基于CDH环境下的Hive数仓配置及优化
基于CDH环境下的Hive数仓配置及优化
原文连接地址:https://blog.csdn.net/sinat_31854967/article/details/127274575
YARN的基础配置
NodeManager CPU配置
-
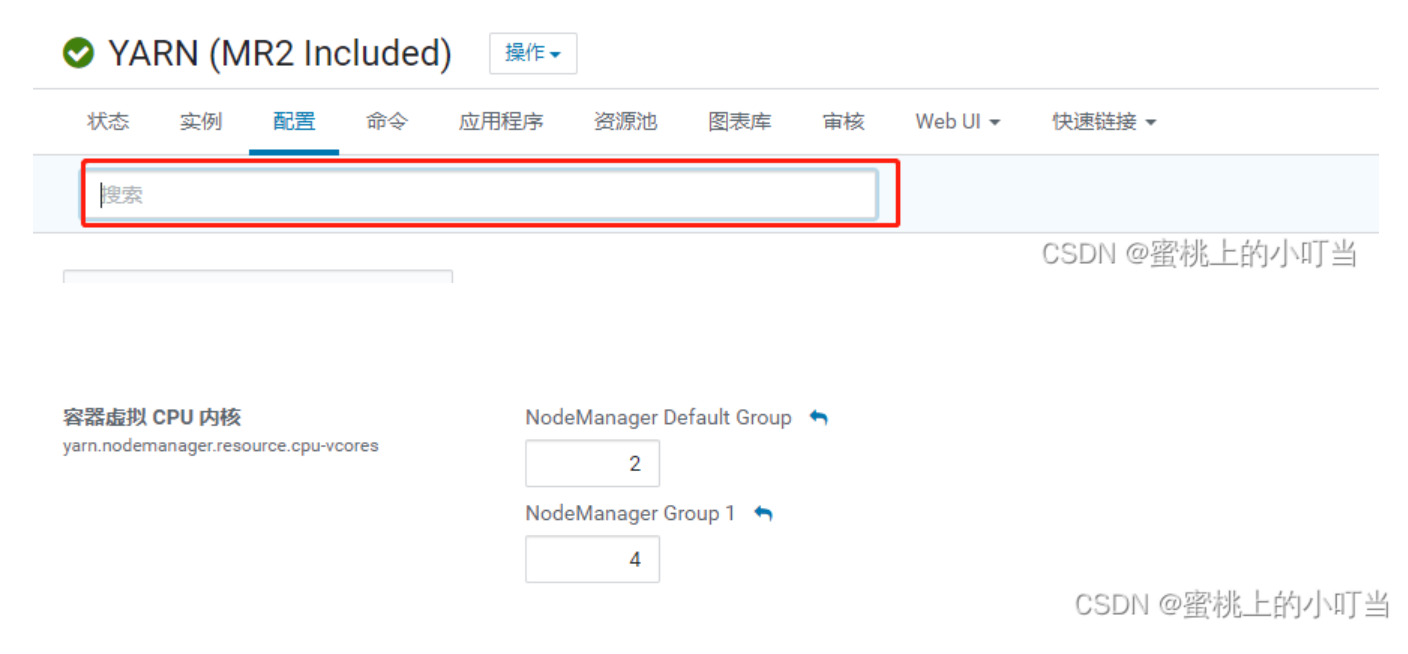
在YARN界面中,点击配置,然后搜索配置项:yarn.nodemanager.resource.cpu-vcores
![]()
-
此选项表示该节点服务器上yarn可以使用的虚拟CPU个数,默认值是8,推荐将值配置与物理CPU线程数相同,如果节点CPU核心不足8个,要调小这个值,yarn不会智能的去检测物理核心数(实际生产环境要比这个大很多,测试环境核数比较小)。
-
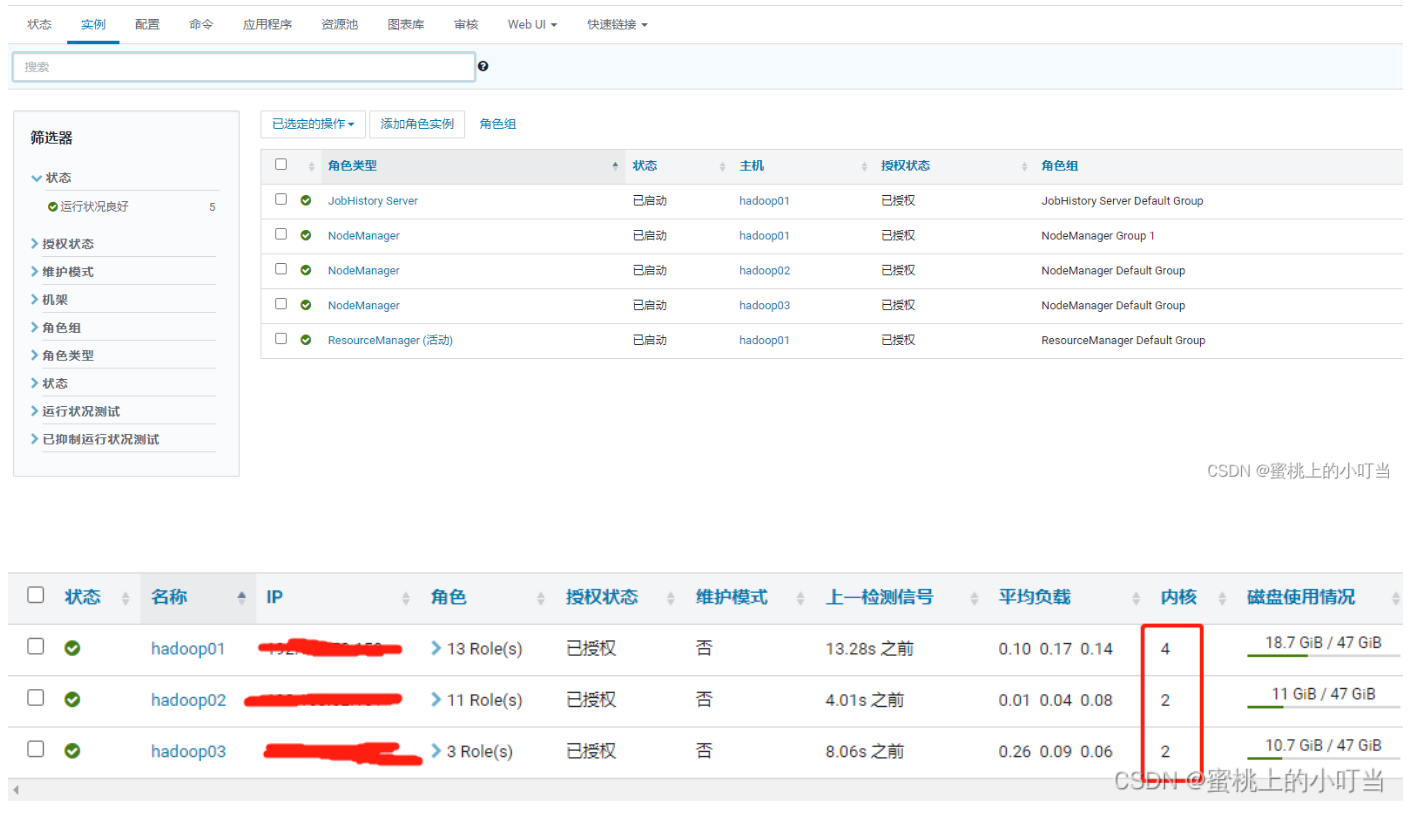
在CDH主机的界面中我们可以看到每台虚机的核数,如下图所示:
-
!
![]()
-
同样我们也可以在使用命令linux上面查看每台虚机的CPU核数:
grep 'processor' /proc/cpuinfo | sort -u | wc -l

NodeManager 内存配置
-
在YARN界面中,点击配置,然后搜索配置项:yarn.nodemanager.resource.memory-mb
-
![]()
-
设置该NodeManager节点上可以为容器分配的总内存,默认为8G,如果节点内存资源不足8G,要减少这个值,yarn不会智能的去检测内存资源,一般按照服务器剩余可用内存资源进行配置。生产上根据经验一般要预留15-20%的内存,那么可用内存就是实际内存*0.8。
-
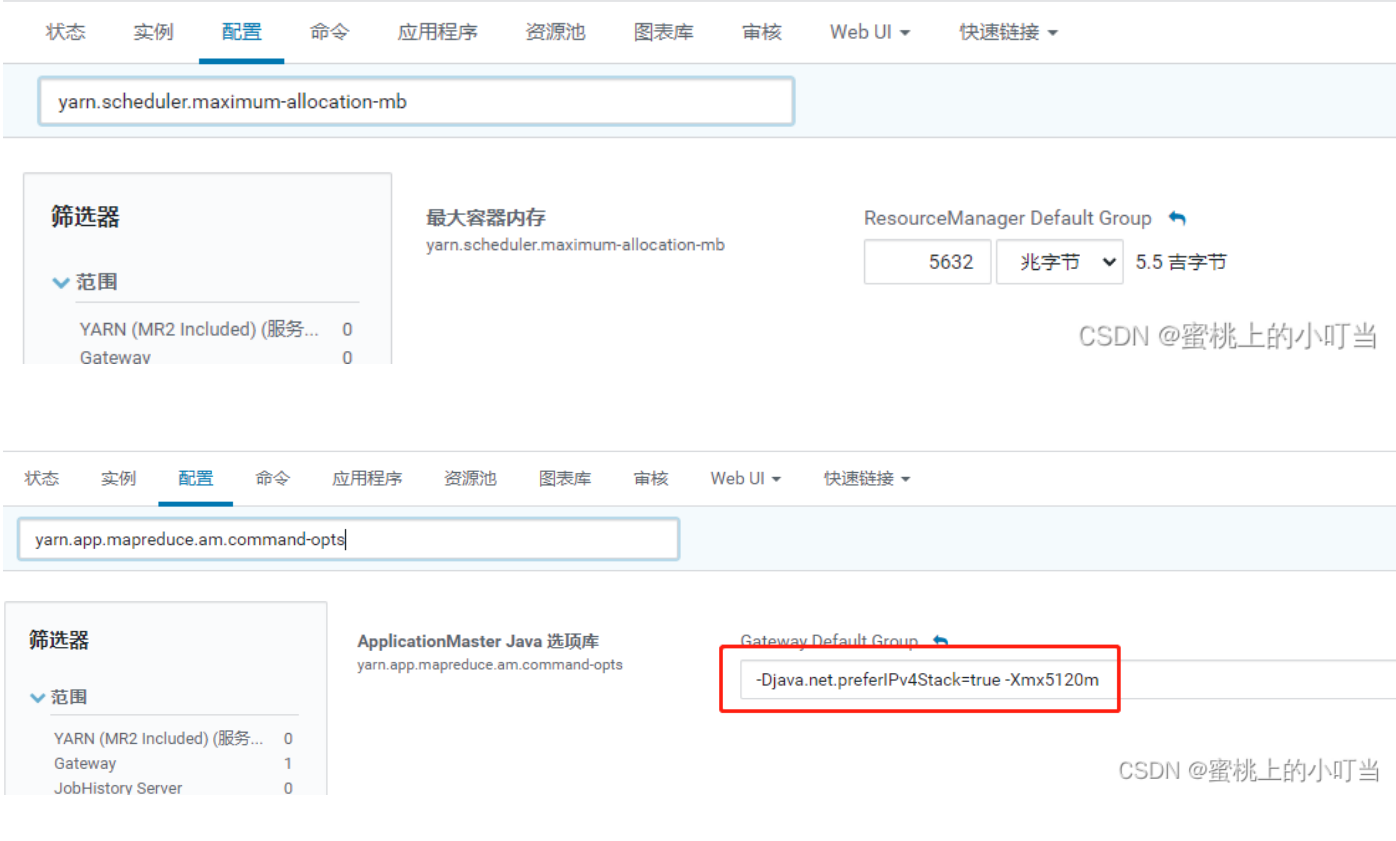
Tips:注意要同时设置yarn.scheduler.maximum-allocation-mb为一样的值,yarn.app.mapreduce.am.command-opts(JVM内存)的值要同步修改为略小的值。
![]()
-
在CDH主机的界面中我们可以看到每台虚机的内存,如下图所示:
![]()
-
同样我们也可以在使用命令linux上面查看每台虚机的内存:


free -mh

MapReduce内存配置
-
当MR内存溢出时,可以根据服务器配置进行调整
-
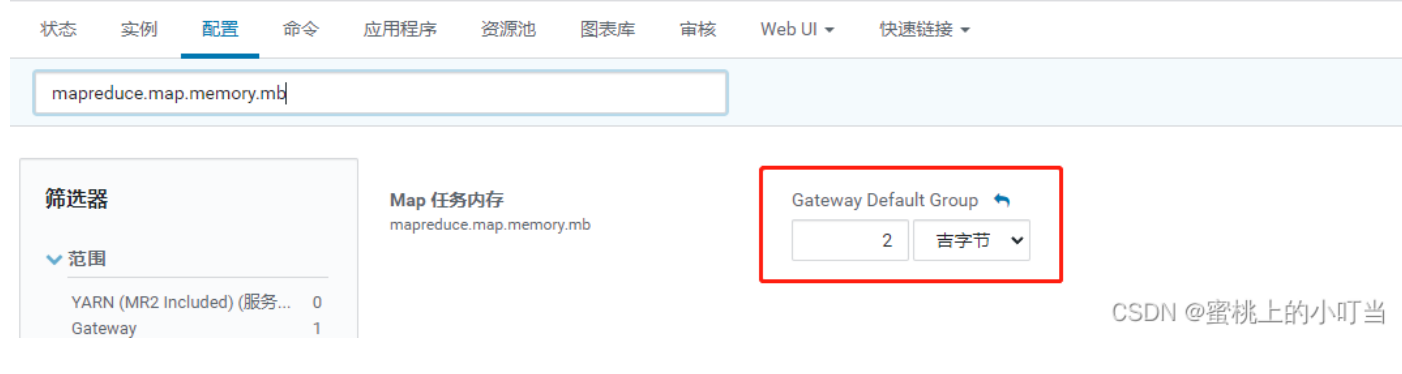
为作业的每个 Map 任务分配的物理内存量(MiB),默认为0,自动判断大小配置项为:mapreduce.map.memory.mb。
-
![]()
-
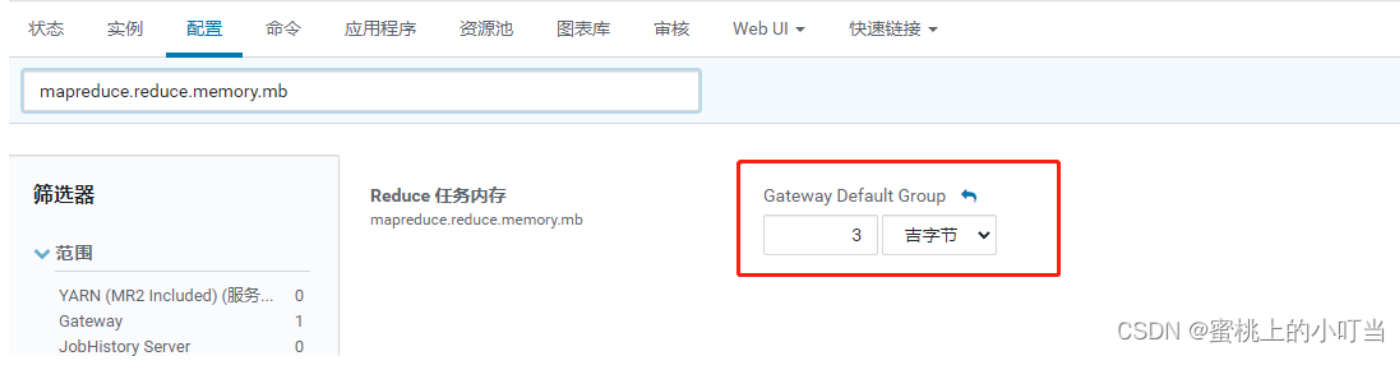
为作业的每个 Reduce 任务分配的物理内存量(MiB),默认为0,自动判断大小配置项为:mapreduce.reduce.memory.mb。。
-
![]()
-
Map和Reduce的JVM配置选项,配置项为:mapreduce.map.java.opts、mapreduce.reduce.java.opts。
-
![]()
-
Tips:
mapreduce.map.java.opts一定要小于mapreduce.map.memory.mb(大约为0.9倍)。
mapreduce.reduce.java.opts一定要小于mapreduce.reduce.memory.mb(大约为0.9倍)。

Hive配置及优化
HiveServer2的Java堆栈
-
如果Hiveserver2异常退出,导致连接失败的问题,如下图
-
![]()
-
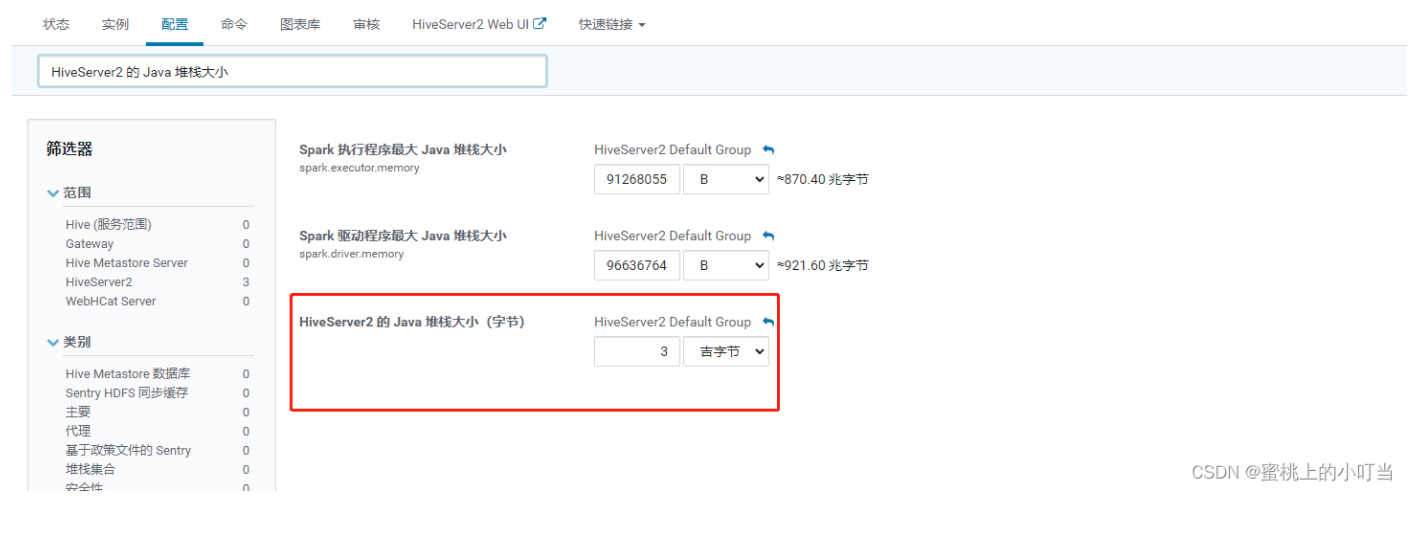
此类报错通常情况下是OOM的情况,需要修改HiveServer2的Java堆栈。在Hive界面中,点击配置,然后搜索配置项:HiveServer2 的 Java 堆栈大小
-
![]()
-
设置完成之后重启Hive服务即可。

Hive动态生成分区的线程数
- 在Hive界面中,点击配置,然后搜索配置项:hive.load.dynamic.partitions.thread。
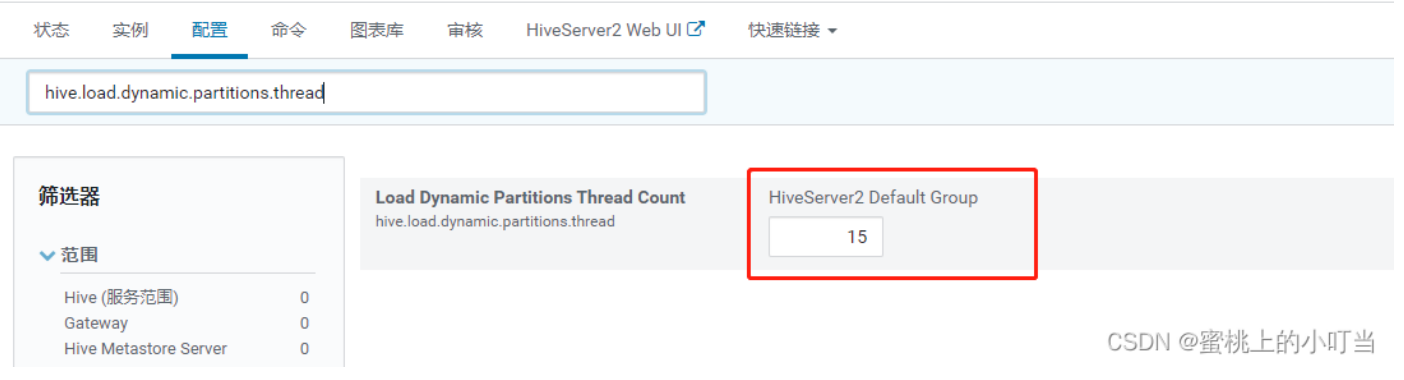
- 此配置项用于加载动态生成的分区的线程数。加载需要将文件重命名为它的最终位置,并更新关于新分区的一些元数据。默认值为 15 。
- 当有大量动态生成的分区时,增加这个值可以提高性能。根据服务器配置修改。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号