自己来实现一个简易的OCR
来做个简易的字符识别 ,既然是简易的 那么我们就不能用任何的第三方库 。啥谷歌的 tesseract-ocr, opencv 之类的 那些玩意是叼 至少图像处理 机器视觉这类课题对我这种高中没毕业的人来说是一座高山 对于大多数程序员都应该算难度不小吧。 但是我们这里 这么简陋的功能 还用那些玩意 作为一个程序员的自我修养 你还玩个球。管他代码写得咋个low 效率咋个低 被高手嗤之以鼻也好 其实那些高手也就那样 把你的代码走起来 ,这是一件很好玩的事情。 以前一直觉着这玩意挺神奇 什么OCR optical character Recognition 高大上,这三个单词一直记不住 。好了正题:
二值化和对象分割
拿到图像 首先二值化 就是用一种无脑的方式把浅色的背景去掉变成纯白色,书上都是说二值化 这样说感觉是要叼一些 专业一些 那么我也这样说了。图像上的像素数据都是一堆无意义的离散的数据。那么第一步就是要把这些离散的像素数据组织成有逻辑的 数据 也就是对象分割了,一块整的图片 把他分割成一个个的字符 小图片。 网上看到别人用投影直方图的方式 这样做可以很容易 分割一行排的字符。 但是我原来还想做一个简易的“数细胞”的算法 干脆就一并实现了吧 正好这里也可以用得上 ,数细胞明白否 就是一副白纸上 一坨 一坨的 每一坨的形状都不一样 我们要用程序判断它总共有多少坨 只要是连在一起 哪怕是一根细线连着的 都算一坨。 当然也可以分割开 涉及到形态学 啥的 这里面太深奥了 暂时我还没准备深入研究 。 基于他的原理你们也知道了 不能判断小写字母i 这样的 因为一点加一竖 的方式 。这也是为啥那些成熟的OCR软件里都容易把扫描文本里比较粗糙有毛边的i 识别成 1 加 ' 。 好 我们就用这种方式 只是为了演示原理 我们这里也只准备进行数字识别, 正好数字0~9 每一个字符也都是连着的。
我们还是用我原来的巡路用过的算法 扩散大法 ,书面叫广度搜索 本来在原来是用来进行路径联通测试的,说明这玩意的用处还挺多的 威力无穷啊。 就这样随便从黑坨里取一个像素 作为种子 就像一滴水一样 让他去扩散 污染整个池塘。什么时候返回 也很简单 当触角不能再延伸了 自然就返回了。 污染后把整个池塘删除 放到 逻辑数据集里去 ,然后又从所有黑色像素里取一个种子像素 如此往复就把这一堆离散的像素点变得有意义了,我们一个个的字符也分割出来了 并且还有个好处 单个字符的每个像素点我们都知晓 进而可以计算字符的像素面积 ,这就可以把小的噪点过滤掉 然后 还可以定位每个字符的位置 宽 高。上面的做法效率是很低的 尤其字符面积过大 ,其实正统的做法应该是使用边缘查找,边缘查找的原理: 假设从上下左右有四堵墙往中间推 把遇到的所有第一个黑色像素 确定为边缘。 然后找一个像素 八方向查找 依次连城一个路径 直到找到起始点 则连成一个完整的闭塞区域,当然这个东西也不是那么简单的 比如遇到238这样的 ,任何东西运行都要有严密而行得通的理论支持。
对象分割的部分核心代码:
1 public Bitmap objSegmentation() 2 { 3 if (stu > Status.readyToTransform) 4 return sourceImg; 5 else if (stu == Status.waitSourceImg) 6 return null; 7 8 if (sourceImg == null) 9 return null; 10 11 bool Over = false; 12 while (Over == false) 13 { 14 //取得一个种子像素 15 node pxs = null; 16 foreach (var item in blackPixs) 17 { 18 if (item.accessed == false) 19 { 20 pxs = item; 21 break; 22 } 23 } 24 25 //根据种子像素找出被污染的区域 并把对应的位置设置为已访问 26 //设置第一个节点 27 startPoint = new Point(pxs.x, pxs.y); 28 zouguo = new Dictionary<int, List<node>>(); 29 int qibu = 0; 30 List<node> stepOne = new List<node>(); 31 stepOne.Add(new node() { parent = startPoint, current = startPoint }); 32 zouguo.Add(qibu, stepOne); 33 qibu++; 34 35 //进行广度搜索 直到搜索完一片区域为止 36 bool isgogogo = false; 37 do 38 { 39 isgogogo = besideOf(qibu - 1); 40 qibu++; 41 //if (qibu > 10) 42 // break; 43 } while (isgogogo); 44 45 //遍历当前被腐蚀的那一片区域 46 //并把所有节点添加到一个线性数组里去 47 48 int top = height - 1; 49 int bottom = 0; 50 int left = cols - 1; 51 int right = 0; 52 53 RegionOfObj bedestory = new RegionOfObj(); 54 bedestory.pixs = new List<Point>(); 55 foreach (var item in zouguo.Values) 56 { 57 foreach (var item2 in item) 58 { 59 bedestory.pixs.Add(item2.current); 60 //找出黑色像素里已经被腐蚀过的 把标示设置为已访问 61 for (int i = 0; i < blackPixs.Count; i++) 62 { 63 if (item2.current.X == blackPixs[i].x && item2.current.Y == blackPixs[i].y) 64 { 65 blackPixs[i].accessed = true; 66 if (blackPixs[i].x > right) 67 right = blackPixs[i].x; 68 if (blackPixs[i].x < left) 69 left = blackPixs[i].x; 70 if (blackPixs[i].y < top) 71 top = blackPixs[i].y; 72 if (blackPixs[i].y > bottom) 73 bottom = blackPixs[i].y; 74 } 75 } 76 } 77 } 78 79 Rectangle rec = new Rectangle(left, top, right - left + 1, bottom - top + 1); 80 81 82 bedestory.rect = rec; 83 //往最终呈现数据里加入结果 84 groupedObj.Add(bedestory); 85 86 //直到黑色像素所有的区域都被访问 就退出 87 Over = true; 88 foreach (var item in blackPixs) 89 { 90 if (item.accessed == false) 91 { 92 Over = false; 93 break; 94 } 95 } 96 //break; 97 } 98 99 100 stu = Status.readyToRecognition; 101 return sourceImg; 102 }
模板匹配
然后就是进行识别了 网上随便一找 都知道是用 模板匹配的方式,翻了两本书 也都是说的用这种方式。要说的话这确实没啥技术含量 挺简单的,就是简单的像素比对 差异化的像素占总像素比过大则认为不匹配 。 我们也不是无脑的拿固定大小的模板图片去比对 既然我们字符都分割定位了 宽高都知道,首先 我们的模板字符是比较大 比较清晰的 然后缩放到分割字符的大小 然后才进行像素比对。
模板匹配部分核心代码:
1 public string recognition() 2 { 3 if (stu == Status.waitSourceImg) 4 return ""; 5 else if (stu > Status.readyToRecognition) 6 return recognition_result; 7 else if (stu == Status.readyToTransform) 8 objSegmentation(); 9 10 11 //如果没有模板文件 则生成他 12 if (File.Exists("0.png") == false || File.Exists("1.png") == false || File.Exists("2.png") == false || 13 File.Exists("3.png") == false || File.Exists("4.png") == false || File.Exists("5.png") == false || 14 File.Exists("6.png") == false || File.Exists("7.png") == false || File.Exists("8.png") == false || 15 File.Exists("9.png") == false) 16 createTempleFile(); 17 18 19 //载入模板 20 Image[] templateImg = new Image[10]{ 21 Image.FromFile("0.png"),Image.FromFile("1.png"),Image.FromFile("2.png"),Image.FromFile("3.png"),Image.FromFile("4.png"), 22 Image.FromFile("5.png"),Image.FromFile("6.png"),Image.FromFile("7.png"),Image.FromFile("8.png"),Image.FromFile("9.png")}; 23 24 GraphicsUnit uu = GraphicsUnit.Pixel; 25 string result = ""; 26 for (int i = 0; i < groupedObj.Count; i++)//遍历所有对象 27 { 28 float mach = 0.000f; 29 string chr_tmp = " "; 30 for (int j = 0; j < templateImg.Length; j++)//0-9每个字符进行比对 31 { 32 //处理等比例缩放 算了也不用等比例了。 33 Bitmap scaleImg = new Bitmap(groupedObj[i].rect.Width, groupedObj[i].rect.Height); 34 Graphics gph = Graphics.FromImage(scaleImg); 35 gph.Clear(Color.White); 36 gph.DrawImage(templateImg[j], scaleImg.GetBounds(ref uu), templateImg[j].GetBounds(ref uu), GraphicsUnit.Pixel); 37 38 float mach_tmp = 0; 39 for (int k = 0; k < scaleImg.Height; k++) 40 { 41 for (int l = 0; l < scaleImg.Width; l++) 42 { 43 Color tmp_cor = scaleImg.GetPixel(l, k); 44 Color trg_cor = sourceImg.GetPixel(groupedObj[i].rect.Location.X + l, groupedObj[i].rect.Location.Y + k); 45 if (tmp_cor.R == trg_cor.R && tmp_cor.G == trg_cor.G && tmp_cor.B == trg_cor.B)//如果像素匹配上 46 mach_tmp += 1; 47 } 48 } 49 if ((mach_tmp / (float)(groupedObj[i].rect.Width * groupedObj[i].rect.Height)) > mach) 50 { 51 mach = (mach_tmp / (float)(groupedObj[i].rect.Width * groupedObj[i].rect.Height)); 52 chr_tmp = j.ToString(); 53 } 54 } 55 if (mach < 0.6f) 56 result += "?"; 57 else 58 result += chr_tmp; 59 } 60 recognition_result = result; 61 stu = Status.complete; 62 return result; 63 }
本来准备把模板跟目标区域进行等比例缩放的,后来仔细一想算了这不是多事吗 并且这样还有一个好处 ,就是高度进行压缩了的字符也可以识别出来。 搞完了 看得出来 我们这个只算是最初级最初级的 只能够去识别那种解放前水平的验证码。现在的验证码也不是那么好识别的 做验证码的人只要大概了解识别原理 都可以给识别的人制造成倍的难度 ,对于现在的有些验证码 即使是高手 做自动识别都不是那么容易的。
不要问我这可不可以用来识别身份证号 之类的 。我可以负责的告诉你 肯定是可以的 。身份证号识别那个本身难度就是比较低的。 首先身份证号 的位置 在整个身份证版面中 都是固定的 把那一块截取出来 进行处理就可以了 ,然后 身份证号所使用的字体叫 "OCR-B 10 BT" 我也不知道啥意思 意思是专利于进行OCR识别的字体?OCR-B: An isO recognized machine-readable typeface that is designed to be more legible to humans than OCR-A 这种字体电脑上是没有的 需要进行安装下 打开OCR-B 10 BT.ttf 点安装即可。 然后就可以进行识别了 。
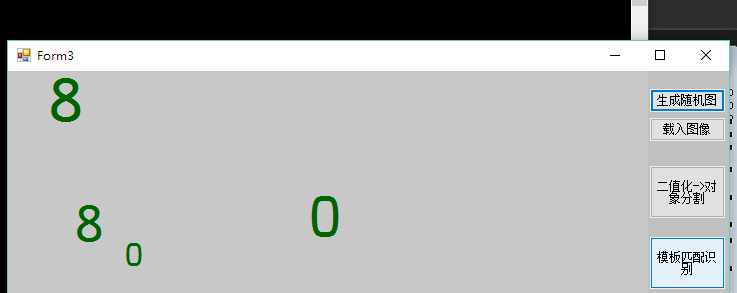
运行结果:




 浙公网安备 33010602011771号
浙公网安备 33010602011771号