FileBeat简单使用
简介
首先要了解ELK架构
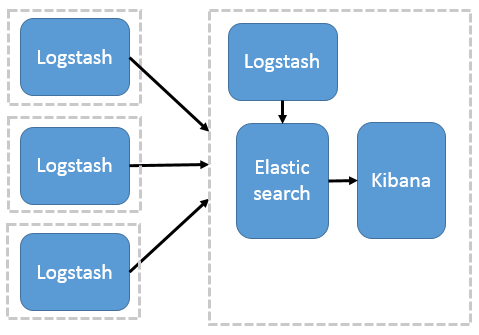
这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。
Beats 同样作为ELK Stack的新成员,包含

Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户
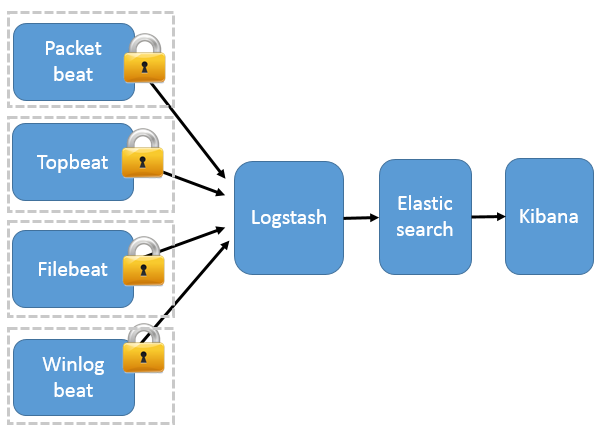
这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。
filebeat是一个轻量级日志收集器,有多轻量?和logstatsh一比的话就很轻量了
首先logstatsh是使用java编写的,所以跑起来需要占用jvm资源,默认的堆大小就是1g
而filebeat是使用go语言写的,占用的资源比logstatsh少的多

官网的原话
使用
其实需要我们配置的地方就是收集日志的策略,在filebeat.yml里有很多日志策略的配置
比如说你只要收集info或者error的日志,或者合并某段日志
因为不指定合并日志的策略,filebeat会一行一行的显示在kibana上,但是比如说一些sql的日志就是占几行的
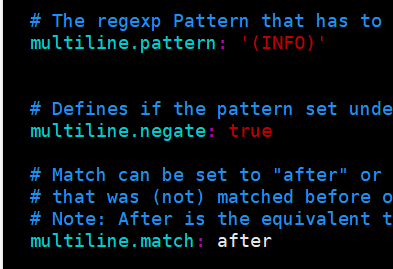
我这里的需求就很简单,日志全部收集,需要合并日志,只要通过配置multiline这个配置
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
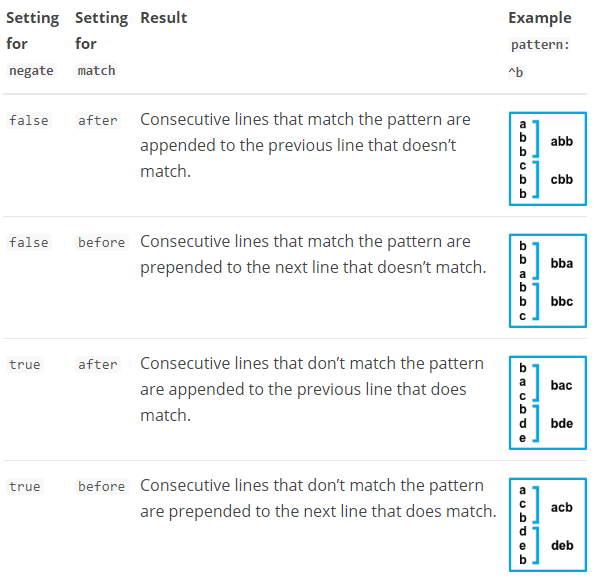
根据你配置其他多行选项的方式,与指定正则表达式匹配的行将被视为上一行的延续或新多行事件的开始。 你可以设置 negate 选项以否定模式。
multiline.pattern 匹配的正则
multiline.match after 或 before,合并到上一行的末尾或开头
multiline.negate 默认是false,匹配pattern的行合并到上一行;true,不匹配pattern的行合并到上一行
效果
实战
日志格式
配置
收集info的日志
原理
示例图

实现
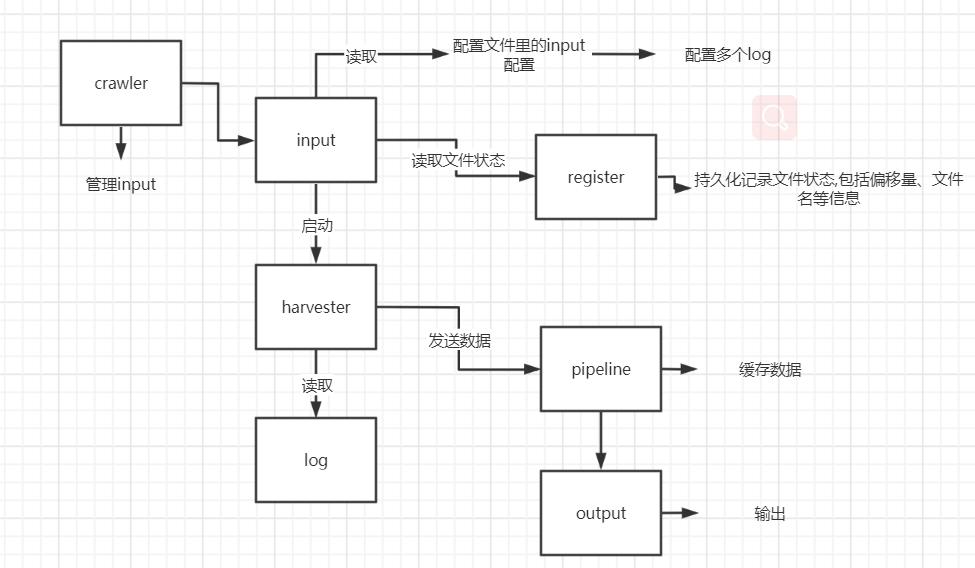
整个 filebeat 主要包含以下重要组件:
- Crawler:负责管理和启动各个 Input
- Input:负责管理和解析输入源的信息,以及为每个文件启动 Harvester。可由配置文件指定输入源信息。
- Harvester: Harvester 负责读取一个文件的信息。
- Pipeline: 负责管理缓存、Harvester 的信息写入以及 Output 的消费等,是 Filebeat 最核心的组件。
- Output: 输出源,可由配置文件指定输出源信息。
- Registrar:管理记录每个文件处理状态,包括偏移量、文件名等信息。当 Filebeat 启动时,会从 Registrar 恢复文件处理状态。
filebeat 的整个生命周期,几个组件共同协作,完成了日志从采集到上报的整个过程。
关于如何保证日志文件的正确性,input里有两个重要的状态offset和finished
- offset: 代表文件当前读取的 offset,从 Registrar 中初始化。Harvest 读取文件后,会同时修改 offset。
- finished: 代表该文件对应的 Harvester 是否已经结束,Harvester 开始时置为 false,结束时置为 True。
对于每次定时扫描到的文件,概括来说,会有三种大的情况:
- Input 找不到该文件状态的记录, 说明是新增文件,则开启一个 Harvester,从头开始解析该文件
- 如果可以找到文件状态,且 finished 等于 false。这个说明已经有了一个 Harvester 在处理了,这种情况直接忽略就好了。
- 如果可以找到文件状态,且 finished 等于 true。说明之前有 Harvester 处理过,但已经处理结束了。
除此之外,一个比较有意思的点是,Filebeat 甚至可以处理文件名修改的问题。即使一个日志的文件名被修改过,Filebeat 重启后,也能找到该文件,从上次读过的地方继读。
这是因为 Filebeat 除了在 Registrar 存储了文件名,还存储了文件的唯一标识。对于 Linux 来说,这个文件的唯一标识就是该文件的 inode ID + device ID。
本文来自博客园,作者:阿弱,转载请注明原文链接:https://www.cnblogs.com/aruo/p/17486396.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号