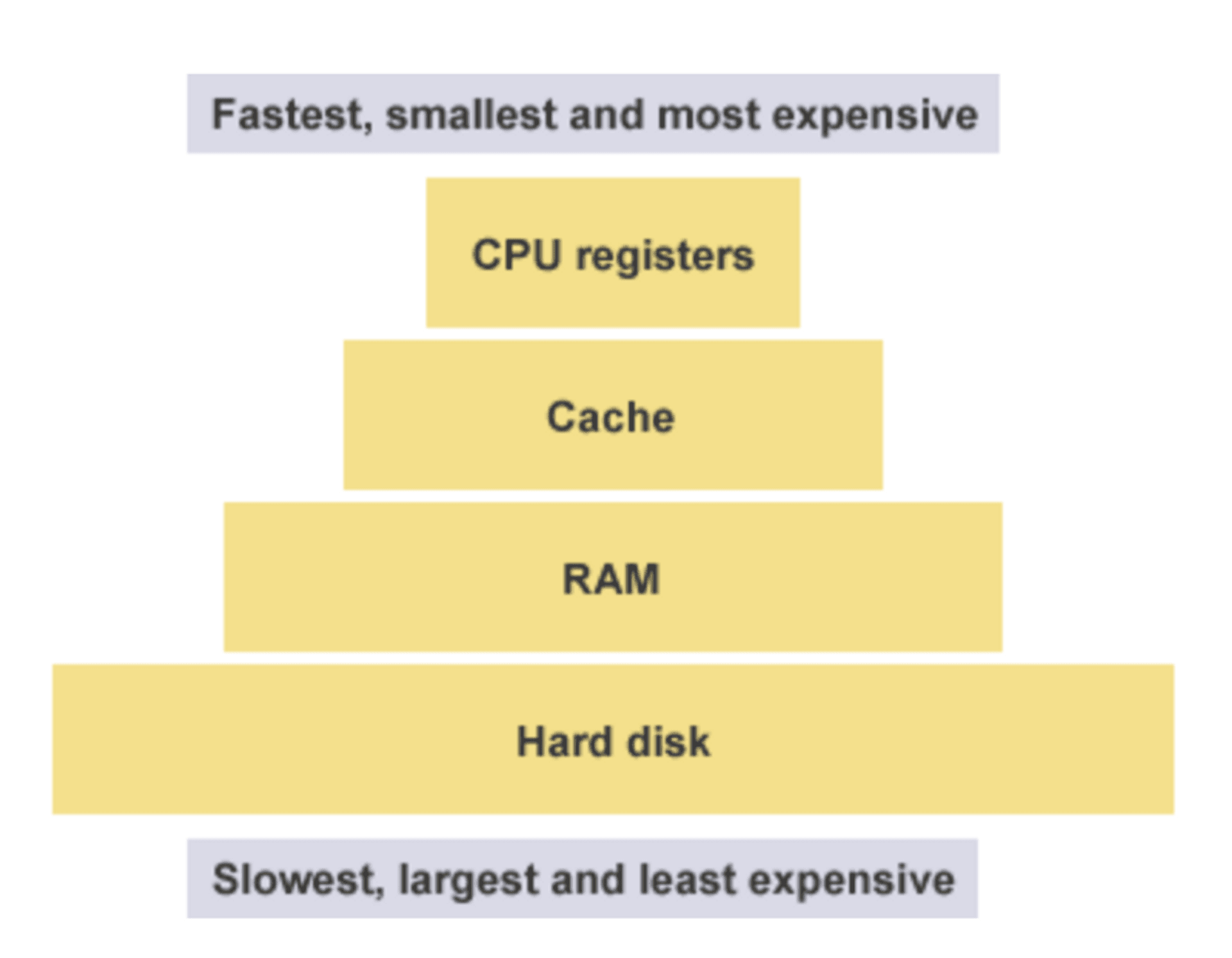
memory model,取自組合語言入門教程
要看懂组合语言,首要之务就是了解寄存器。
在x86–64结构下,寄存器都是64 bits= 8 bytes 大小,寄存器也可以部分存取,以rax为例, eax指rax的后 4 bytes、再对切得到ax为倒数 2 bytes、然后再切分为ah与al。
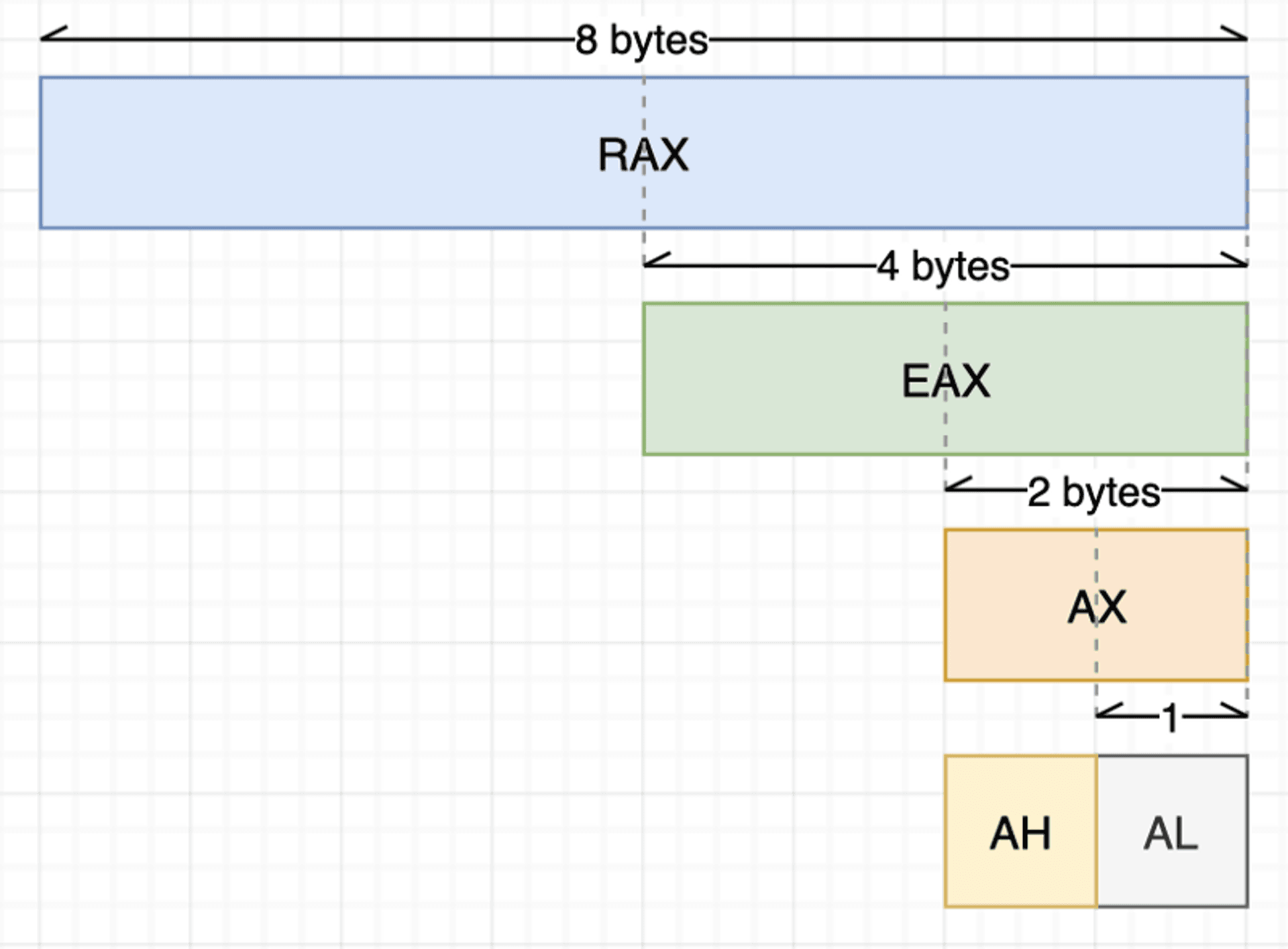
暂存器的种类也非常多,一般来说,有16个通用寄存器,为rax\rbx\rcx\rdx\rdi\rsi\rbp\rsp\r8-r15,意指可能被用于任何运算操作。 与之相对,属于专用寄存器的rip\rflags 就不是可以拿来运算调用的。
x64 registers,來自布朗大學講義
每个寄存器传统上都有特殊用途,例如:
rax常用于放函数回传值跟乘除法运算结果rbx常用于放 base addressrcx常用于循环中的计数器(counter)rdx常用于存放资料rbp (base pointer)指向当前函数 栈上的底部(栈帧下缘)rsp (stack pointer)指向当前函数栈上的顶部(栈帧上缘)rip (instruction pointer)指向下一个要执行的 CPU 指令
再来,我们看看栈跟堆。
C 程序一般的内存配置如下图。 上面是高的内存地址(0xffff…)下面是低的内存地址(0x0000…),
堆在.bss区段之后开始、随着动态内存配置增加慢慢往上长,而栈则是从高的内存地址开始往下长。
栈放置的是静态的、已知大小的数据,例如每一个函数内的区域变量以及函数的参数跟地址等等。
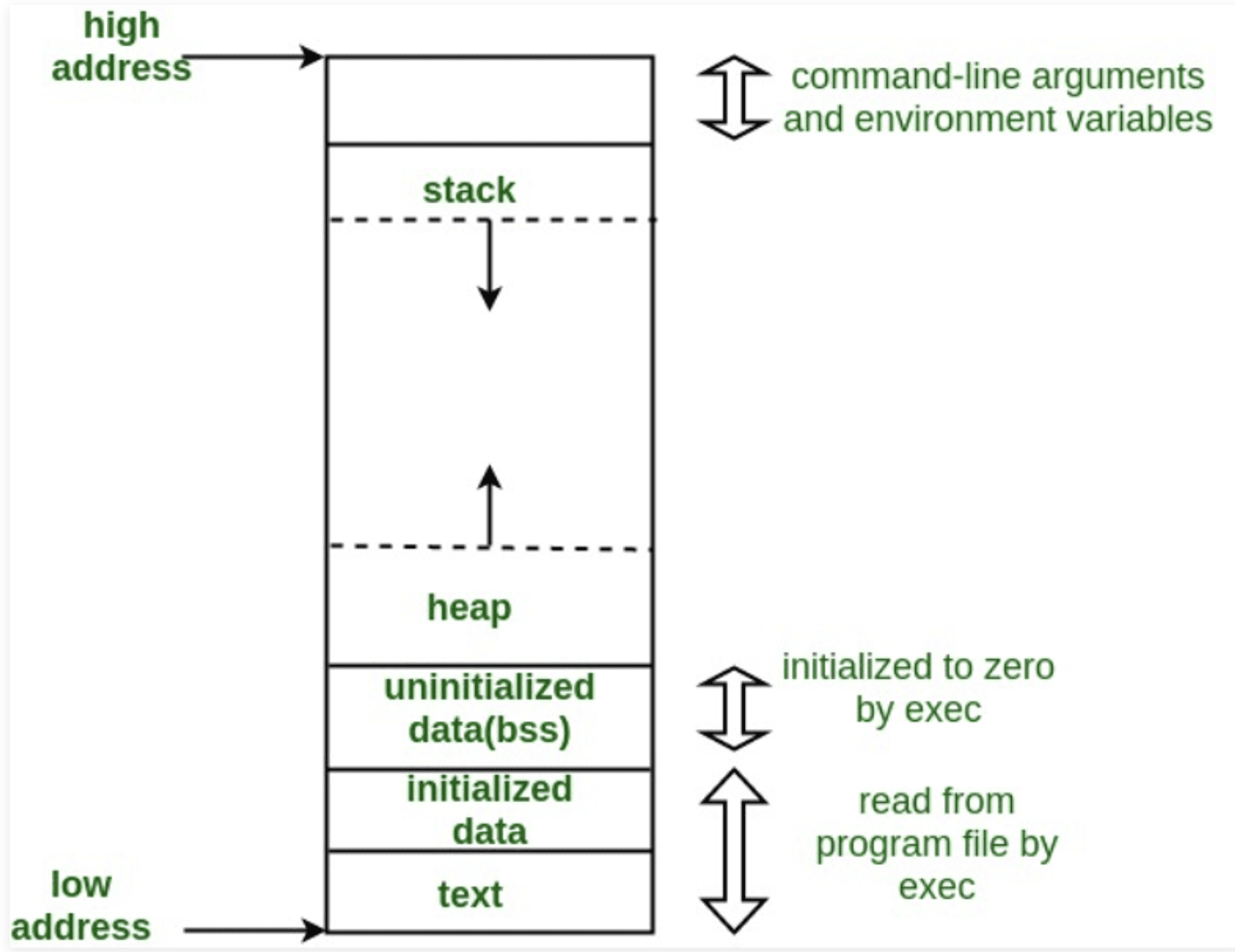 memory layout,取自 [geekforgeeks](https://www.geeksforgeeks.org/memory-layout-of-c-program/)
memory layout,取自 [geekforgeeks](https://www.geeksforgeeks.org/memory-layout-of-c-program/)
调用约定
程序执行时函数的调用就会以 stack frame(栈帧) 的方式层层堆叠,也可以想成内存是一个直立式的柜子、每个函数是一本一本的书籍,里面记载了这个函数内的各种变量,当一个函数被调用时,就把这本书平放到柜子中书堆的最上面,完成后再从书堆上拿下来。
那么,谁去管理这个柜子中的书堆,确保书籍有好好的被堆叠跟移除呢?
管理函数之间参数传递、并规定谁负责清除堆栈的一套约定,我们称为 calling convention(调用约定)。 在不同的系统架构下会有不同的调用约定,
以 AMD64 系统(用于 Solaris、Linux、FreeBSD、MacOS 等 Unix 跟 Unix-like 系统)的 x86–64 为例,
储存函数前六个参数的寄存器依序为rdi\rsi\rdx\rcx\r8\r9 ,而函数 return 的回传值则会放在rax中(若大于一个寄存器的空间,例如回传值在 64–128 bit,则会放在rax跟rdx )。
①在调用一个函数前,调用者(caller)会把被调用的函数(callee)的参数放到寄存器中
②再通过call这个指令去执行 callee。
③而进入 callee 后,在进行主逻辑前,callee 会先创造自己的栈帧,在栈上留一块内存空间。
④逻辑执行结束时,用leave把栈帧里的东西清掉
⑤最后ret把控制权交回 caller。
创造自己的栈帧
『创造自己的栈帧』这个动作又称为 function prologue(函数序言),可以模拟为书的前言、铺成。 实作上其实有一个组语指令叫enter n,0 ,不过因为他太慢了,所以通常用下面这段取代:
push ebp
mov ebp, esp # ebp = esp
sub esp, $n # allocate space on the stack
搭配下图由左而右来看,
蓝色区块是 caller 的栈帧,黄色是进行call后把当前执行到的地方,也就是等 callee 结束执行要返回的地方给存起来。
① 第一行的push把当前的ebp放到栈上面,等同存好现在的栈基底,方便函数结束后回复到前一个函数的状态,此时栈从左一变成左二,多了绿色的部分。
②第二行把ebp指到现在esp的位置,stack 从左二变成左三。
③第三行把esp向上移大小为 n 的空间,也就是预留出 callee 函数(被调用的函数)所需要的内存,stack 变成最后一张,创造出了红色部分的另一个栈帧。
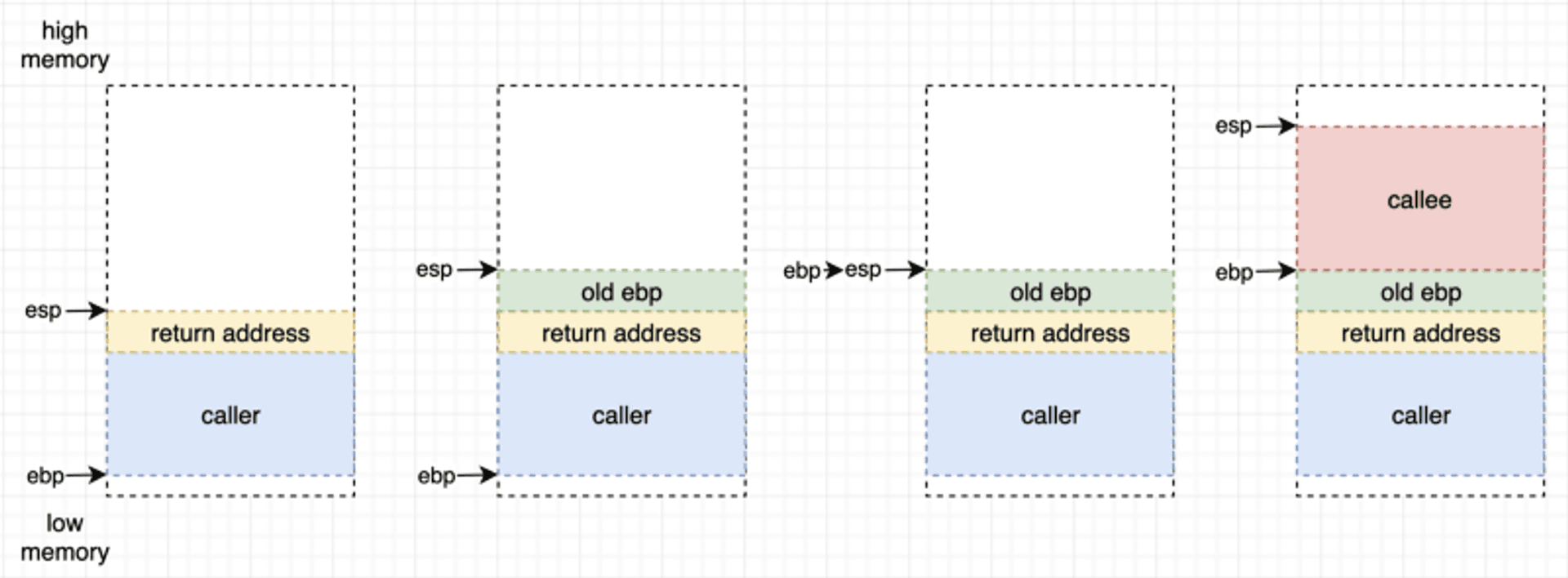 function prologue调用约定
function prologue调用约定
清掉自己的栈帧
『清掉自己的栈帧』这个动作又称为 function epilogue(函数尾声),可以模拟为书的后言。 使用的组语指令叫 leave,概念上等同下面这段:
mov esp, ebp # esp = ebp
pop ebp # restore old ebp
搭配下图由左而右来看,原始状态就是前面 function prologue 完的样子。
①第一行把esp指回ebp的地方,栈从左一变成左二,这下子红色的 callee(被调用函数) 栈帧就被释放出来了。
②第二行把栈上的值拿下来放回ebp,也就是把旧的ebp位置还原回来,栈变成最右边的样子,当前的内存最上面就回到 caller 的 栈帧 了。
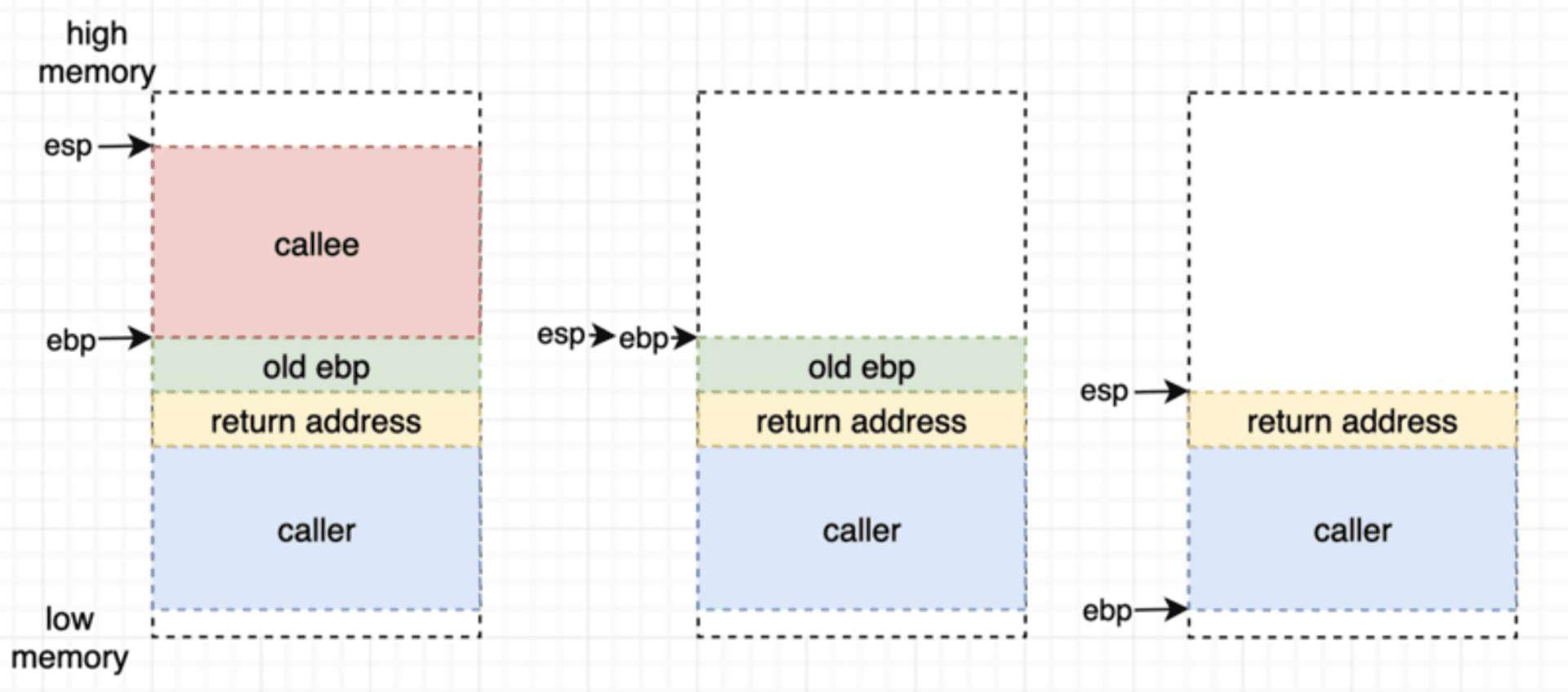 function epilogue
function epilogue
结语
到这里为止,我们其实都还没开始逆向呢。 先具备一些基础知识是很重要的,知己知彼才能见招拆招嘛!
这一篇我们先讲解了逆向的起手式、基本的组合语言以及计算机结构、还有编译完的代码以及内存的运作方式。 上面只是针对AMD 的 x86–64 这一种结构做说明,有兴趣的话可以去查查不同结构下的组合语言指令集跟 calling convention,可是很不同的喔! 你也可以把这篇用到的小程序跟你电脑上别的程序用 GDB 或是 IDA 打开来看看,比较一下差异。
总之,我们总算把前置准备完成,下一集我们来正式开始看main!
-
小提醒:千万别执行来路不明的档案哦! 一般来说提供软件的厂商都会在下载点提供一个 MD5 checksum,也就是将这个档案的数据做杂凑运算得出的一个值,你可以利用 linux 内建的
md5sum指令验明正身! 如果md5sum <file>的到的结果跟网站标示的一样才是对的! -
在 dynamically linked 的時候,如果想看到有哪些外部函示庫被調用,以及他們的 base address,可以用
ldd <filename>查看,這部分的利用以後有 pwn 入門系列再來說明 -
或者我們也可以用
objdump來看各區段的位置以及權限,指令為objdump -h <filename>,同一個檔案的輸出會長這樣
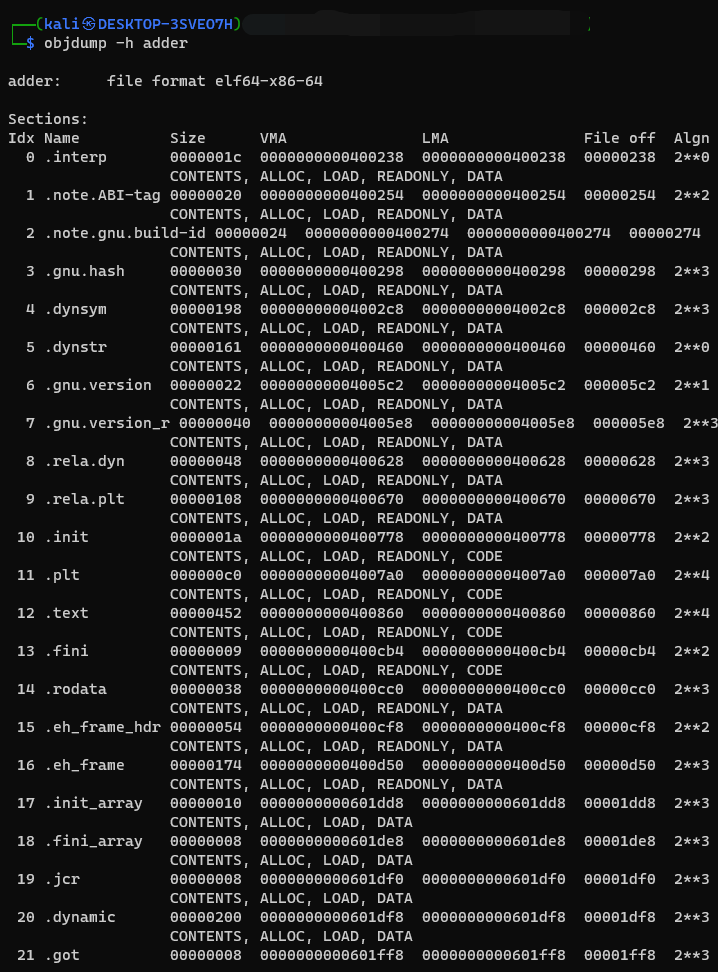
-
另外其實有 128 bit 的暫存器,例如用來傳遞浮點數的參數時使用的是
XMM系列,calling convention 跟一般用途暫存器類似,XMM0-XMM7用於傳遞參數,回傳值則會放在XMM0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号