
首先回顾一下前面介绍的机器学习,这里就放一个简单的思维导图的截图在这了哈...

下面正式开始介绍线性回归。
一、线性模型
从机器学习的分类来看,线性回归属于监督学习。其目的是根据给定的特征数据找到一条可以拟合这些数据的直线,即找到一个从特征空间X到输出空间Y的最优的线性映射函数。用模型的数学表达式表示如下:
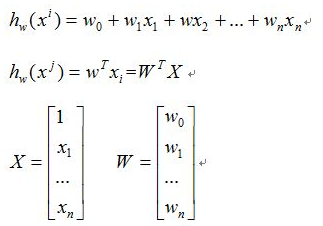
二、损失函数
这里就面临求解模型的参数的问题。通常求解模型参数是通过损失函数来计算的。何为损失函数呢?损失函数是用来衡量模型的预测值与真实值的不一致程度。它是非负的实值函数,通常损失函数越小,模型的鲁棒性就越好。
常用的损失函数有以下这些:
1、平方损失函数(最小二乘法OLS)
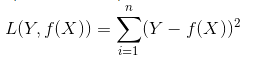
2、log损失
L(Y,P(Y|X)) = -logP(Y|X)
3、指数损失(主要用于Adaboost集成算法中的损失函数)
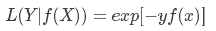
4、Hinge损失
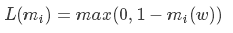
5、0-1损失

6、绝对值损失

通常线性回归采用的损失函数是平方损失函数。此时求解参数的方法叫做最小二乘法。
结合线性回归的模型,我们可以给出其损失函数如下:
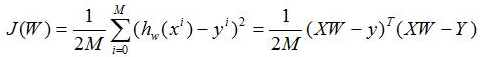
现在我们的目的就是求解出一个使得上面J(W)最小的参数W。
当矩阵X'X满秩时,可以通过线性代数中的求逆得到参数结果,令导数为零解出参数:
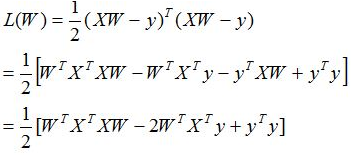 (1)
(1)
式(1)对W求导可得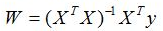
当矩阵不满秩时,此时存在多个解都能使得均方误差最小化,此时运用梯度下降法来求解参数,优化损失函数:
梯度下降算法是一种求局部最优解的方法,其原理可以概括为:将函数比作一座山,我们站在某个山坡上,往四周看,从哪个方向向下走一小步,能够下降的最快。利用梯度下降法求解参数时尤其需要注意的一点是:当变量之间相差很大时,应该先将变量进行归一化处理,这样既保证了梯度下降的速度,也保证了准确性。
梯度减少的具体过程如下:
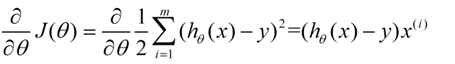
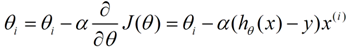
对于线性回归,用向量表示为:h = XW,其中X,W分别如下:
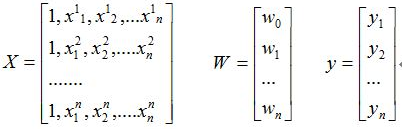
则,对损失函数求偏导结果如下:
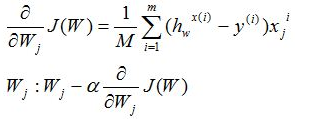
用矩阵表示为:
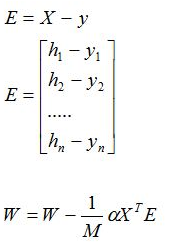
三、线性回归的正则化
1、LASS(L1正则化)
L1正则化就是在代价函数的后面加一个正则化项,此时目标函数为:
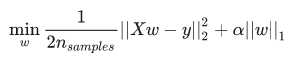 ,其中的参数alpha用于控制估计的系数的稀疏程度。L1正则化通过引入该惩罚项,能减少不重要的参数,用于特征选择,防止模型过拟合。
,其中的参数alpha用于控制估计的系数的稀疏程度。L1正则化通过引入该惩罚项,能减少不重要的参数,用于特征选择,防止模型过拟合。
2、Ridge(L2正则化)
L2和L1类似,只是假如的惩罚项的形式不同而已。加入L2正则化后的目标函数变为:
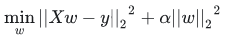 ,其中的参数alpha用于控制参数收缩量的复杂性,该值越大,收缩量越大,因此系数对共线性越稳健,L2正则化能够解决多重共线性问题。
,其中的参数alpha用于控制参数收缩量的复杂性,该值越大,收缩量越大,因此系数对共线性越稳健,L2正则化能够解决多重共线性问题。
3、Elastic正则化
它是L1和L2正则化技术的混合体,这种组合允许学习稀疏模型,其中很少权重像Lasso一样非零,同时仍然保持Ridge的正则化特性。此时的目标函数形式为:

四、线性回归的评估指标
从统计学角度看,一个线性回归模型的好坏的评价可以采用以下方法:
1、MSE(均方差): ,该值越接近0,模型的拟合效果越好
,该值越接近0,模型的拟合效果越好
1、拟合优度R2:通常R2越大,模型拟合效果越好。计算公式为:R2=SSR/SST,其中SSR,SST计算分别如下:
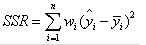

参考:https://blog.csdn.net/jay463261929/article/details/60748509
https://www.cnblogs.com/llhthinker/p/5399827.html
https://www.cnblogs.com/kuotian/p/6151541.html
https://blog.csdn.net/yitianguxingjian/article/details/69666447

 浙公网安备 33010602011771号
浙公网安备 33010602011771号