flink-format_小练习
2、format
1、json
json格式表结构按照字段名和类型进行映射
- 增加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>1.15.0</version>
</dependency>
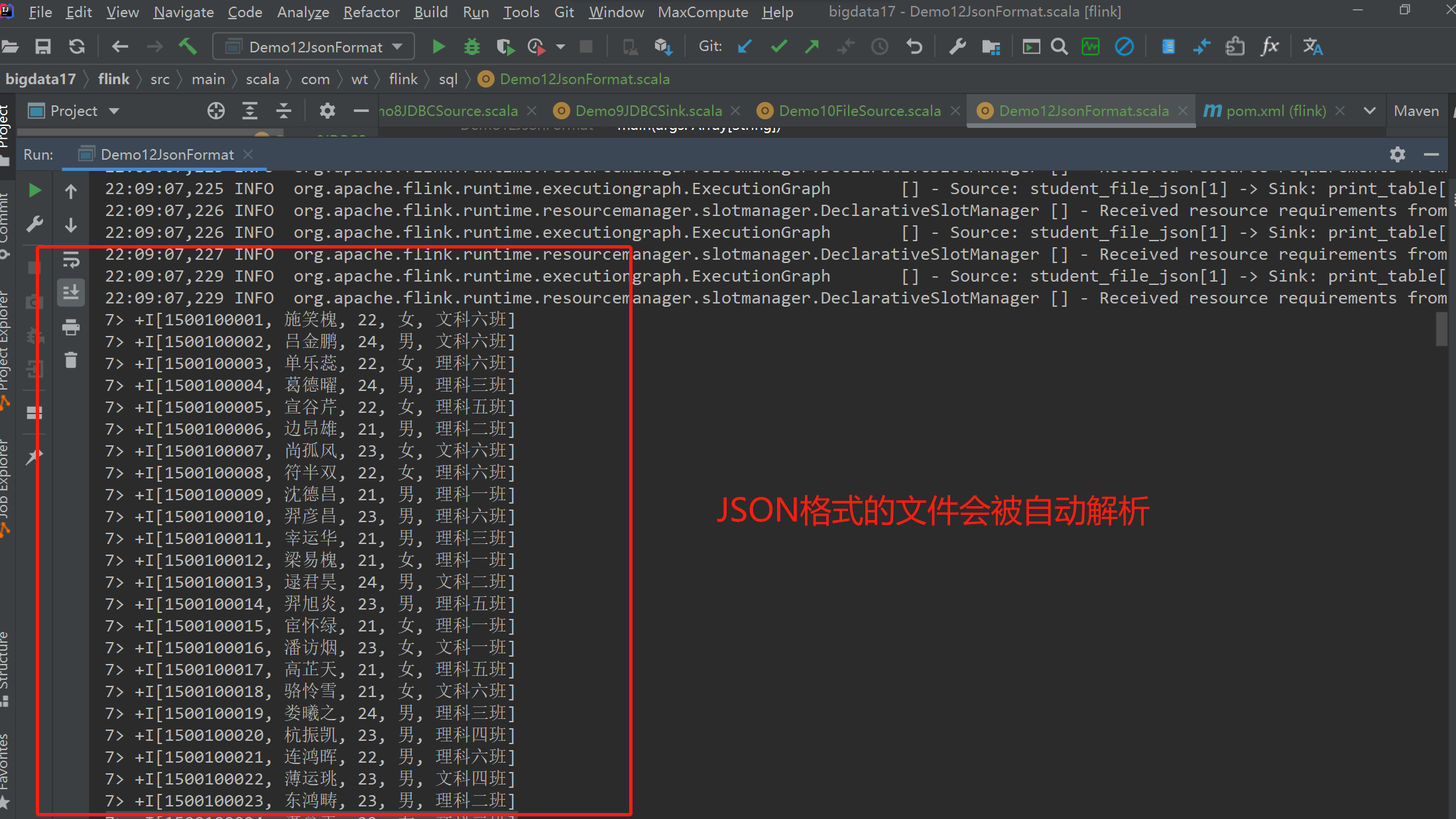
- 读取json格式的数据
-- source 表
CREATE TABLE student_file_json (
id STRINg,
name STRING,
age INT,
gender STRING,
clazz STRING
) WITH (
'connector' = 'filesystem', -- 必选:指定连接器类型
'path' = 'data/students.json', -- 必选:指定路径
'format' = 'json' , -- 必选:文件系统连接器指定 format
'json.ignore-parse-errors' = 'true'
)
-- sink 表
CREATE TABLE print_table
WITH ('connector' = 'print')
LIKE student_file_json (EXCLUDING ALL)
--执行sql
insert into print_table
select * from student_file_json
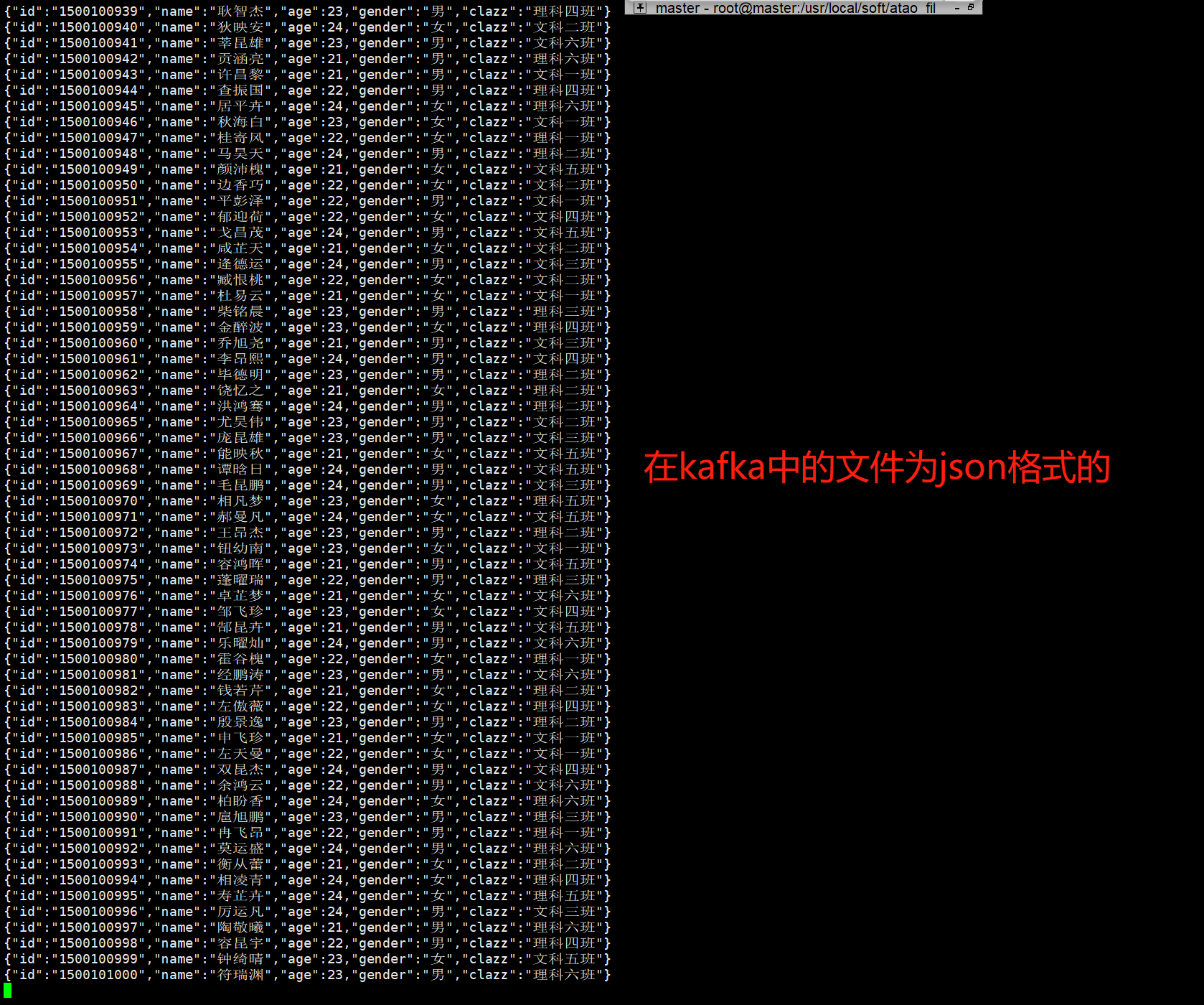
- 将数据保存为json格式
-- source 表
CREATE TABLE student_file_json (
id STRINg,
name STRING,
age INT,
gender STRING,
clazz STRING
) WITH (
'connector' = 'filesystem', -- 必选:指定连接器类型
'path' = 'data/students.json', -- 必选:指定路径
'format' = 'json' , -- 必选:文件系统连接器指定 format
'json.ignore-parse-errors' = 'true'
)
-- kafka sink
CREATE TABLE student_kafka_sink (
id STRING,
name STRING,
age INT,
gender STRING,
clazz STRING
) WITH (
'connector' = 'kafka',-- 只支持追加的流
'topic' = 'student_flink_json',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'format' = 'json'
)
-- 执行sql
insert into student_kafka_sink
select * from student_file_json
2、canal-json
使用canal采集mysqlbinlog日志,将采集到的数据以canal-json格式保存到kafka中
- 启动canal
# 进入canal按照目录
cd /usr/local/soft/canal/bin
# 启动canal
./restart.sh
-
在flink中创建表
flink会自动将canaljson格式的数据自动解析成一个变更的日志流
CREATE TABLE student_canal ( id BIGINT, name STRING, age BIGINT, gender STRING, clazz STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'bigdata.students', 'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', 'properties.group.id' = 'asdasd', 'format' = 'canal-json' , -- 使用 canal-json 格式 'scan.startup.mode' = 'earliest-offset' ); SET 'sql-client.execution.result-mode' = 'changelog'; select * from student_canal
3、练习
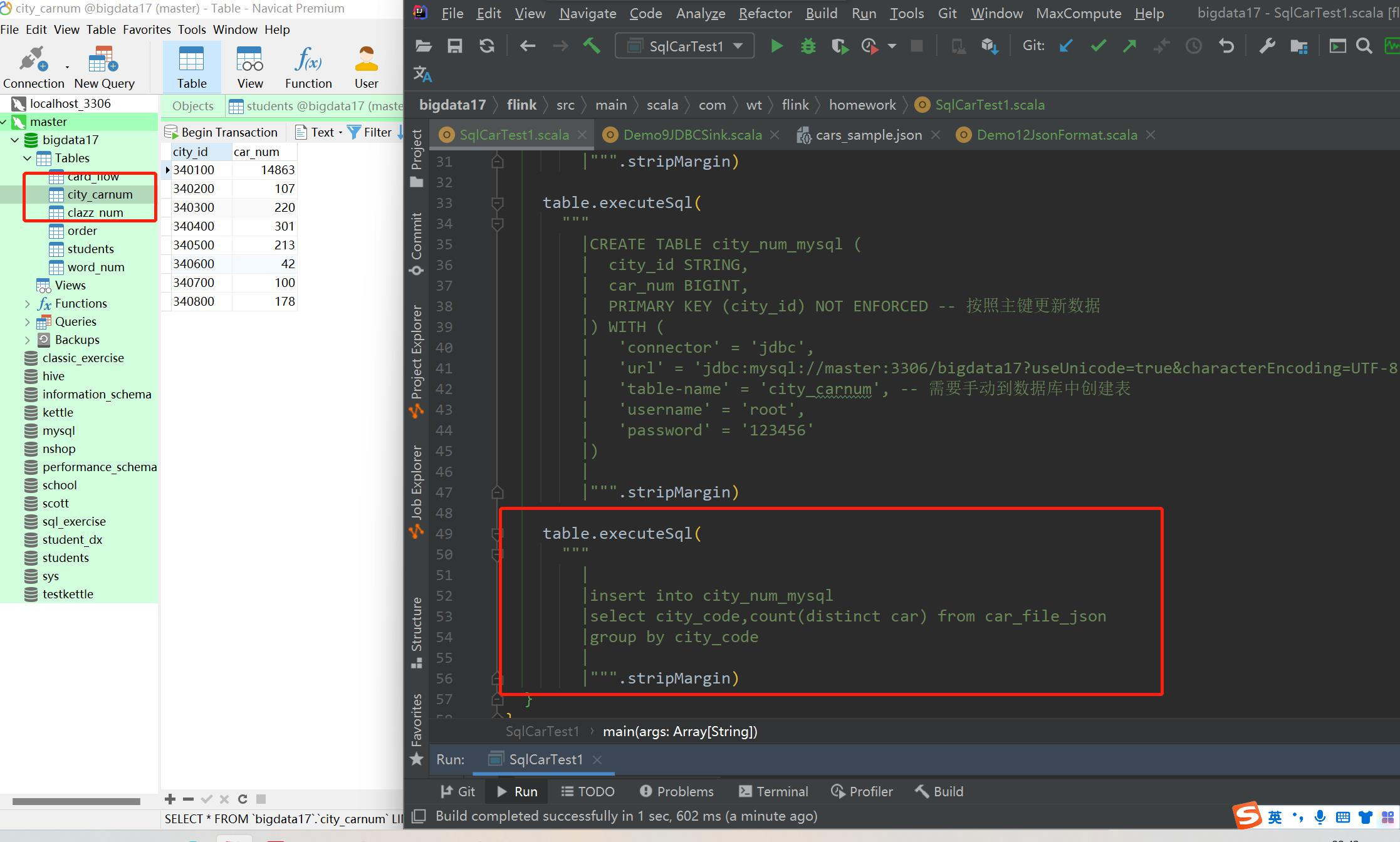
-- 1、使用flink sql 统计每个城市总的车流量
-- 2、source 使用文件source cars_sample.json
-- 3、将统计好的结果保存到mysql中,mysql中只保留最新的结果
- 代码
{"car":"皖A9A7N2",
"city_code":"340500",
"county_code":"340522",
"card":117988031603010,
"camera_id":"00001",
"orientation":"西南",
"road_id":34052055,
"time":1614711895,
"speed":36.38}
-- 1、创建卡口过车source表
CREATE TABLE cars (
car STRING,
city_code STRING,
county_code STRING,
card BIGINT,
camera_id STRING,
orientation STRING,
road_id BIGINT,
`time` STRING,
speed DOUBLE
) WITH (
'connector' = 'filesystem', -- 必选:指定连接器类型
'path' = 'data/cars_sample.json', -- 必选:指定路径
'format' = 'json' -- 必选:文件系统连接器指定 format
)
-- 2、创建 mysql sink表
CREATE TABLE city_flow (
city_code STRING,
flow BIGINT,
PRIMARY KEY (city_code) NOT ENFORCED -- 按照主键更新数据
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/bigdata?useUnicode=true&characterEncoding=UTF-8',
'table-name' = 'city_flow', -- 需要手动到数据库中创建表
'username' = 'root',
'password' = '123456'
)
-- 3、在数据库中创建表
CREATE TABLE `city_flow` (
`city_code` varchar(255) NOT NULL,
`flow` bigint(20) DEFAULT NULL,
PRIMARY KEY (`city_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 4、统计数据的sql
insert into city_flow
select
city_code,
count(distinct car) as flow
from
cars
group by city_code

 浙公网安备 33010602011771号
浙公网安备 33010602011771号